










Article
文献题目:TEMPORAL LINK PREDICTION VIA REINFORCEMENT LEARNING
文献时间:2021
摘要
- 带有时间戳的大量事件数据的可用性引起了对动态知识图(KGs)的研究。 在动态知识图谱中,时间链接预测是一项重要任务,它预测实体之间的未来交互。 与传统的统计链接预测任务相比,时间链接预测面临三个主要挑战:i)如何处理我们以前没有观察到的新实体。 ii) 如何对时间进化模式进行建模。 iii) 如何在不重新训练模型的情况下适应 KG 的变化。 为了应对这些挑战,我们提出了一种新颖的强化学习方法,该方法具有更新机制来整合时间信息。 为了预测未来事件,我们训练了一个时间感知代理来导航以输入查询为条件的图以找到预测路径。 实验结果表明,与最先进的方法相比有明显的改进。
引言
- 知识图谱 (KG) 在许多实际应用中自然出现,用于对实体之间的成对交互进行建模 [1, 2, 3]。 传统上,知识图谱被认为是多关系数据的静态快照。 然而,随着时间的推移,大多数 KG 会随着关系和实体的添加、删除和更改而不断发展。 KG 的演化过程比静态快照包含更多的信息。 尽管许多 KG 包含时间信息 [4,5,6],但大多数研究都集中在静态 KG 上,因此在很大程度上忽略了时间信息。
- 静态 KG 以三元组形式 ( s , r , o ) (s, r, o) (s,r,o)存储事实,这意味着实体 s s s 与实体 o o o 具有关系 r r r。 为了将静态 KG 扩充为动态 KG,我们将每个事实与时间戳 t t t 相关联,即 ( s , r , o , t ) (s, r, o, t) (s,r,o,t)。 在特定时刻预测实体之间的交互很重要。 此任务称为时间链接预测,可以在两种设置下部署:插值和外插。 给定一个包含时间间隔 [ t 0 , t T ] [t_0, t_T] [t0,tT] 的事实的 KG,插值是在时间 t ∈ [ t 0 , t T ] t ∈ [t_0, t_T] t∈[t0,tT] 时进行预测,而外插是在时间 t > t T t > t_T t>tT 时进行预测。
- 我们尝试解决外推问题,因为它在实际应用中具有更大的价值。 这个问题有三个主要挑战:i)如何处理看不见的实体。 动态 KG 会随着时间的推移而发展,因此新实体会不断出现。 但大多数现有模型本质上是可转换的,不能推广到看不见的实体。 ii) 如何对时间进化模式进行建模。 新事实的产生受到历史事实的影响。 对时间进化模式进行建模对于准确预测未来事实至关重要。 iii) 如何在不重新训练模型的情况下适应 KG 的变化。 通常,最近的事实比早期的事实对未来事件的影响更大[7]。 然而,大多数现有模型不能利用训练过程之后发生的事实来预测未来,因此它们的性能会迅速下降。
- 在本文中,我们提出了一种基于强化学习 (RL) 的时间链接预测模型。我们训练一个时间感知代理 (TAgent),通过搜索提供答案的关系路径来预测未来的事实,这些路径是要预测的事实背后的原因。例如,TAgent 可以预测中国将在 07-22 与韩国签署正式协议,因为韩国在 07-21 表示有意与中国合作。给定一个查询 ( s , r , ? , t ) (s, r, ?, t) (s,r,?,t) 和一个包含 t t t 之前的事实的动态 KG,TAgent 从实体 s s s 开始,并学习步行到与 s s s 具有关系 r r r 的实体。为了处理看不见的实体,我们将搜索策略设置为依赖关系路径的语义而不是实体的特征。为了捕捉时间进化模式,我们根据时间信息使用新的门机制过滤候选动作的嵌入。为了在不重新训练的情况下适应不断发展的 KG 的变化,我们在训练后保持 TAgent 的策略稳定,并更新 TAgent 已知的 KG。当新的事实出现时,我们将这些事实添加到 KG 中,以便 TAgent 可以沿着这些新添加的关系路径搜索答案。
- 据我们所知,我们是第一个将强化学习用于时间链接预测的人。 我们在三个数据集上评估 TAgent。 我们的实验结果表明与最先进的方法相比有了明显的改进。
相关工作
- 对静态链接预测任务进行了广泛的研究。 一些方法,如 TransE [8]、DistMult [9]、ComplEx [10] 和 SimplE [11],学习实体和关系的低维表示,并构建一个评分函数来评估事实。 还提出了基于强化学习的方法,例如 DeepPath [12] 和 MINERVA [13]。 他们通过训练代理根据实体和关系的嵌入在 KG 上行走来推断新的关系。 然而,它们都无法捕获时间信息。
- 最近有一些对动态 KG 建模的尝试。 一些学习每个时间戳的表示 [14, 15, 16]。 因此,这些模型无法预测带有未知时间戳的未来事实。 Garc´ıa-Dur´an [17] 使用 RNN 对带有关系的时间戳进行编码。 该方法可以与现有的基于嵌入的方法结合使用(将其与 TransE 结合将产生 TA-TransE)。 RE-Net [18] 由一个事件序列编码器组成,用于捕获时间信息和一个邻域聚合模块,用于在同一时间戳对实体邻域信息进行编码。 然而,所有这些模型都不能处理看不见的实体。
任务和模型
- 令 E E E 表示一组实体, R R R 表示一组关系, T T T 表示一组时间戳,我们使用 G = { E , R , T } G = \{E, R, T\} G={E,R,T} 表示动态 KG。 G G G用一个4元组 ( s , r , o , t ) (s, r, o, t) (s,r,o,t)存储一个事实,其中 s , o ∈ E s, o ∈ E s,o∈E表示主语实体和宾语实体, r ∈ R r ∈ R r∈R表示它们之间的关系,并且 t ∈ T t ∈ T t∈T 表示事实发生的时间。 我们将时间链接预测视为查询回答任务。 为了预测未来特定时间会发生什么,我们根据 t t t 之前的已知事实回答查询 ( s , r , ? , t ) (s, r, ?, t) (s,r,?,t)。 查询回答任务被表述为一个有限范围的顺序决策问题:我们首先将环境表示为 G G G 上的确定性部分观察马尔可夫决策过程 (POMDP)。TAgent 从 G G G 中 s s s 对应的顶点开始,按照其策略遵循 G G G 中的关系路径,并停在它认为是查询正确答案的实体处。
环境
- 环境是一个有限范围的确定性 POMDP。 我们使用一个 5 元组 < S , O , A , P , R > < S, O, A,P, R > <S,O,A,P,R> 来表示 POMDP,其中 S S S 是状态空间, O O O 是观察函数, A A A 是可用动作的集合, P : S × A → S P : S × A → S P:S×A→S 是转移函数, R R R 是奖励函数。 在序列决策过程中有几个步骤。 我们使用 e n e_n en 来表示 TAgent 在步骤 n n n 访问的实体。
- 状态。 实体和关系自然是离散的符号。 我们用 e n e_n en 和答案 o q o_q oq 对查询 ( s q , r q , ? , t q ) (s_q, r_q, ?, t_q) (sq,rq,?,tq) 进行编码。 因此,TAgent 的整体状态 S ∈ S S ∈ S S∈S 表示为 S = ( s q , e n , r q , o q , t q ) ∈ E × E × R × E × T S = (s_q, e_n, r_q, o_q, t_q) ∈ E × E × R × E × T S=(sq,en,rq,oq,tq)∈E×E×R×E×T 。
- 观察。 TAgent 无法观察环境的整体状态。 直观地说,当查询和当前位置对 TAgent 可见时,答案仍然是隐藏的。 形式上,状态上的观察函数定义为 O ( ( s q , e n , r q , o q , t q ) ) = ( s q , e n , r q , t q ) O((s_q, e_n, r_q, o_q, t_q)) = (s_q, e_n, r_q, t_q) O((sq,en,rq,oq,tq))=(sq,en,rq,tq)。
- 行动。 给定 ( s q , e n , r q , t q ) (s_q, e_n, r_q, t_q) (sq,en,rq,tq), A e n A_{e_n} Aen, t q t_q tq 由 G G G 中时间戳在 t q t_q tq 之前的实体 e n e_n en 的所有输出事实组成。TAgent 在 KG 上搜索固定数量的步骤 N N N。为了处理不同长度的关系路径,我们添加了一个新的关系,从每个实体到自身,时间戳设置为当前时间。 因此,TAgent 可以在实体上停留任意数量的步骤,这在 TAgent 在步骤 n < N n < N n<N 达到正确答案时特别有用。形式上, A e n , t q = { ( e n , r , e , t ) ∈ G ∣ t < t q } ∪ { ( e n , s t a y , e n , t q ) } A_{e_n,t_q} = \{ (e_n, r, e, t) ∈ G| t < t_q\} ∪ \{ (e_n, stay, e_n, t_q)\} Aen,tq={(en,r,e,t)∈G∣t<tq}∪{(en,stay,en,tq)}。
- 过渡。 给定一个选定的动作,环境会确定性地转移。 当前位置被转换为另一个实体,而查询和答案保持不变。 形式上,转移函数定义为 P ( S n + 1 = s ′ ∣ S n = s , A n = a ) = 1 P(S_{n+1} = s' |S_n = s, A_n = a) = 1 P(Sn+1=s′∣Sn=s,An=a)=1 其中 s ′ = ( s q , e n + 1 , r q , o q , t q ) s' = (s_q, e_{n+1}, r_q, o_q, t_q) s′=(sq,en+1,rq,oq,tq), s = ( s q , e n , r q , o q , t q ) s = (s_q, e_n, r_q, o_q, t_q) s=(sq,en,rq,oq,tq) 和 a = ( e n , r , e n + 1 , t ) a = (e_n, r, e_{n+1}, t) a=(en,r,en+1,t)。
- 奖励。 我们只关心 TAgent 是否可以在导航结束时学习到正确答案的策略。 最终状态为 ( s q , e N , r q , o q , t q ) (s_q, e_N , r_q, o_q, t_q) (sq,eN,rq,oq,tq),如果 e N = o q e_N = o_q eN=oq,则终端奖励为 +1,否则,终端奖励为 -1。
策略网络
-
为了解决上述有限范围确定性 POMDP,我们设计了一个历史相关策略 π π π。 在每一步,TAgent 根据历史状态和当前观察选择适当的动作。 我们的策略网络概览如图 1 所示。

-
第 n n n 步的历史状态记为 h n h_n hn,它取决于 h n − 1 h_{n-1} hn−1 和第 n n n 步的动作(记为 a n a_n an)。 我们使用门控循环单元 (GRU) [19] 根据 TAgent 选择的动作更新历史嵌入。
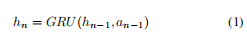
-
现在我们说明如何从可用动作集中编码和选择动作。为了处理看不见的实体,TAgent 使用关系路径的语义而不是实体的特征来做出决定。 TAgent 为 R R R 中的所有关系学习一个嵌入矩阵 R R R,其中 R r R_r Rr 是关系 r r r 的嵌入。不同时间戳的相同关系对当前预测有不同的影响。因此,我们根据动作的关系和时间戳对动作进行编码。我们使用 a n i {a_n}^i ani 来表示第 i i i 个候选动作 ( e n , r i , o i , t i ) (e_n, r_i, o_i, t_i) (en,ri,oi,ti) 的嵌入, a n i = f ( R r i , t i ) {a_n}^i = f(R_{r_i}, t_i) ani=f(Rri,ti)。我们不关注时间戳的绝对值。相反,我们认为事实之间的时间差(表示为 Δ t Δ_t Δt,其中 Δ t i = t q − t i Δ_{t_i} = t_q−t_i Δti=tq−ti)包含更多关于时间进化模式的信息。因此,我们的策略可以推广到看不见的时间戳。每个事实的发生都会对后续事实的发生产生特定的影响。这种影响通常随着时间的推移以特定的模式演变。
-
我们设计了一种新颖的门机制来根据时间差过滤关系的语义。 我们首先使用线性层将 Δ t Δ_t Δt 转换为时间上下文向量 w w w,即 w = W t Δ t w = W_tΔ_t w=WtΔt。 在关系的嵌入空间中,每个维度代表一个影响后续事实的特征。 一些维度所代表的特征的影响随着时间的推移而逐渐增加,而其他维度则逐渐减小。 我们使用 1 + t a n h ( w ) 1 + tanh(w) 1+tanh(w) 作为过滤器来处理动作的嵌入,从而学习不同特征维度的信号演化模式。 1 + t a n h ( w ) ∈ [ 0 , 2 ] 1 + tanh(w) ∈ [0, 2] 1+tanh(w)∈[0,2] 中每个维度的值。 当特征值接近 2 时影响逐渐增大,而当特征值接近 1 时影响保持稳定,当特征值接近 0 时影响逐渐减小。形式上,事实 a = f ( R r , t ) a = f(R_r, t) a=f(Rr,t) 的动作嵌入由等式 2 编码。
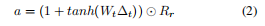
-
基于历史嵌入 h t h_t ht 和动作嵌入 { a n i } \{{a_n}^i\} {ani},TAgent 根据其策略做出选择动作的决定。 我们使用查询 R q R_q Rq 中关系的嵌入作为查询 ( s q , r q , ? , t q ) (s_q, r_q, ?, t_q) (sq,rq,?,tq) 的嵌入。 在每一步,我们首先让 TAgent 在当前位置进行探索,尝试向前推进所有可用的操作并获取时间历史嵌入 { h n + 1 i } \{{h_{n+1}}^i\} {hn+1i}。 形式上,在第 n n n 步,我们使用等式 1 得到 h n + 1 i = G R U ( h n , a n i ) {h_{n+1}}^i = GRU(h_n, {a_n}^i) hn+1i=GRU(hn,ani)。 我们通过堆叠 { h n + 1 i } \{{h_{n+1}}^i\} {hn+1i} 获得 H n + 1 H_{n+1} Hn+1。 然后我们将查询嵌入 R q R_q Rq 和历史嵌入 H n + 1 H_{n+1} Hn+1 转换为具有两个不同矩阵 W q W_q Wq 和 W h W_h Wh 的 d d d 维向量。 之后,我们将 tanh 应用于这些向量并使用内积计算所有可能动作的概率分布。 我们根据概率分布对一个动作进行采样,得到最终动作。 第 n + 1 n + 1 n+1 步的历史嵌入对应于所选动作 a n i {a_n}^i ani。 换一种说法,
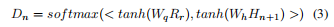
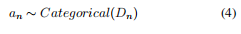
训练和测试
- 对于上述策略网络
π
θ
π_θ
πθ,我们希望找到最大化预期奖励的参数
θ
θ
θ:
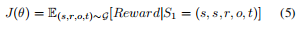
- 在训练期间,我们使用 REINFORCE [20] 来解决这个优化问题。 在测试期间,我们进行波束搜索并根据 TAgent 到达实体的轨迹概率对实体进行排名。 为了在不重新训练模型的情况下适应 KG 的变化,我们保持策略 π θ π_θ πθ 稳定,但只用新的事实改变可用的动作集 A A A。
实验
实验设置
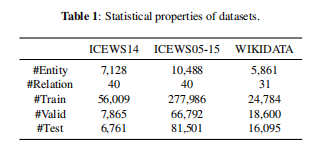
- 我们使用三个数据集进行实验。 综合危机预警系统 (ICEWS) [5] 是一个存储库,其中包含具有特定时间戳的政治事件。 我们使用此存储库的两个版本:ICEWS14 和 ICEWS05-15。 我们还使用在 [17] 中提取的 WIKIDATA [21] 数据集。 对于每个数据集,我们组装所有事实,然后按时间戳划分数据集。 因此,(训练次数)<(有效次数)<(测试次数)。 表 1 总结了所有数据集的统计数据。
- 我们将我们的方法与静态模型 TransE、Dist Mult、SimplE 和 MINERVA 以及动态模型 TA-TransE、TA-DistMult 和 RE-NET 进行比较。 通过忽略时间戳,静态模型可以处理时间链接预测任务。 在所有比较的方法中,只有 TAgent 和 RE-Net 可以适应 KG 的变化而无需重新训练。 在测试期间,给定查询 ( s , r , ? , t ) (s, r, ?, t) (s,r,?,t),我们在有效数据和测试数据中使用时间在 t t t 之前的事实来更新 KG,而无需重新训练。 我们报告平均倒数排名 (MRR) 和 Hits@1/3/10,使用原始版本来评估模型。
实验结果
- 表 2 中的实验结果表明,TAgent 在所有评估指标上均显着且始终优于所有基线方法。

- ICEWS 中的实体相对稳定,这意味着在测试过程中几乎没有看不见的实体。因此,ICEWS 上的实验结果显示了模型对实体的转导学习能力。 MINERVA 在所有静态模型中表现最好,尤其是在远程数据集 ICEWS05-15 上,这证明了现有关系路径与待预测交互之间存在关联和因果关系的假设。可以看出,时间模型并不总是优于静态模型,即 TA TransE 和 TA-DistMult 并不优于 TransE 和 Dist Mult。时间信息在时间链接预测任务中至关重要。但是,如果信息使用不当,可能会导致过度拟合和性能下降。我们使用差异而不是绝对值来模拟时间信息,以便我们可以学习可概括的时间进化模式。 TAgent 和 RE-NET 的性能明显优于其他模型,因为它们无需重新训练即可适应 KG 的演变,这证明使用最新事实来预测未来事件非常重要。
- WIKIDATA 中出现的实体总是在变化,这意味着在测试过程中有很多看不见的实体。 WIKIDATA 上的结果显示了模型的归纳学习能力。所有依赖实体嵌入的方法都表现不佳。它们本质上是可转换的,不能推广到看不见的实体。令人惊讶的是,MINERVA 几乎没有对 WIKI DATA 做出任何有效的预测。我们认为这是因为 ICEWS 中的政治事件在同一实体之间反复发生,因此即使忽略时间信息,MINERVA 也可以隐式学习一些知识。但是 WIKI DATA 没有类似的现象,所以不考虑时间信息就无法学习到有效的策略。我们的模型在 WIKIDATA 上实现了令人满意的性能。 TAgent 基于关系路径而不是实体的特征在图上搜索。只要事实之间的因果关系和相关模式保持不变,TAgent 就可以准确地预测未来事件。
消融研究
- 为了验证 TAgent 中每个部分的贡献,我们对 ICEWS05-15 进行了消融研究。 结果在表3中。
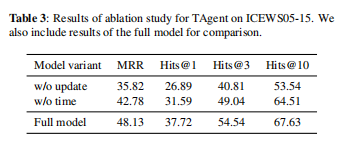
- 我们使用 w/o time 来表示没有时间信息的模型。 结果表明,使用门机制过滤候选动作的嵌入与时间信息显着有助于最终结果。 每个事实的发生都会对随后的事实产生特定的影响。 没有时间信息,TAgent 无法区分在不同时间出现的具有相同关系的事实。 我们使用 w/o update 来表示模型,在训练后不更新 KG。 结果表明,向 KG 中添加事实对于做出准确的预测至关重要。 通常,具有较早世代时间的事实对实体当前行为的影响较小,而具有较晚世代时间的事实具有更显着的影响。 因此,如果我们不适应 KG 的变化,我们就会丢失最有用的信息。 事实之间的因果关系和相关性模式是稳定的,而涉及的实体会随着时间而变化。
结论
- 在本文中,我们提出了一种基于强化学习的模型 TAgent 来处理时间链接预测任务。 我们提出了一种具有更新机制的新型策略网络来整合时间信息,以便 TAgent 可以学习时间演化模式。 此外,我们提出了一种更新机制,使 TAgent 无需重新训练即可适应 KG 的变化。 实验结果表明对现有模型的实质性改进。















 6109
6109











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









