









文献阅读:Rich feature hierarchies for accurate object detection and semantic segmentation,Tech report(v5)(2014)
作者:Ross Girshick,Jeff Donahue,Trevor Darrell,Jitendra Malik
阅读原因:了解RCNN、Fast RCNN、Faster RCNN在object detection中的应用
Fast RCNN学习笔记
主要参考:①R-CNN读书笔记 ②关于Faster R-CNN的一切——笔记1:R-CNN ③【目标检测】RCNN算法详解
文章目录
摘要
-
Region CNN(R-CNN)可以说是利用深度学习进行目标检测的开山之作。作者Ross Girshick多次在PASCAL VOC的目标检测竞赛中折桂,2010年更带领团队获得终身成就奖。这篇文章思路简洁,在DPM方法多年平台期后,效果提高显著。
-
RCNN是一种可伸缩的(scalable)检测算法,在PASCAL VOC2012数据集上将mean average precision(mAP)提高了30%,达到53.3%。下面是mAP的计算过程,其中AP为average precision,即平均精确度。

\qquad 计算mAP时,一般先计算每个预测框的loU值(预测框与真实框的交集面积与并集面积之比),通过与loU阈值比较得到“正确预测”或“错误预测”。计算第i个图像的第C类的精度:
P r e c i s i o n i , C = C 类 别 的 正 确 预 测 次 数 C 类 别 的 总 数 量 Precision_{i,C}=\frac{C类别的正确预测次数}{C类别的总数量} Precisioni,C=C类别的总数量C类别的正确预测次数
再计算平均精度AP:
A P C = ∑ i P r e c i s i o n i , C 图 像 总 数 AP_C=\frac{\sum_iPrecision_{i,C}}{图像总数} APC=图像总数∑iPrecisioni,C
进而再对AP取平均,就得到mAP值。
m A P = 1 ∣ Q R ∣ ∑ q ∈ Q R A P q mAP=\frac{1}{|Q_R|}\sum_{q\in Q_R}AP_q mAP=∣QR∣1q∈QR∑APq -
RCNN有两个优点:
(1)可以将high-capacity CNN应用于候选区域(region proposals),从而实现目标的局部化和分割(Regions with CNN,R-CNN)。
(2)当有标签的training data缺乏时,先在辅助任务进行有监督预训练,再在自己的数据集上做微调,这样可以提高模型性能。 -
RCNN的不足:
(1)测试时速度慢:对于提取的Region Proposal,多数都是互相重叠的,重叠部分会被多次重复提取特征,都要分别进行CNN前向传播一次(相当于进行了2000次提特征和SVM分类的过程),操作冗余,计算量较大。
(2)训练时速度慢:原因同上。
(3)多阶段训练过程:每一步需要训练三个模型:CNN、SVM、bounding box回归,且RCNN中独立的分类器和回归器都需要大量特征作为训练样本。
介绍
1. 回顾
- 过去的图像识别主要基于SIFT和HOG,但在PASCAL VOC目标检测任务中进展缓慢。
- SIFT和HOG都是块取向(blockwise orientation)的直方图,可以粗略代表灵长类动物视觉路径中皮层区域V1中的细胞。但同时,我们也需要分层的、多阶段的过程来计算特征。
- Fukushima的 “neocognitron” 是用来解决模式识别的一个分层的、具有转移不变形的模型,是对分层过程的一次尝试,但缺乏监督训练的算法。还有一类模型是对neocognitron的拓展,是通过反向传播算法,利用随机梯度下降法来训练CNN,这是有效的。
- 在SVM出现时,CNN曾沉寂过一段时间,但CNN在ImageNet图像分类任务中的出色表现又使人们对它重燃兴趣。
2. 思路
Q:在什么情况下,CNN在ImageNet分类的结果可以推广到PASCAL VOC目标检测问题?
A:本文通过建立图像分类和目标检测的关系,来回答这一问题。相较于简单的HOG,CNN可以得到好得多的目标检测结果。为得到这一结果,需要解决两个问题:
(1)利用深度网络将目标局部化
(2)只利用较少的带注释的检测数据来训练一个high-capacity模型
问题一:目标局部化——区域识别
- 经典的目标检测算法是使用滑窗法建立滑窗检测器,依次判断所有可能的区域,这样会使网络中的单元(units)数大幅上升,使得此网络有非常大的感受野(receptive fields)和步长(strides),速度很慢。
- 本文的方法是区域识别(recognition using regions):预先提取一系列较可能是object的候选区域,之后只在这些候选区域上提取特征,进行detection。
使用区域识别方法来解决CNN局部化问题,此方法在目标检测和语义分割(semantic segmentation)中的应用都很成功。同时,bounding-box回归(边框回归)方法可以很好的降低mislocalizations——此模型主要的error mode】。
问题二:labeled data缺乏——无监督预训练+有监督微调
- 经典的目标检测算法在区域中提取人工设定的特征(Haar,HOG)。
- 本文的方法需要训练深度网络进行特征提取。共有两个数据集:
识别库(ImageNet ILSVRC2012):标定每张图片中物体的类别。一千万图像,1000类。【没有物体的位置标注,unlabeled data】
检测库(PASCAL VOC2007):标定每张图片中物体的类别和位置。一万图像,20类。
先在识别库上进行预训练(等同于得到AlexNet),之后在检测库上进行fine-tuning调优参数。
本文的第二个贡献:展现了上述预训练+微调的方法是在labeled data缺乏的情况下,训练大容量CNN的有效方法。
[图像处理之特征提取(一)之HOG特征简单梳理][]
3. 模型的高效性
本文模型是高效的,唯一的计算是矩阵-向量乘积和贪婪非极大值抑制(greedy non-maximum suppression)。这些计算都与在所有类别中出现的特征有关,而且这些类别的维度比之前使用的区域特征小两个数量级。
- non-maximum suppression(NMS)是一种局部最大搜索方法,用于在目标检测任务中找出评分最高的窗口。因为得到的窗口会有很多包含或重叠的情况,所以用NMS选取评分最高的窗口,同时抑制评分低的窗口。
RCNN过程

↓ \downarrow ↓
↓ \downarrow ↓
↓ \downarrow ↓
1. 生成候选区域(region proposal)
- 为了避免盲目的滑窗,先提取若干候选区域。提取候选区域的算法很多,RCNN对提取候选区域的算法没有限定,论文里使用的是selective search,使得R-CNN与以前的检测方法可比。(具体参考What makes for effective detection proposals详细对比了各种region proposal的算法。)
- 本文生成了2k个region proposals,最终的检测结果就从这2k个中选择。
2. 用训练好的CNN提取每个proposal的特征
- 利用CNN从每个区域中提取固定长度特征向量。我们使用仿射图像扭曲(affine image warping) 将图像warp后输入CNN,通过向前传播方法计算固定长度的特征。
- 训练CNN网络使用的是AlexNet,去掉最后一层FC,使用倒数第二层FC的4096维输出作为特征向量。AlexNet要求输入图像是227 ∗ * ∗ 227大小,因此对输入的region proposal图像,需要将它变形到与CNN匹配的大小227 ∗ * ∗ 227,从而通过CNN提取出4096维的特征向量。(变形方法见附录A)
3. 用每个类别训练好的线性SVM对每个proposal中所有类别进行评分
- 每个类别对应一个二分类svm分类器,输入为CNN输出的4096维特征向量,输出为该region proposal输入该SVM对应类别的score。本文使用的PASCALvoc数据库有20个类别,所以有20个SVM。一幅图像最终输出2k*20的评分矩阵。
| 候选区域 \ 得分 \ 类别 | 1 | … | N=20 |
|---|---|---|---|
| 2k个proposals | scores | scores | scores |
- 受Deformable Part Models(DPM)的启发,在得到评分后,我们利用bounding-box回归预测一个新的边框。Bounding-box回归的作用是微调窗口 (见3.5节和附录C,或参考边框回归(Bounding Box Regression)详解)
【注】SVM分类器和bounding box回归器是相互独立的!
4. Greedy non-maximum suppression(NMS)
- 根据评分对该类的region proposal进行Greedy non-maximum suppression(NMS)筛选出最终的region。
- 对每一类(即评分矩阵的每一列),根据score对这些region进行排序,把score最大的bounding box(也就是region proposal)加入队列作为已被选择项,然后计算其他候选bounding box与队列中已经被选择了的bounding box的IoU(intersection-over-union),剔除IoU大于阈值的候选bounding box(IoU越大则越重叠),重复直到候选bounding box为空。这样就剩下了每一类符合要求的那些含有该类物体的bounding box。

Object detection with R-CNN
要点1:生成与类别独立的候选区域
文中使用selective search方法,算法如下:

\qquad
selective search算法是先通过简单的区域划分算法,将图片划分成很多小区域,再通过相似度和区域大小(小的区域先聚合,这样是防止大的区域不断的聚合小区域,导致层次关系不完全)不断的聚合相邻小区域,类似于聚类的思路。这样就能解决object层次问题。例如汽车是object,轮胎也是object,汽车包含轮胎,两个目标的层次是不同的。
\qquad 为了保证能够划分的完全,对于相似度,作者提出了可以多样化的思路,不但使用多样的颜色空间(RGB,Lab,HSV等等),还有很多不同的相似度计算方法。并类过程中的proposals都是算法的输出,选择评分高的作为selective search的结果,得到约2k个region proposals。参考选择性搜索(selective search)和Selective Search原理及实现(均附代码)
要点2:CNN从每个候选区域提取长度固定的特征向量
- 用CNN从每个候选区域中提取4096维的特征,用向前传播方法计算特征,CNN包括五个卷积层和两个全连接层。
- 在计算之前,先要将图像转变为227*227像素大小才能输入CNN。先将边框扩大,再对边框中的所有像素进行warp,使得warping之后,图像中精确有p个像素(文中p=16)。
要点3:每个类别对应的线性SVM
要点4:bounding box回归(附录C)

\qquad
bounding-box回归可以改善局部化效果。在DPM中,是用inferred DPM part location计算出的几何特征进行回归,而RCNN是用CNN计算出的特征进行回归。
\qquad 对于N个training pairs { ( P i , G i ) } i = 1 N \{(P^i,G^i)\}_{i=1}^N {(Pi,Gi)}i=1N,其中proposal P i = ( P x i , P y i , P w i , P h i ) P^i=(P_x^i,P_y^i,P_w^i,P_h^i) Pi=(Pxi,Pyi,Pwi,Phi)、ground-truth bounding box G i = ( G x i , G y i , G w i , G h i ) G^i=(G_x^i,G_y^i,G_w^i,G_h^i) Gi=(Gxi,Gyi,Gwi,Ghi)都是四元组:前两项指明了bounding box的中心点的坐标,后两项是bbox的width和height。我们的目的是学习一个变换,将proposed box P P P 映射到ground-truth box G G G。
\qquad 我们用四个函数来(参数化)表示这个变换: d x ( P ) , d y ( P ) , d w ( P ) , d h ( P ) d_x(P),d_y(P),d_w(P),d_h(P) dx(P),dy(P),dw(P),dh(P)。前两个表示 P P P的bounding box的中心的一个scale-invariant的平移,后两个表示 P P P的bounding box的宽和高的一个log-space平移(尺度放缩)。则这个变换可以拆分为:平移+尺度放缩
- 先做平移(
Δ
x
,
Δ
y
\Delta x,\Delta y
Δx,Δy),
Δ
x
=
P
w
d
x
(
P
)
,
Δ
y
=
P
h
d
y
(
P
)
\Delta x=P_wd_x(P),\Delta y=P_hd_y(P)
Δx=Pwdx(P),Δy=Phdy(P)
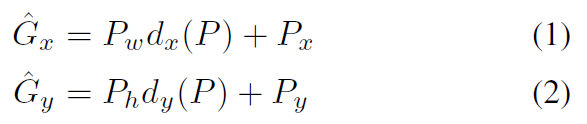
- 再做尺度放缩(
S
x
,
S
y
S_x,S_y
Sx,Sy),
S
w
=
exp
(
d
w
(
P
)
)
,
S
h
=
exp
(
d
h
(
P
)
)
S_w=\exp(d_w(P)),S_h=\exp(d_h(P))
Sw=exp(dw(P)),Sh=exp(dh(P))
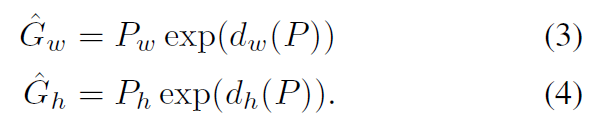
\qquad
每一个函数
d
∗
(
P
)
d_*(P)
d∗(P)都可以modeled as是proposal
P
P
P的pool5 feature的线性函数,记作
ϕ
5
(
P
)
\phi_5(P)
ϕ5(P)【实际操作中,并不是输入P的四元组,而是P的pool5 feature】,则有
d
∗
(
P
)
=
w
∗
T
ϕ
5
(
P
)
d_*(P)=w_*^T\phi_5(P)
d∗(P)=w∗Tϕ5(P),
w
∗
w_*
w∗是需要学习的参数。而此时,回归的真实目标也从G变为了:
t
∗
=
(
t
x
,
t
y
,
t
w
,
t
h
)
t_*=(t_x,t_y,t_w,t_h)
t∗=(tx,ty,tw,th),其中

因此,损失函数为
L
=
∑
i
N
(
t
∗
i
−
w
^
∗
T
ϕ
5
(
P
i
)
)
2
L=\sum_i^N(t_*^i-\hat{w}_*^T\phi_5(P^i))^2
L=i∑N(t∗i−w^∗Tϕ5(Pi))2
从而问题转化为正则化的最小二乘问题(Ridge回归):
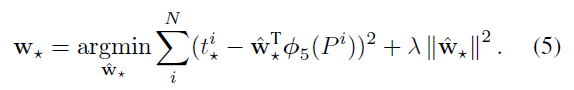
- 训练:【每一类进行一次bounding box回归,多次迭代并不会提升结果】
Input:proposal P的pool5 feature,真实的transformation t ∗ t_* t∗
Output:由(5)式训练出的参数 w ∗ w_* w∗,从而由transformation d ^ ∗ \hat{d}_* d^∗将 P P P映射为 G ^ \hat{G} G^
\qquad 进行bounding box回归时需要注意:(1)Ridge回归中正则化参数 λ \lambda λ很重要,本文取 λ = 1000 \lambda=1000 λ=1000。(2)只针对至少和一个ground-truth box“很近”的proposal P进行训练,这里“很近”指的是:与P重叠的ground-truth boxes中,IoU最大的ground-truth box G,且IoU大于等于0.6,则这样的{P,G}需要进行训练。其他不满足的P舍弃。
Test-time detection
RCNN具有两个性质:
(1)所有类别的CNN参数共享
(2)CNN得到的特征向量比其他方法得到的维数要低,例如spatial pyramids with bag-of-visual-word。
这种共享使得计算时间被分摊在所有类别上。每一类的计算只有:特征与SVM权重之间的点乘,和NMS。而一个图像的所有点乘计算可以写成矩阵-矩阵乘积。特征矩阵是2k × \times × 4096,SVM权重矩阵是4097 × \times ×N,其中N是类别数。这意味着,RCNN的性质使得它可以处理几千个目标种类而不需要借助近似技巧。
如何训练?
从RCNN的结构看,需要训练CNN和SVMs。
CNN
- 预训练:用Caffe中在ILSVRC2012上训练好的Alexnet作为初始状态
\qquad 在辅助数据集(ILSVRC2012)上预训练CNN,数据集只有图像水平的注释,没有边框label。预训练使用的是开源的Caffe CNN library。 - fine-tuning:将预训练好的AlexNet的最后1000-way ImageNet分类(softmax)层替换为随机初始化的(N+1)-way全连接层【N是物体类别数,+1是背景类】,其他结构不变。对于VOC,N=20;对于ILSVRC2013,N=200。
\qquad 使用warped region proposals来继续CNN参数的随机梯度下降(SGD)训练。训练细节:(1)region proposal的标签设置:与某个ground-thuth box的IoU大于等于0.5的为正,其他情况为负。(2)参数:SGD学习速率设为0.001【预训练学习速率的1/10】。(3)Mini-batch size:每个SGD迭代步,随机采样32个正样本和96个负样本,得到mini-batch大小是128


SVM——Object category classifiers
- 每一类都需要训练一个SVM
- 对每一类,正负样本的规定:该类的Ground-truth box是正样本,与Ground-truth box的IoU小于0.3【0.3是在测试集上从{0,0.1,…,0.5}中间确定的】的region proposal是负样本,其余的region proposal舍弃,不用作训练。
fine-tuning和SVM关于正负样本定义的不同 and softmax(附录B)
-
为什么要用不同的定义?
\qquad fine-tuning:对于每一个region proposal,找出与图片中ground-truth box的IoU值最大的那个box(如果存在这样的box),若IoU值大于等于0.5,则将这个region proposal标记为该box对应类别的正样本。其余proposals标记为background(即,所有类别中都是负样本)。
\qquad SVM:只将ground-truth box定义为对应类别的正样本,将与某一类中所有ground-truth boxes的IoU值都小于0.3的proposal标记为该类别的负样本。其余灰色区域的proposal舍弃。 -
这样分别定义的原因
1、若训练SVM时延用fine-tuning的正负样本定义,结果明显劣于现在的定义。
2、fine-tuning的定义方式增加了很多jittered样本,扩充了正样本的数量。在对整个网络进行微调时,这种扩充是必要的,防止过拟合。而在精确的局部化过程中,这些jittered样本会导致结果不是最优的。 -
为什么fine-tuning之后还要训练SVM?
\qquad 若直接用fine-tuning后的CNN的最后一层【21-way softmax 回归分类器】进行目标检测,会导致mAP下降(VOC2007)。这可能是因为fine-tuning中正样本的定义不能突出精确局部化的目的,而且训练softmax 分类器是在随机抽取的负样本上,而不是训练SVM时的hard negatives。
\qquad 本文推测:若在fine-tuning过程中增加一些变动,不训练SVM也是可以的。那么,这可以使RCNN更简洁,速度更快,且效果不变。
结果

















 854
854











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









