







 本文探讨了工业设备故障诊断的关键性,尤其是旋转机械设备。通过建立数据集并运用深度学习算法,如LDA、PCA、MLP、LSTM和CNN,提高设备故障分类的准确率。尽管当前技术存在不足,但深度学习有望改善这一状况,为故障诊断带来更精确的解决方案。
本文探讨了工业设备故障诊断的关键性,尤其是旋转机械设备。通过建立数据集并运用深度学习算法,如LDA、PCA、MLP、LSTM和CNN,提高设备故障分类的准确率。尽管当前技术存在不足,但深度学习有望改善这一状况,为故障诊断带来更精确的解决方案。
摘要
故障诊断分类技术在工业上已经被广泛的使用,在工业设备维护起到了关键性作用,但是自动故障诊断分类技术目前还存在不足,要求精确地对设备机械进行自动诊断,准确地分析出设备故障产生的原因,从而确定故障发生的部位。针对工业上旋转机械设备的特殊性和复杂性,引入了深度学习算法来提高设备故障分类的准确率。首先对旋转机械设备建立数据集,通过深度学习算法对数据进行特征提取,由多个网络层迭代学习设备故障特征,最终优化深度学习算法模型输出不同设备故障类型,提高系统分类的准确率。本文还对故障诊断分类等技术进行总结与分析,然后重点分析了深度学习故障诊断技术在工业上机械旋转类的应用;最后提出了现有深度学习故障诊断分类技术研发方法的不足,希望深度学习领域在故障诊断技术有很好的发展。
本篇针对实际数据分别采用传统的机器学习与深度学习进行分类。设计的算法包括LDA,PCA,MLP,LSTM,CNN.希望能对大家带来帮助。
导入需要的包
import os
import numpy as np
import torch
from sklearn.decomposition import PCA
from sklearn.discriminant_analysis import LinearDiscriminantAnalysis as LDA
from sklearn.preprocessing import StandardScaler,MinMaxScaler
from sklearn import svm
import matplotlib.pyplot as plt
from datetime import datetime
获取数据
def get_data():
train_data1 = []
test_data1 = []
for i in range(22):
fi = os.path.join("data/",("d0" if i < 10 else "d") + str(i) + "_te.dat")
with open(fi,'r') as f:
data = f.read()
data = np.fromstring(data,dtype=np.float32,sep=" ")
data = data.reshape(-1,52)
data = data[160:]
train_data1.append(data) # -train
for i in range(0,22):
fi = os.path.join("data/",("d0" if i < 10 else "d") + str(i) + ".dat")
with open(fi,'r') as f:
data = f.read()
data = np.fromstring(data,dtype=np.float32,sep=" ")
if fi == "data/d00.dat":
data = data.reshape(-1,500).T
else:
data = data.reshape(-1,52)
test_data1.append(data) # -test
return train_data1,test_data1
target,train_data1,test_data1 = [],[],[]
def train_test_get(dataset = target,train_data1=train_data1):
seq_data = []
seq_labels = []
for i,t in enumerate(dataset):
d = train_data1[t]
data = []
length = d.shape[0] - 2
for j in range(3):
data.append(d[j:j+length])
data = np.hstack(data)
seq_data.append(data)
seq_labels.append(np.ones(data.shape[0],np.int64)*i)
return np.vstack(seq_data),np.concatenate(seq_labels)
train_data1,test_data1 = get_data()# 1-_te.dat 2-.dat
target = [1,2,3,4,5,6,7,8,9]
train_data1,test_data1 = get_data()
train_data,train_labels = train_test_get(target,train_data1)
test_data,test_labels = train_test_get(target,test_data1)
print("训练数据train_data.shape:%s,train_labels.shape:%s" %(train_data.shape,train_labels.shape))
print("训练数据train_data.shape:{},train_labels.shape:{}" .format(train_data.shape,train_labels.shape))
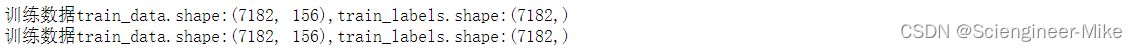
LDA-线性判别方法
scaler = StandardScaler().fit(train_data)
train_data1 = scaler.transform(train_data)
test_data1 = scaler.transform(test_data)
model_lda = LDA(n_components=30).fit(train_data1,train_labels)
train_data1_ = model_lda.transform(train_data1)
test_data1_ = model_lda.transform(test_data1)
clf = svm.SVC(probability=True).fit(train_data1_,train_labels)
pred = clf.predict(test_data1_)
print("accuracy:{:0.3f}".format 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章
















 500
500











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









