







 本文深入探讨了边框回归在目标检测算法中的作用,解释了为何需要边框回归,以及如何通过平移和尺度缩放进行边框调整。内容包括边框回归的目标、坐标变换形式的原理,以及为何在IoU较高时视为线性变换。
本文深入探讨了边框回归在目标检测算法中的作用,解释了为何需要边框回归,以及如何通过平移和尺度缩放进行边框调整。内容包括边框回归的目标、坐标变换形式的原理,以及为何在IoU较高时视为线性变换。
Bounding-Box regression
最近一直看检测有关的Paper, 从rcnn, fast rcnn, faster rcnn, yolo, r-fcn, ssd,到今年cvpr最新的yolo9000。这些paper中损失函数都包含了边框回归,除了rcnn详细介绍了,其他的paper都是一笔带过,或者直接引用rcnn就把损失函数写出来了。前三条网上解释比较多,后面的两条我看了很多paper,才得出这些结论。
- 为什么要边框回归?
- 什么是边框回归?
- 边框回归怎么做的?
- 边框回归为什么宽高,坐标会设计这种形式?
- 为什么边框回归只能微调,在离Ground Truth近的时候才能生效?
为什么要边框回归?
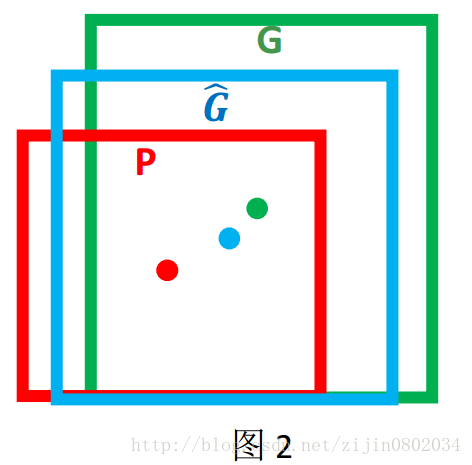
这里引用王斌师兄的理解,如下图所示:

对于上图,绿色的框表示Ground Truth, 红色的框为Selective Search提取的Region Proposal。那么即便红色的框被分类器识别为飞机,但是由于红色的框定位不准(IoU<0.5), 那么这张图相当于没有正确的检测出飞机。 如果我们能对红色的框进行微调, 使得经过微调后的窗口跟Ground Truth 更接近, 这样岂不是定位会更准确。 确实,Bounding-box regression 就是用来微调这个窗口的。
边框回归是什么?
继续借用师兄的理解:对于窗口一般使用四维向量 (x,y,w,h) 来表示, 分别表示窗口的中心点坐标和宽高。 对于图 2, 红色的框 P 代表原始的Proposal, 绿色的框 G 代表目标的 Ground Truth, 我们的目标是寻找一种关系使得输入原始的窗口 P 经过映射得到一个跟真实窗口 G 更接近的回归窗口 G^ 。
边框回归的目的既是:给定 (Px,Py,Pw,Ph) 寻找一种映射 f , 使得
边框回归怎么做的?
那么经过何种变换才能从图 2 中的窗口 P 变为窗口 G^ 呢? 比较简单的思路就是: 平移+尺度放缩
- 先做平移 (Δx,Δy) , Δx=Pwdx(P),Δy=Phdy(P) 这是R-CNN论文的:
G^
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章


















 1376
1376

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









