






1,论文相关信息

AdaptFormer: Adapting Vision Transformers for Scalable Visual Recognition 原文链接
Accepted by NeurIPS 2022
2,动机
将预训练模型vision transformers适配到不同的视觉识别下游任务中
3,方法
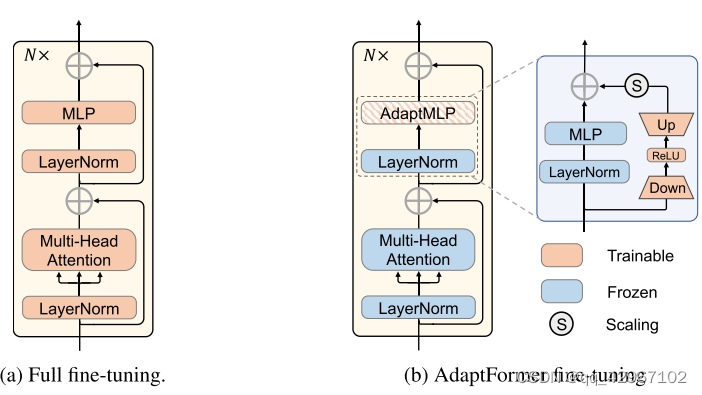
Down和Up相当于两个Linear,不是很明白有效的原因在哪里,这篇论文的思想就是如何将大规模预训练Vit模型用于下游任务,而不用全量微调参数,所以这篇论文微调的点在于对MLP做了改进。
- 正文没有看见明显的论证
- 下游的实验比较多,除了图像分类,还有Video domain
- 给出的结果比VPT好














 1013
1013











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









