





RCNN是目标检测将CNN网络+regions proposal +BBox regression达到了目前目标检测的最好效果,参考文献很多为这篇论文的思想提供了很多思路。
这篇文章的思路实际现在反观是很简单的一个思路,因为训练样本很少,所以提取region proposal 来训练网络,窗口滑动的方式效率太低,所以使用BBox regression的方法拟合位置框。预训练模型的方法也是在文献中已经提出的方法,科学就是这样,不是你的方法有多高深,数学理论有多么完美,这是结果为王,这篇文章的效果相对以前提升了近25%,这是巨大的进步,并且为之后的位置检测进一步奠定了这个框架的地位—粗见,抛砖引玉
2.Object detection with R-CNN
将在这一部分讲述目标检测系统包含的三个模型
2.1模型设计
候选框提取:近些时间的论文提出了多种产生独立种类区域候选框的算法,其中包括objectness SS 特定种类的目标框 CPMC等等。RCNN使用不特定的目标框提取方法,我们选择SS方法作为与先前工作的比较
特征提取:我们从每一个候选框中使用caffe框架下的Krizhevsky给出的CNN方法抽取4096维特征向量,特征通过输入的规定大小的227*227像素大小的图片在前向传播的五个卷积层和两个全连接层中抽取,建议阅读22和23了解更多网络结构的信息。
为了计算候选框的特征信息,我们必须首先将图片数据转化成固定的大小,与提取CNN相兼容(227*227大小)。对于不规则的区域,我们采取简单的方法,不管他的纵横比
2.2 测试检测
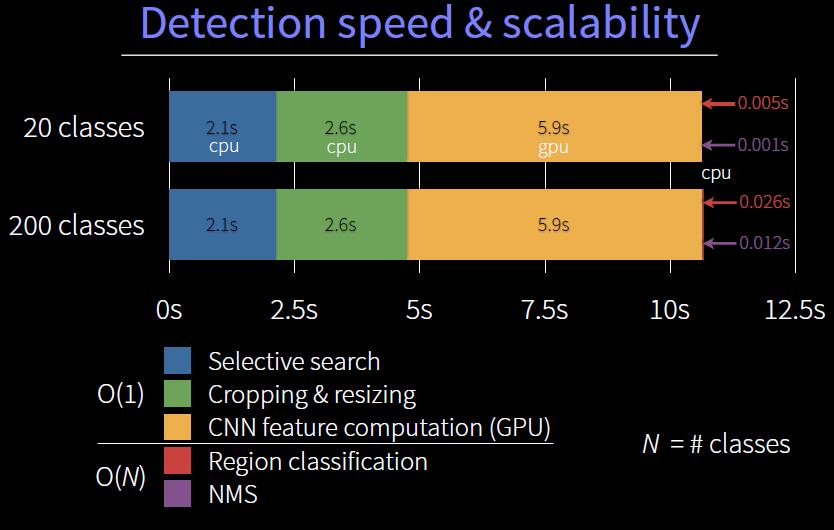
测试时采用SS方法从每一个测试图片中选取2000个候选框(SS快速模式),将图片尺寸归一化之后输入到CNN的指定层来提取特征,然后,对于每一种类,使用SVM方法对每一个提取的特征进行打分,鉴于所有的region proposal都存在于一张图片中,所以我们使用贪婪的非极大值抑制算法(对每一类独立使用)来抛弃那些与更高分被选择区域重叠率大于某个阈值的区域。
运行分析:两个特性使得检测高效,第一,CNN的参数被共享在所有的类间,第二,被CNN计算出的特征向量相对于其他普遍的特征计算方法是低维的,比如spatial pyramids with bag-of-visual-word方法。UVA检测系统提取的维度是我们提取维度高出两个数量级(360k vs 4k)
权值共享的结果是,将所有的计算region proposal 时间和计算特征的时间平摊在每一类的计算上面,唯一的与类相关的计算时间就是特征和SVM权重和非极大值抑制的计算时间。实际上所有的图片最终被转化成矩阵-矩阵的运算。特征矩阵规定为2000*4096,SVM的权重矩阵为4096*N,其中N是待检测数据集物体种类。
这些分析显示RCNN能够分类上千种物体种类而不用使用其他方法,如哈希表(hashing)。即使有十万种类,计算出最后的多阶矩阵的结果在现代多核CPU上也只需要10秒钟。使用region proposal和共享特征的效果布置局限在这个效果上,UVA系统需要使用134G的容量而RCNN只需1.5G。
还可以比较DPM方法和RCNN方法的mAP。。。略
2.3训练
有监督的预训练:我们有区别的在辅助数据库ILSVRC2012(图片分类层面,标签没有BBox信息)预训练CNN,预训练采用的是开源的caffe CNN库。简单的说我们训练出来的CNN模型基本接近于文献23所训练的。获得了top1错误率2.2%略高于ILSVRC2012公布的数据。这种差异是由于训练阶段阶段的简化。
特定领域参数调优:为了使我们训练的CNN模型适应检测的任务和新的领域(归一化的VOC窗口),我们继续通过随机梯度下降方法(SGD)只使用在VOC数据集中提取的warp过的候选框训练。通过一个随机初始化的21类(10中物体种类加背景)分类层来代替CNN模型中ImageNet数据集中特定的1000类的分类层,CNN的基本结构不变。我们将所有的IoU大于0.5的候选框标记为正样本,其余为负样本。SGD的学习速率设置为0.001(十分之一初始预训练的速度),这样就确保了在不用设置初始化的情况下使调参(FT)顺利进行。在每一次随机梯度下降的迭代中,我们统一使用32个正样本(包括所有类别)和96个背景样本构建一个最小分支128.我们将偏置设置为正样本窗口,因为正样本窗口相对于负样本窗口过少。
目标种类分类器:以训练一个二分类的检测器检测汽车为例。很明显需要把紧紧包括汽车的图片候选框设置为正样本,相类似的,没有与汽车部位相关的窗口则设置为负样本。不太清晰的是怎么设置部分覆盖汽车的窗口类别。解决这个问题需要用的IoU阈值,阈值以下的窗口设置为负样本。覆盖的阈值,0.3被从0-0.5的区间选取,我们发现小心的选取这个阈值是很重要的。如果将这个阈值设置为0.5,如文献34,会降低mAP 5个百分点,类似的,设置阈值为0则会降低4个百分点,每一类物体的正样本被简单的定义为ground-truth box。
一旦特征被抽取,训练标签被应用,我们对于每一类物体训练一个线性SVM。由于训练数据对于存储空间来说太过巨大,我们使用标准的负难例减少方法。难负例的挖掘可以很快地手链,并且在实践中所有图片中第一次过模型的时候mAP就将停止增长。
在补充材料中,我们讨论了为什么在支持向量机训练和FT中正负样本的设定会有不同,我们也讨论了为什么训练检测器是必要的,而不是简单的使用从已调参的CNN模型中直接使用第8层全连接层的输出。。
2.4 PASCAL VOC 2010-12中的结果
按照PASCAL VOC的最佳实践步骤,我们在VOC2007的数据集上验证了我们所有的设计思想和参数处理,对于在2010-2012数据库中,我们在VOC2012上训练和优化了我们的支持向量机检测器,我们一种方法(带BBox和不带BBox)只提交了一次评估服务器
表1展示了(本方法)在VOC2010的结果,我们将自己的方法同四种先进基准方法作对比,其中包括SegDPM,这种方法将DPM检测子与语义分割系统相结合并且使用附加的内核的环境和图片检测器打分。更加恰当的比较是同Uijling的UVA系统比较,因为我们的方法同样基于候选框算法。对于候选区域的分类,他们通过构建一个四层的金字塔,并且将之与SIFT模板结合,SIFT为扩展的OpponentSIFT和RGB-SIFT描述子,每一个向量被量化为4000词的codebook。分类任务由一个交叉核的支持向量机承担,对比这种方法的多特征方法,非线性内核的SVM方法,我们在mAP达到一个更大的提升,从35.1%提升至53.7%,而且速度更快。我们的方法在VOC2011/2012数据达到了相似的检测效果mAP53.3%。
3.可视化,融合和模型的错误
3.1学习特征的可视化
第一层滤波器能够被直接可视化,并且易于理解(参考文献23)。他们捕捉方向边缘和局部颜色。理解接下来的基层更加有挑战性。zeiler和Fergus在文献37中展示了一个形象化并且引人注意的解卷积网络的方法。我们提出一种简单且补充性的非参数化方法,这可以直接展示网络学习什么。
想法是在网络中挑选出特定的单元(一种特征)并且将之作为一种物体探测器。具体的,我们在一个很大的候选框数据集上计算特定特征的激活值,将激活值从高到低进行排序,应用NMS,然后显示出最高分区域。我们的方法使得这个选中的单元自己说话通过精确地展示他对什么样的区域感兴趣,我们避免平均为了看到不同的视觉模式,增加对于通过单元计算出的不变形的洞察力。
我们从第五pool层可视化单元,这个层经过最大池化的网络第五层,同时也是最后一层卷积层。第五层的特征结构是9216维,忽略边界影响,每一个第五pool单元在原始的227*227输入图像上有一个196*196像素的区域,中心的pool5单元有一个近似于全局的视角,而那些接近边缘的单元只有更小被剪切的支持。
在图三中每一行展示了我们从使用VOC2007调参过的CNN网络挑选的经过pool5层单元激活的16个最高得分图片。这里可视化了256个单元中的6个(在补充材料中有更多)。这些单元被选中展示网络学习的代表性的模板。在第二行,我们可以看出这个单元对于狗脸和点阵更加敏感。对应第三行的单元对红色的团簇更敏感,还有的单元对人脸和一些抽象的结构敏感,例如文本和窗户的三角形结构,学习网络呈现出学习小规模类别特征的和分散的形状,纹理,颜色和材质。家下来的第六层全连接层则是具备将一系列丰富特征部分模型化的任务。

3.2消融学习(分解学习)
逐层性能,不调参的情况下: 为了理解哪些层对于检测性能是关键的,我们分析了基于VOC2007的每一个CNN的最后三层结果。pool5层在3.1已经做了描述,最后两层见后文。
与pool5相连的fc6是全连接层。为了计算特征,他将一个4096*9216的权值矩阵与pool5相乘(pool5被剪切为一个9216维的向量)然后增加一个偏置向量。这个中间向量是一种分量方式的半波映射。
fc7是网络的最后一个层,这个层也被设置一个4096*4096的权值矩阵与fc6计算出来的特征相乘。相似的这个层也加入了一个偏置向量并应用了半波映射。
我们通过观察CNN在PASCAL上的结果开始,例如,所有的CNN参数只在ILSVRC2012上面预训练。逐层(表2.第1-3行)的分析性能揭示了经过fc7的特征相对于fc6的特征表现不够好。这就意味着29%或者说大约1680万的CNN网络参数对于提升mAP毫无作用。更加令人吃惊的是移除fc7和fc6层能产生更好的结果,即使pool5层的参数只用使用了CNN网络参数的6%。CNN网络最有代表性的作用产生自他的卷积网络,而不是用更多更密集连接的全连接网络。这个发现意味着就HOG的意义而言在计算密集特征更为有意义。这就意味着能够使基于滑动窗口的探测器成为可能包括DPM,在pool5层特征的基础上。(这两句话大致意思应该是,卷积层在网络中的作用相对于其它层是很大的,而且作为一种特征提取的方法,pool5层输出的特征同样可以选作为滑动窗口方法的素材)
逐层分析,有调参。我们现在来看我们基于VOC2007数据集调参之后的CNN网络的测试结果。这个提升是惊人的(表24-6行):调参使得mAP增长8个百分点至54.2%。通过调参得到的提升大于fc6,fc7和fc5的结果,这也意味着pool5学习的特征在检测中表现平平,绝大多数的提升来自于在pool5层之上学习了一个特定类别的非线性分类器。
与近年特征学习方法的比较:相当少的特征学习方法应用与VOC数据集。我们找到的两个最近的方法都是基于固定探测模型。为了参照的需要,我们也将基于基本HOG的DFM方法的结果加入比较
第一个DPM的特征学习方法,DPM ST,将HOG中加入略图表征的概率直方图。直观的,一个略图就是通过图片中心轮廓的狭小分布。略图表征概率通过一个被训练出来的分类35*35像素路径为一个150略图表征的的随机森林方法计算
第二个方法,DPM HSC,将HOG特征替换成一个稀疏编码的直方图。为了计算HSC。。。(HSC的介绍略)
所有的RCNN变种算法都要强于这三个DPM方法(表2 8-10行),包括两种特征学习的方法(特征学习不同于普通的HOG方法?)与最新版本的DPM方法比较,我们的mAP要多大约20个百分点,61%的相对提升。略图表征与HOG现结合的方法比单纯HOG的性能高出2.5%,而HSC的方法相对于HOG提升四个百分点(当内在的与他们自己的DPM基准比价,全都是用的非公共DPM执行,这低于开源版本)。这些方法分别达到了29.1%和34.3%。
3.3检测误差分析
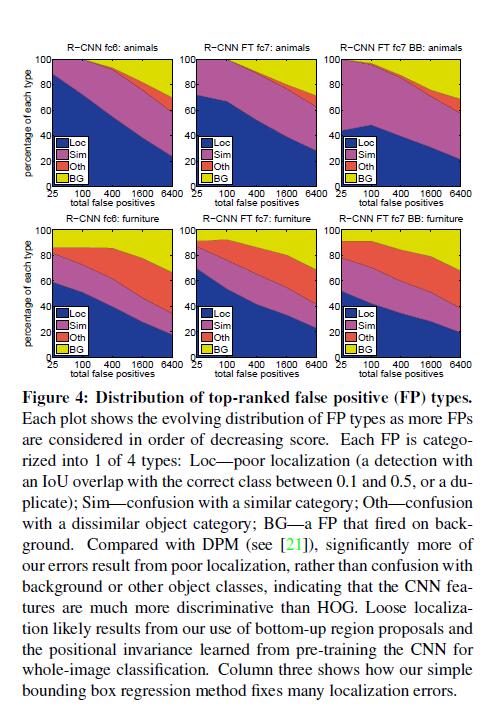
为了揭示出我们方法的错误之处, 我们使用Hoiem提出的优秀的检测分析工具,来理解调参是怎样改变他们,并且观察相对于DPM方法,我们的错误形式。这个分析方法全部的介绍超出了本篇文章的范围,我们建议读者查阅文献21来了解更加详细的介绍(例如归一化AP的介绍),由于这些分析是不太有关联性,所以我们放在图4和图5的题注中讨论。
3.4 BBox回归
基于误差分析,我们使用了一种简单的方法减小定位误差。受启发于BBox在DPM方法中的应用,我们训练了一个线性回归模型来预测新检测框的位置,基于SS方法提取的候选框pool5输出的特征。详细的方法在补充材料中给予阐述。表1表2和图4展示了这个简单方法对于错误位置巨大的修正提升达到3到4个百分点。
4.语义分割
语义分割我并没有搞,这部分略
5.结论
最近几年,物体检测陷入停滞,表现最好的检测系统是复杂的将多低层级的图像特征与高层级的物体检测器环境与场景识别相结合。本文提出了一种简单并且可扩展的物体检测方法,达到了VOC2012数据集相对之前最好性能的30%的提升。
我们取得这个性能主要通过两个理解:第一是应用了自底向上的候选框训练的高容量的卷积神经网络进行定位和分割物体。另外一个是使用在标签数据匮乏的情况下训练大规模神经网络的一个方法。我们展示了在有监督的情况下使用丰富的数据集(图片分类)预训练一个网络作为辅助性的工作是很有效的,然后采用稀少数据(检测)去调优定位任务的网络。我们猜测“有监督的预训练+特定领域的调优”这一范式对于数据稀少的视觉问题是很有效的。
最后,我们注意到通过使用经典的组合从计算机视觉和深度学习的工具实现这些结果(自底向上的区域候选框和卷积神经网络)是重要的。而不是违背科学探索的主线,这两个部分是自然而且必然的结合。
reference
文献19:C.Gu Recognition using regions,CVPR 2009 这篇文章给本文提供了思路。
文献23:A. Krizhevsky, I. Sutskever, and G. Hinton. ImageNet classification with deep convolutional neural networks. In NIPS, 2012. CNN模型提出的文章,经典论文
文献34 :J. Uijlings, K. van de Sande, T.Gevers, and A. Smeulders. Selective
search for object recognition. IJCV, 2013. SS regions proposal 选择算法
文献11:J. Donahue, Y. Jia, O. Vinyals, J. Hoffman, N. Zhang, E. Tzeng, and
T. Darrell. DeCAF: A Deep Convolutional Activation Feature for Generic Visual Recognition. In ICML, 2014. 为CNN性能说明















 10万+
10万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









