







微调不到0.2%就超越现有微调方法?港大等提出即插即用的轻量级模块AdaptFormer![]() https://mp.weixin.qq.com/s/v5OUKK2jZdm63SwP192yKQ
https://mp.weixin.qq.com/s/v5OUKK2jZdm63SwP192yKQ
AdaptFormer: Adapting Vision Transformers for Scalable Visual Recognition
论文: https://arxiv.org/abs/2205.13535
代码: https://github.com/ShoufaChen/AdaptFormer
Introduction
尽管经过预训练的视觉Transformer(ViT)在计算机视觉方面取得了巨大成功,但将ViT适应各种图像和视频任务仍具有挑战性,因为ViT的计算和存储负担很重,每个模型都需要独立地微调以适应不同的任务,从而限制了其在不同领域的可迁移性。为了应对这一挑战,作者提出了一种有效的Transformer自适应方法,即AdaptFormer,它可以将预训练好的VIT有效地适应许多不同的图像和视频任务。
它具有比现有技术相比的几个优点:
首先,AdaptFormer引入了轻量级模块,只向ViT添加了不到2%的额外参数,而它能够在不更新其原始预训练参数的情况下增加ViT的可迁移性,在动作识别基准上显著优于现有的完全微调的模型。
其次,它可以在不同的Transformer中即插即用,并可扩展到许多视觉任务。
第三,在五个图像和视频数据集上进行的大量实验表明,AdaptFormer在很大程度上改善了目标域中的ViTs。例如,当只更新1.5%的额外参数时,与Something-Something v2和HMDB51上的完全优化模型相比,它分别实现了约10%和19%的相对改进。
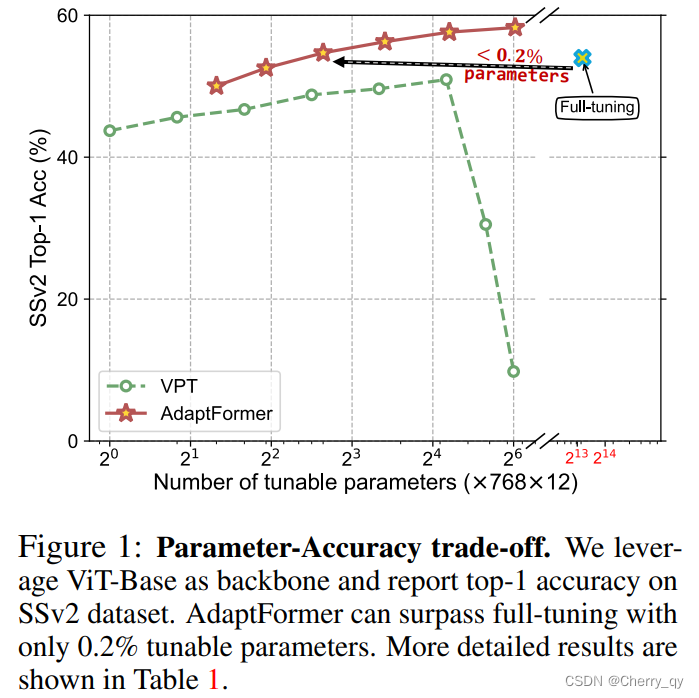
如上图所示,相比于完全微调整个模型,只微调0.1%参数的AdaptFormer达到了相似的性能。同时,AdaptFormer的可调参数不到2%时,在top-1精度上就超过了完全微调解决方案。
Architecture

图a:传统Transformer block
图b:adaptformer
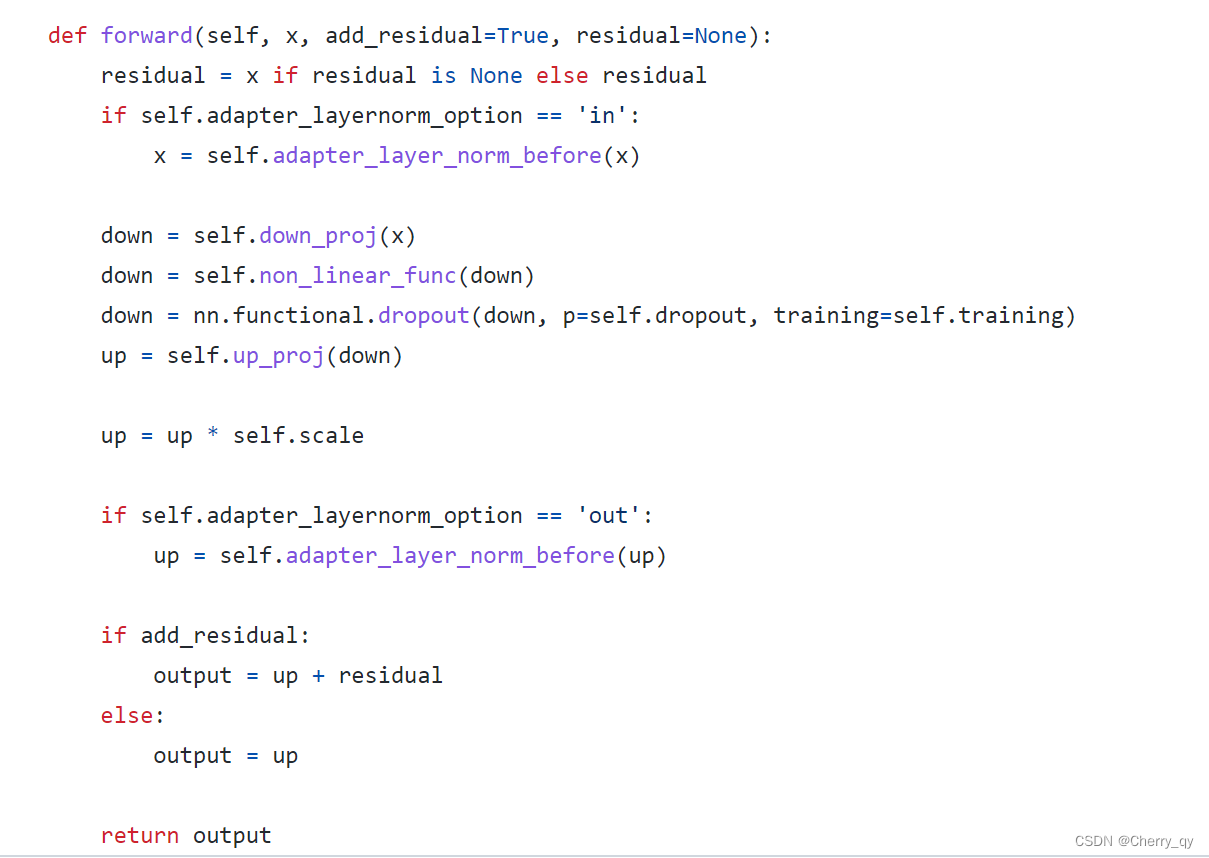
用AdaptMLP代替MLP块。AdaptMLP由两个子分支组成。
左分支中的MLP层与原始网络相同。
右分支是另外引入的用于任务特定优化的轻量级模块,设计为瓶颈结构,用于限制参数量。
![]()

在微调阶段,原始模型部件(图b中的蓝色块)从预训练的checkpoint加载权重,并保持不变,避免下游任务之间的交互。新添加的参数(橙色块)在特定数据域上随任务特定损失进行更新。
在微调后,作者保持共享参数固定,并额外加载前一阶段微调的额外参数的权重。在引入的轻量级模块的帮助下,单个整体模型能够适应多个任务。
Discussion
Tunable parameters analysis
本文的AdaptMLP模块是轻量级的。瓶颈结构的中间通道数很小,因此新引入的参数量很少。因此当添加更多的下游任务时,总模型大小的增长几乎可以忽略。
Applicability
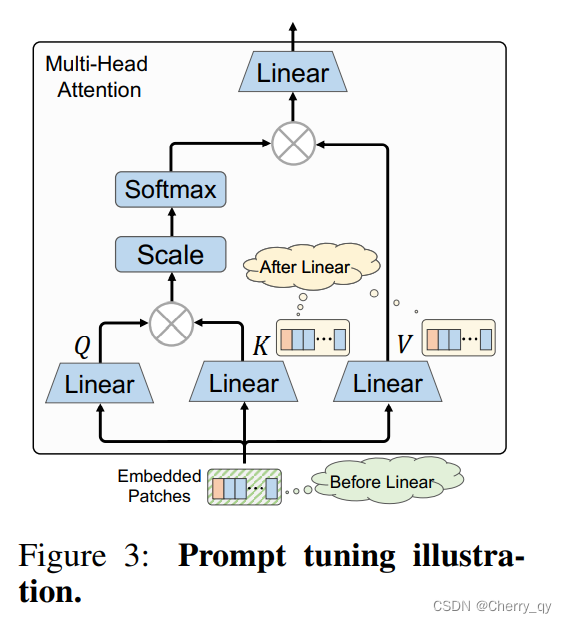
AdaptMLP是一个即插即用模块,可以自适应地插入现有流行的vision transformer架构中。
因为即使不同的ViT可能在MHSA架构中有所不同,但所有主干网络都有相同的MLP层。
与本文的方法相比,最近的prompt相关方法将可训练参数插入到token空间中,如上图所示。
他们在线性投影之前将可学习的参数预先添加到嵌入的token中,
或者在线性投影之后将可学习的参数添加到key and value token中【VPT】。
因此,prompt相关方法不能直接适用于特殊MHSA变体。
此外,根据实验结果,当patch token的数量从图像到视频规模增长时,prompt相关方法的性能不佳。
实验设置
预训练backbone:
使用ViT作为backbone,利用监督训练和自监督训练两种方式对模型进行预训练。
对于image,使用ImageNet-21k监督训练的预训练模型,以及MAE自监督训练模型。对于video,使用VideoMAE监督训练和自监督训练的模型。
AdaptFormer的初始化:
对于原始模型,直接load上游任务中预训练的权重,在微调过程中保持预训练权重frozen。对于新添加的模块,down映射层用Kaiming Normal初始化,其余的部分用零初始化。
Baseline methods:
将AdaptFormer与其他三个常用的微调方法进行比较。
(1)linear probing:将pretrain model作为特征提取器,后面添加一个额外的线性层,只有线性层的参数会更新。
(2)Full Fine-tuning:将所有的参数都设为可学习
(3)VPT:将可学习的参数添加到key and value token中,微调添加的额外参数
下游任务:
image:CIFAR-100 SVHN Food-101
video:SSv2 HMDB51
Experiment
作者将不同微调方法的性能与通过监督训练和自监督预训练的主干进行比较。结果表明,AdaptFormer始终优于linear probing和Visual Prompt tuning(VPT)方法。


如下图4所示,作者在SSv2和HMDB-51数据集上进行了可调参数实验。可以看出,相比于VPT方法,本文的方法在两个数据集上都能达到更高的性能。
通过监测训练阶段的测试精度,作者进一步研究了VPT的优化过程。如图5所示,作者逐渐增加VPT中的token数量,并绘制每个epoch的Top-1精度。当token数小于或等于4时,训练阶段是稳定的,例如{1,2,4}。然而,当数字变为8或更大时,例如{8,16,32},训练过程在大约第十个epoch时崩溃,在训练阶段结束时表现不佳。

消融实验
表a:中间维度控制了AdaptFormer引入参数的数量。小的中间维度引入的参数较少,可能会带来性能损失。作者在中间特征维度上进行消融来研究这种影响。如表a所示,当中间尺寸增加到64时,精度持续提高,当中间尺寸约为64时,精度达到饱和点。
表b:AdaptFormer的性能与添加的层数呈正相关。此外,当引入相同数量的层时,AdapterFormer更喜欢网络的顶部(远离输入图像的部分)而不是底部。
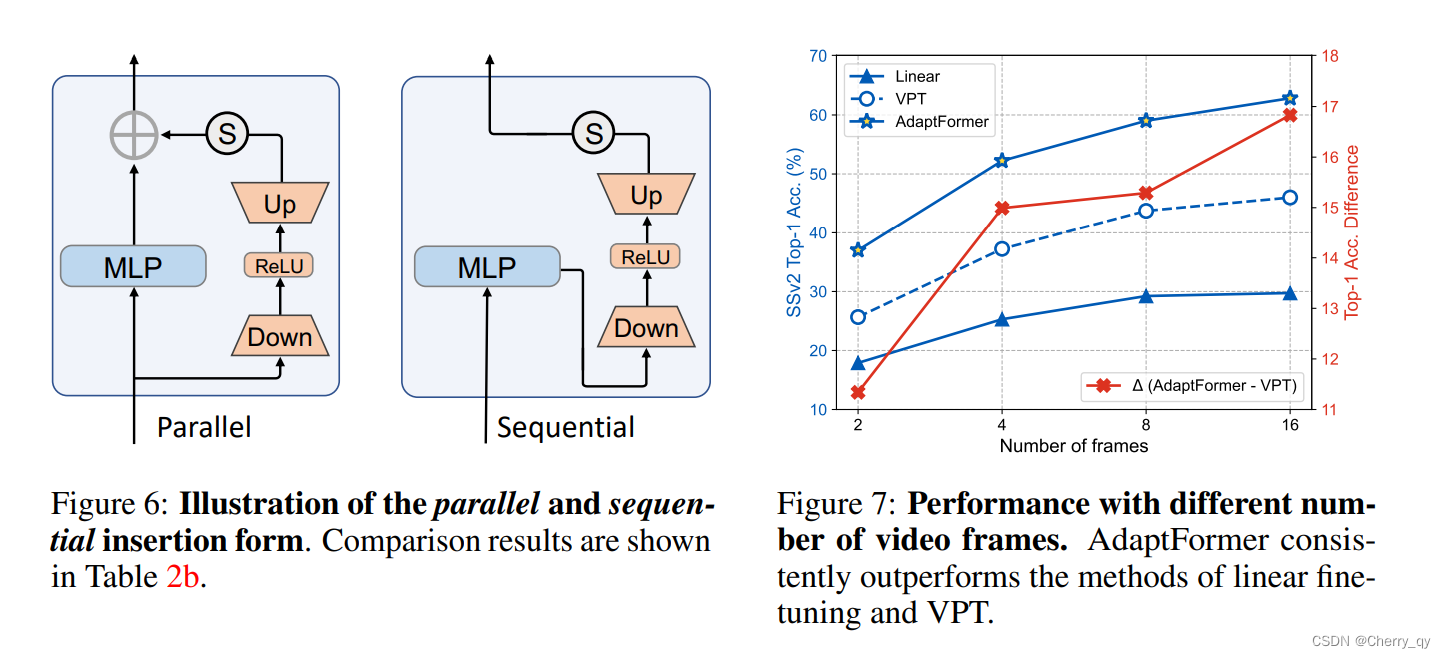
图6:比较并行和串行实例来研究插入方法。并行AdaptFormer比串行AdaptFormer的精度高出0.85%。
图7:对于普通ViT,嵌入patch token的数量随着视频帧的数量线性增加。作者使用不同数量的帧进行了实验,即{2,4,8},结果如上图所示。作者观察到,增加帧数对所有这三种微调方法都是有益的。然而,AdaptFormer始终优于线性方式和VPT方法。

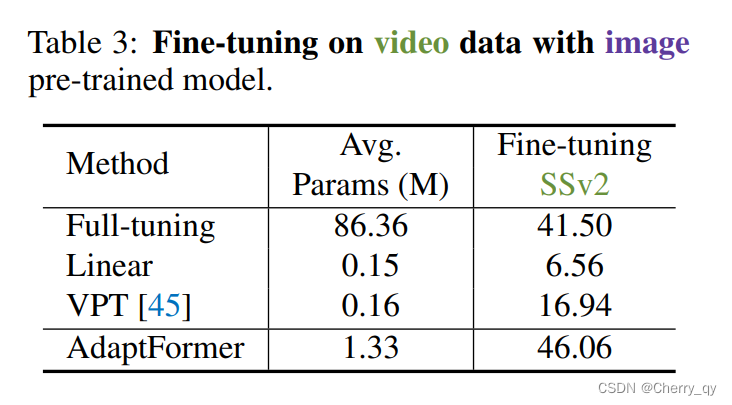
作者使用在ImagNet-21k上预训练的模型在SSv2和HMDB-51上进行动作识别。如表3所示,AdaptFormer对模态引起的域迁移具有鲁棒性。
Conclusion
本文提出了一个概念简单但有效的框架AdaptFormer,用于有效地将预训练的视觉Transformer(ViT)主干迁移到可伸缩的视觉识别任务。通过引入AdaptMLP,本文的AdaptFormer能够调整轻量级模块,以生成适应多个下游任务的特征。在五个数据集(包括图像和视频域)上进行的大量实验验证了本文提出的方法能够以较小的计算成本提高ViT的可迁移性。
















 419
419











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









