









-
本文是ICCV2019的语义分割领域的文章,旨在解决long-range dependencies问题,提出了基于十字交叉注意力机制(Criss-Cross Attention)的模块,利用更少的内存,只需要11x less GPU内存,并且相比non-local block更高的计算效率,减少了85%的FLOPs。最后,该模型在Cityscaoes测试集达到了81.4%mIOU,在ADE20K验证集达到了45.22%mIOU。
网络结构
- 上面是文章提出的CCNet结构。输入图像经过深度卷积神经网络(DCNN)传递,生成特征图X。
获得特征图X之后,首先应用卷积层以获得降维的特征图H,然后将特征图H放入十字交叉注意力模块(CCA)模块并生成新的特征图H‘,这些特征图H’汇聚长距离的上下文信息并且每个像素以十字交叉的方式进行同步。 - 特征图H‘仅在水平和垂直方向上聚合上下文信息,这对于语义分割而言还不够。 为了获得更丰富和更密集的上下文信息,我们将特征图H’再次输入到交叉注意模块中,然后输出特征图H‘’。 因此,特征图H‘’中的每个位置实际上收集了来自所有像素的信息。 前后两个纵横交错的注意模块共享相同的参数,以避免添加过多的额外参数。 此递归结构命名为递归纵横交叉注意(RCCA)模块。
- 将密集的上下文特征H‘’与特征图X通过Concat操作堆叠起来。紧接着是一层或数个具有批量归一化和激活以进行特征融合的卷积层。 最后,将融合的特征输入进分割层以生成最终的分割图。
PSPNet中提出PPM结构来捕获上下文信息,在PPM模块中采用不同的kernel size对输入的feature map作池化,然后upsampling到统一的size。在每个池化分支,由于kernel size是固定的,只能对每个pixel都考虑其周围固定大小的上下文信息,显然,不同的pixel需要考虑的上下文信息是不同的,因此说这种方法是非自适应的。
为了生成密集的,逐像素的上下文信息,Non-local Networks使用自注意力机制来使得特征图中的任意位置都能感知所有位置的特征信息,从而生成更有效的逐像素特征表达。如图1所示,特征图的每个位置都通过self-adaptively predicted attention maps与其他位置相关联,因此生成更丰富的特征表达。但是,这种方法是时间和空间复杂度都为O((HxW)x(HxW)),H和W代表特征图的宽和高。由于语义分割中特征图的分辨率都很大,因此这种方法需要消耗巨大的计算复杂度和占用大量的GPU内存。有改进方法吗?

作者发现non-local操作可以被两个连续的criss-cross操作代替,对于每个pixel,一个criss-cross操作只与特征图中(H+W-1)个位置连接,而不是所有位置。这激发了作者提出criss-cross attention module来从水平和竖直方向聚合long-range上下文信息。通过两个连续的criss-cross attention module,使得每个pixel都可以聚合所有pixels的特征信息,并且将时间和空间复杂度由O((HxW)x(HxW))降低到O((HxW)x(H+W-1))。
具体地说,non-local module和criss-cross attention module都输入一个HxW的feature map来分别生成attention maps(上面的分支)和adapted feature maps(下面的分支)。然后采用加权和为聚合方式。在criss-cross attention module中,feature map中的每个position(蓝色方格)通过预测的稀疏attention map与其所在同一行和同一列的其他positions相连,这里的attention map只有H+W-1个权重而不是non-local中的HxW,如图2。进一步地,提出了recurrent criss-cross attention module来捕获所有pixels的长依赖关系,并且所有的criss-cross attention module都共享参数以便减少参数量。
Criss-Cross Attention模块

- 如图所示,局部特征H∈RC×W×H,criss-cross注意模块首先在H上应用两个具有1×1 filters的卷积层,分别生成两个特征图Q和K,其中{Q,K}∈RC’×W×H。C’是特征图的通道数,由于尺寸缩减,C‘小于C。在获得特征图Q和K之后,我们通过Affinity运算进一步生成注意力图A∈R(H + W-1)×W×H。 在特征图Q的空间维度上的每个位置u,我们都可以得到向量Qu∈R C’。 同理,我们可以通过从K中提取特征向量来获得集合Ωu,K是与u处于同一行或同一列。因此,Ωu∈R(H + W-1)×C‘,Ωi,u∈R C’是Ωu的第i个元素。
- Affinity运算的定义如下:
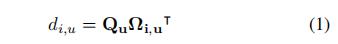
其中di,u∈D表示特征Qu与Ωi,u的相关程度,i = [1,…,|Ωu|],D∈R(H + W-1)×W× H。 然后,我们沿着channel维度在D上应用softmax层,以计算注意力图A。 - 然后在H上应用另一个具有1×1 filters的卷积层以生成V∈R C×W×H以进行特征自适应。 在特征图V的空间维度上的每个位置u,我们都可以获得向量Vu∈RC和集合Φu∈R(H + W-1)×C。 集合Φu是V中的特征向量的集合,这些特征向量位于位置为u的同一行或同一列中。 远程上下文信息由Aggregation操作收集:
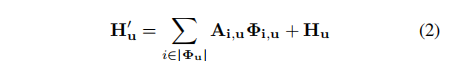
其中H’u表示输出特征图H’∈R C×W×H在位置u处的特征向量。 Ai,u是通道i和位置u处的标量值。将上下文信息添加到局部特征H中以增强局部特征并增强按像素表示。 因此,它具有广阔的上下文视图,并根据空间注意力图选择性地聚合上下文。
实验结果
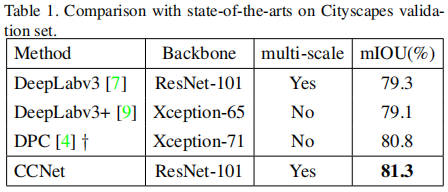
在Cityscapes数据集上的效果:

这篇文章的解读很有独到之处:https://blog.csdn.net/pangyunsheng/article/details/89069749
















 7665
7665











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











