







Motivation
ViTs 在视觉识别领域取得了巨大成功,后续需要使 ViT 适应各种图像和视频识别任务。由于计算量大、存储空间大,自适应具有一定的挑战性。每个模型都需要一个独立而完整的微调过程来适应不同的任务,这限制了它在不同视觉域的可迁移性。为了解决这一挑战,提出了一种有效的 Transformer 自适应方法,即 AdaptFormer,它可以有效地将预训练的 ViTs 适应于许多不同的图像和视频任务,具有比现有技术更吸引人的几个好处。首先,AdaptFormer 引入了轻量级模块,仅向 ViT 添加不到2%的额外参数,同时能够在不更新其原始预训练参数的情况下增加 ViT 的可迁移性,其次,它可以在不同的 ViT 中即插即用,扩展到许多视觉任务。
现有的 CV 方法倾向于关注具有任务特定权重的同一场景,即使用单个网络对特定数据集进行从头开始训练或完全微调,当任务数量增加时,为每个数据集保持单独的模型权重是不可行的,特别是对于大模型其容量不断增加 (ViT-G/14 超过18亿参数)。
Contributions
- 提出了一个简单而有效的框架 AdaptFormer,用于适应各种下游视觉识别任务,并避免彼此之间的干扰
- 消除了许多设计选择,并证明了 AdaptFormer 在参数增多时具有优越的鲁棒性
- 各种下游任务上的大量实验表明,AdaptFormer 显著优于现有的微调方法。希望我们的工作可以激发研究界重新思考计算机视觉中的微调机制,并朝着灵活而通用的视觉识别模型努力
Method
提出一个即插即用的 Bottle 模块,即 AdaptMLP,配备其的 ViT 表示为AdaptFormer。
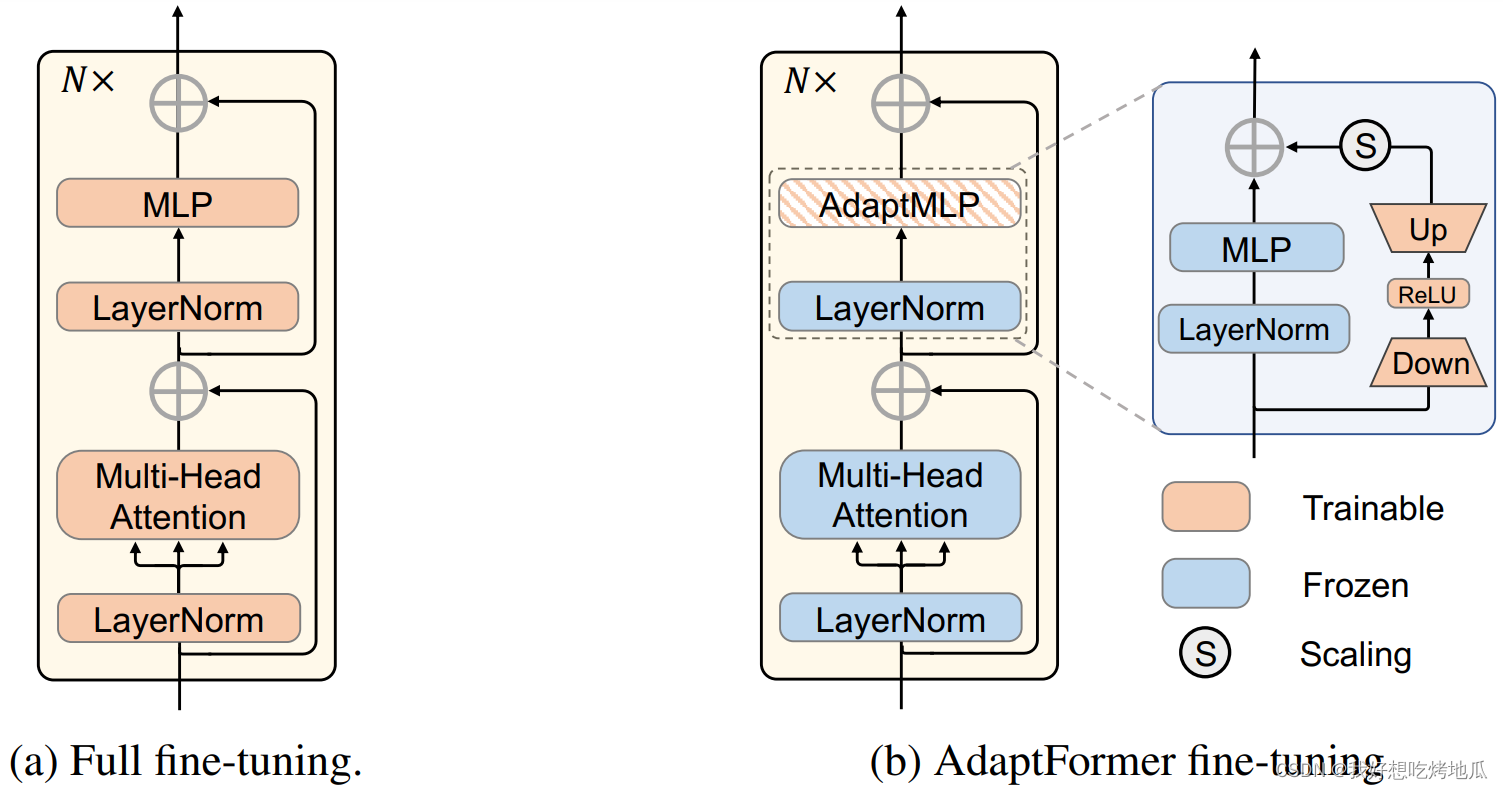
Architecture
AdaptFormer 的设计原理简单而有效,与普通的完全微调机制相比,AdaptFormer 用 AdaptMLP 替换了 ViT 编码器中的 MLP 块,由两个子分支组成。左分支中的 MLP 层与原始网络相同,而右分支是额外引入的轻量级模块,用于特定任务的微调。其中,右分支被设计为限制参数数量的瓶颈结构,该结构包括下投影层和上投影层。由于这些投影层之间具有非线性特性,之间还有一个 ReLU 层。该瓶颈模块通过比例因子残差连接连接到原始 MLP网络 (左分支)。
Fine-tuning
在微调阶段,只选择新增加的参数进行优化,其余参数保持不变。具体来说,原始模型部分 (蓝色块) 从预训练加载权重,并保持参数冻结。新添加的参数 (橙色块) 在具有特定任务损失的数据域更新。
Inference
在微调之后,将共享参数冻结,额外加载在前一阶段微调的参数的权重。在引入的轻量级模块的帮助下,单个模型能够适应多个任务。














 369
369











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









