









论文地址:https://arxiv.org/pdf/1803.08904.pdf
Github:https://github.com/zhanghang1989/PyTorch-Encoding
问题提出
最近语义分割网络使用基于多分辨率金字塔来扩大感受野,如PSPSNet中的Spatial Pyramid Pooling和Deeplab中的Atrous Spatial Pyramid Pooling。虽然这些方法可以提升性能,但是上下文地表达不明确,导致了一个问题:增加感受野就等同于整合了上下文信息了吗?
论文收录在CVPR2018,本文提出的EncNet网络引入了上下文编码模块(Context Encoding Module)来捕获全局上下文信息和突出与场景相关联的类别信息,这相当于加入场景的先验知识,类似于attention机制。
实验证明上下文编码模块能够显著的提升语义分割性能,在Pascal-Context上达到了51.7%mIoU, 在 PASCAL VOC 2012上达到了85.9% mIoU,单模型在ADE20K测试集上达到了0.5567。 此外,论文进一步讨论上下文编码模块在相对浅层的网络中提升特征表示的能力,在CIFAR-10数据集上基于14层的网络达到了3.45%的错误率,和比这个多10倍的层网络有相当的表现。
1、利用编码层捕获特征数据作为全局语义信息。
2、在encoder-decoder结构最深层处加入context encoding module。
3、SE-loss计算全图分类误差。
网络结构

实现细节
1、在预训练网络的 stage 3 和 stage 4 采用 dilation 策略,输出尺寸(output size )为输入的 1/8. 采用双线性插值(bilinear interpolation)上采样 8x,得到输出预测,以计算 loss。
2、学习率策略为“poly”策略,即:
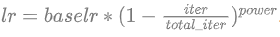 ADE20K的base_lr=0.01,其他的为0.001。power=0.9。
ADE20K的base_lr=0.01,其他的为0.001。power=0.9。
3、训练时,随机打乱训练样本,并丢弃最后一个 mini-batch,ADE20K上迭代120epochs,其他的迭代50epochs。
4、数据增强,随机翻转图片,在[0.5, 2]区间缩放图片,随机旋转图片 [-10, 10] 度,最后裁剪图片为固定尺寸(zero padding)。
5、测试时,多尺度预测结果求平均。
















 522
522











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











