







预训练语言模型基础结构
大名鼎鼎的芝麻街
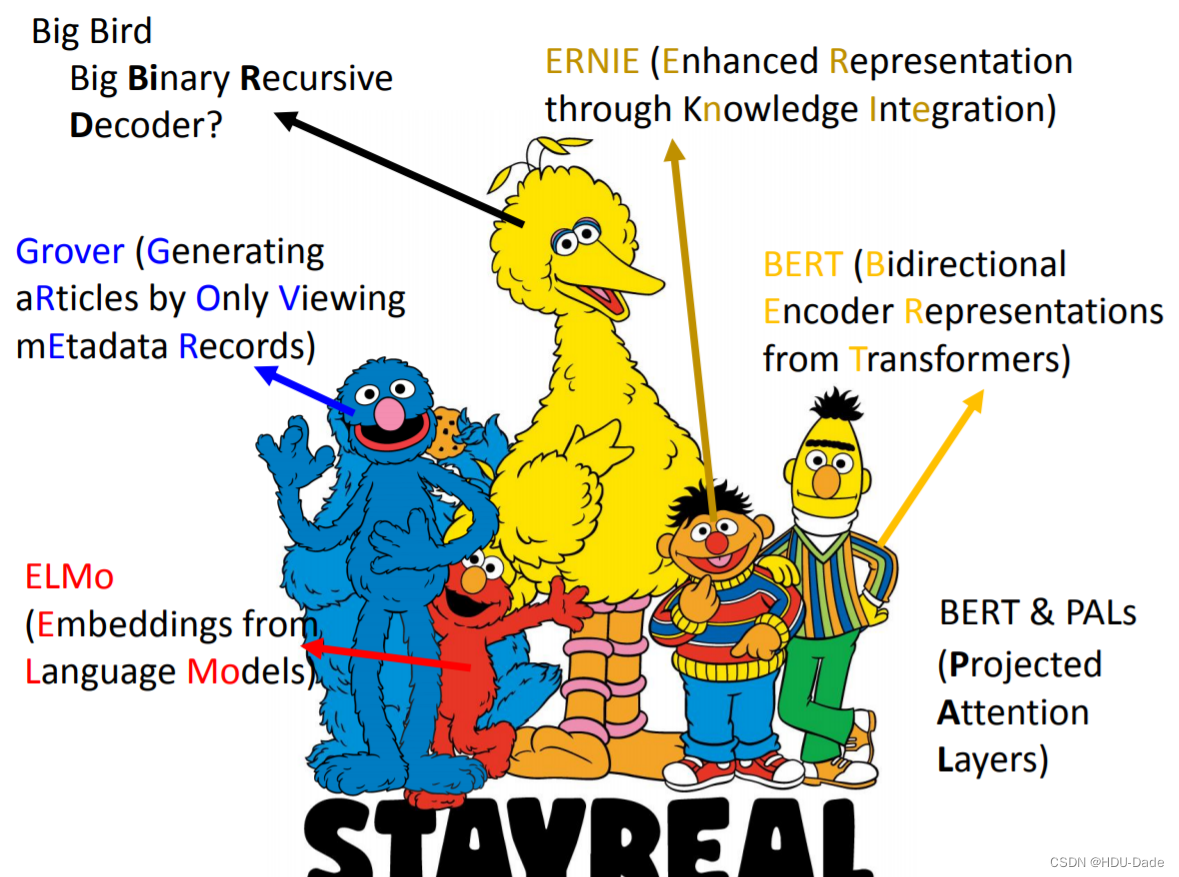
预训练语言模型的缩写大多是芝麻街的人物。
上图所示的模型(除了 Big Bird,因为没有这个模型)他们之间都有一些共同点,就是能通过一个句子的上下文来给一个词进行 Embedding,而能达到这种目的的网络架构有很多,例如 LSTM,Self-attention layers,Tree-based model(注重文法,一般表现不佳,只有在文法结构非常严谨的情况下表现好)等等
Smaller Model
预训练语言模型比来比去,变得越来越巨大,越来越臃肿,越来越玩不起。然而,让模型变小,穷人也能玩得起。这就是穷人用的 BERT。例如 Distill BERT,Tiny BERT,Mobile BERT,Q8BERT,ALBERT
究竟有哪些方法可以使 Model 变小呢?可以参考李宏毅老师模型压缩的视频讲解,以及 All The Ways You Can Compress BERT这篇文章。常见的方法有以下几种
-
Network Pruning 剪枝
-
Knowledge Distillation 知识蒸馏
-
Parameter Quantization 参数量化
-
Architecture Design 结构设计
Network Architecture Improvements
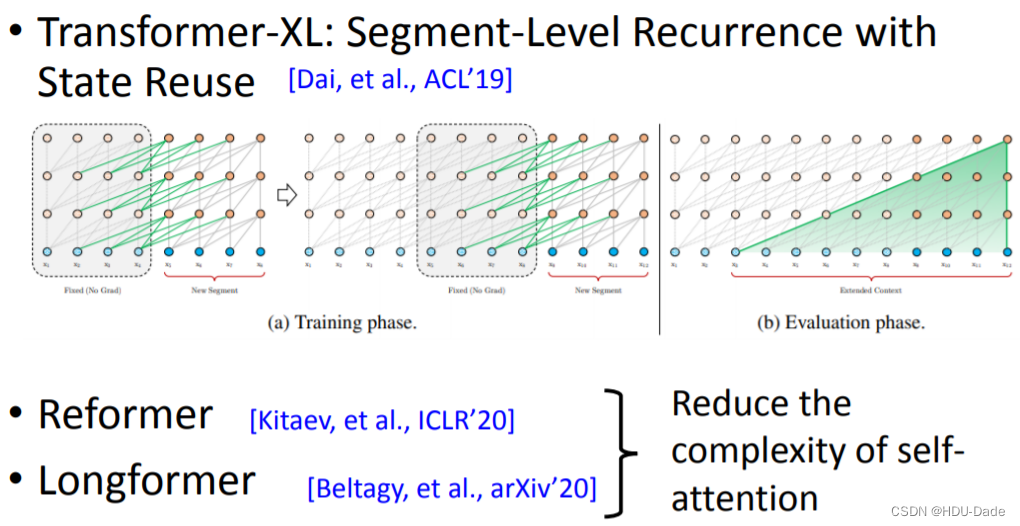
除了模型压缩以外,近年来比较火的尝试还有模型架构的设计。比方说 Transfomer-XL
通过理解跨片段的内容,可以处理非常长的序列;Reformer 和 Longformer 可以使得自注意力的复杂度变小.
How to Fine-tune
比方说输入一个句子如何进行分类,常见的做法就是利用 [CLS] 的输出后面跟一个线性分类层,又或者是将所有 token 的输出求一个 Average,再送入线性分类层。上述两种方法的目的都是要做分类,但是它们的本质区别在于究竟用什么东西来代表一个句子的 Embedding 比较好
Extraction-based QA

比方说现在将一篇文档和一个问题丢入 QA Model,模型会输出两个整数 s 和 e,这两个整数代表这个问题的答案就是文档中第 s 个词到第 e 个词
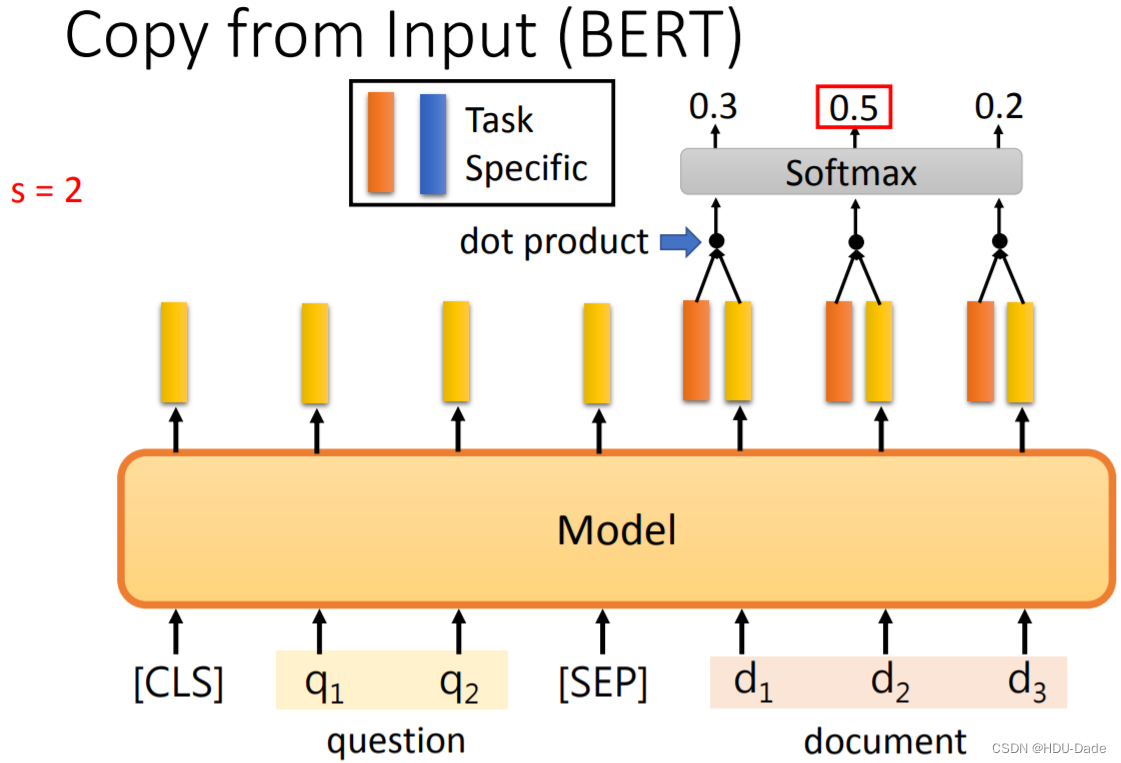
得到这两个整数的方式也很有意思。首先我们生成两个向量(上图中橙色和蓝色),用其中一个(橙色)向量去和 document 所有位置的输出做一个 dot product,之后再经过一个 Softmax 得到一系列概率值,我们取最大概率值所在的下标(其实就是 argmax)就得到了答案的开始位置 s=2
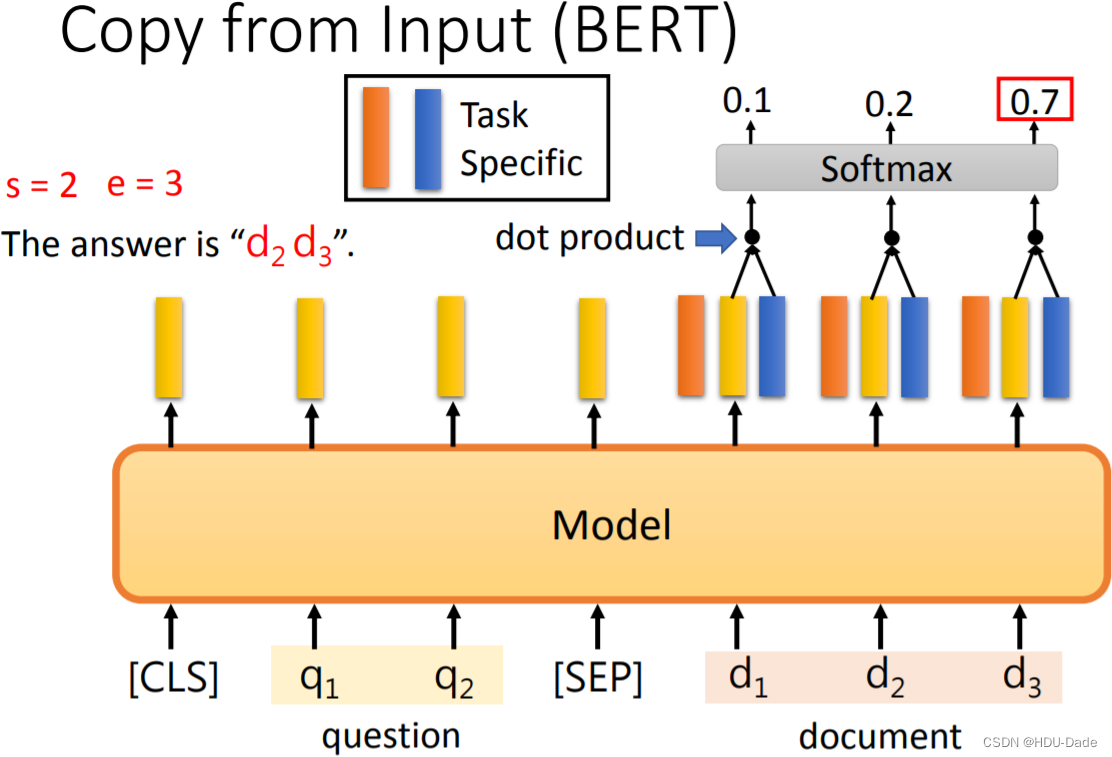
答案的结束位置 e 得到的方式也差不多,就是用另一个(蓝色)向量去和 document 所有位置的输出做一个 dot product,同样经过 Softmax 之后得到概率最大值所在的下标。那么最终答案就是 这个区间内的单词
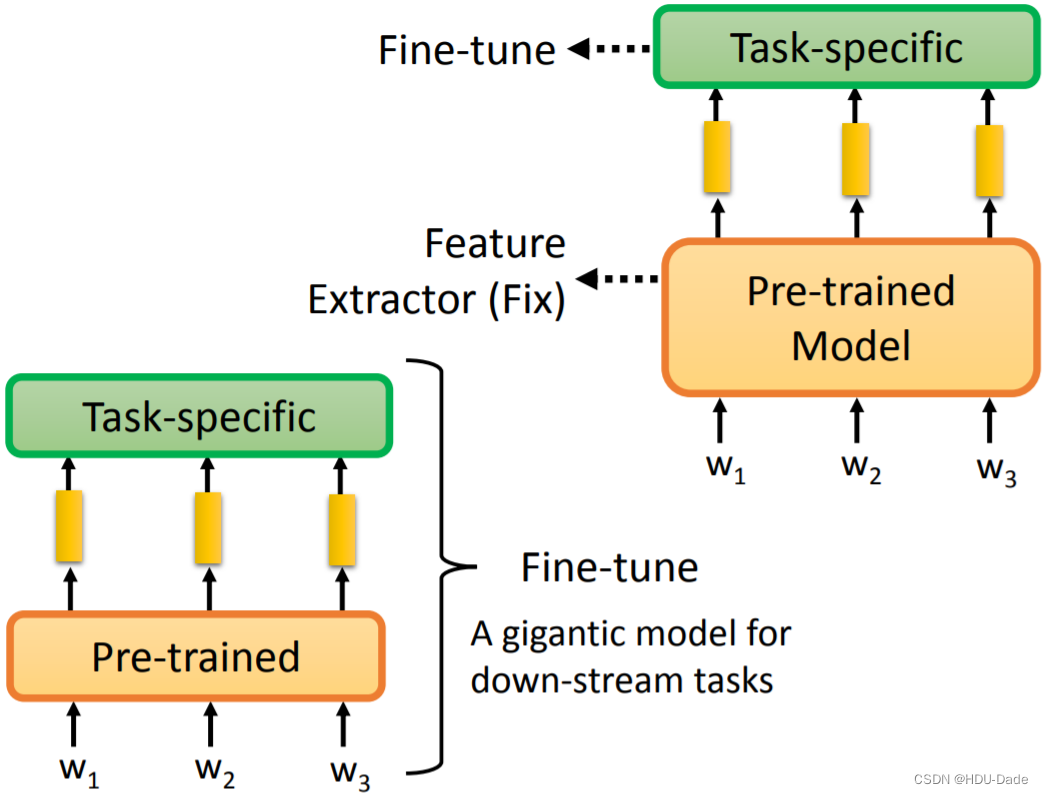
预训练语言模型要如何进行微调呢?一种方法是固定预训练的模型,让它作为一个特征提取器,训练的时候,只更新后面接的 Task-specific 模型的参数;另一种方法是不固定预训练语言模型的参数,所有参数在训练过程中都进行更新。不过就我本人做过的很多实验来看,后者效果是比前者好的,但是问题在于,很多预训练模型特别大,所以不得不采用前一种方法
Combination of Features
BERT 有很多 Encoder Layer,大家常规的做法都是提取最后一层的输出来做下游任务,但实际上这是最优解吗?其实就有人在 NER 任务上做过一个实验,将不同层的输出进行各种组合,得到的效果如下
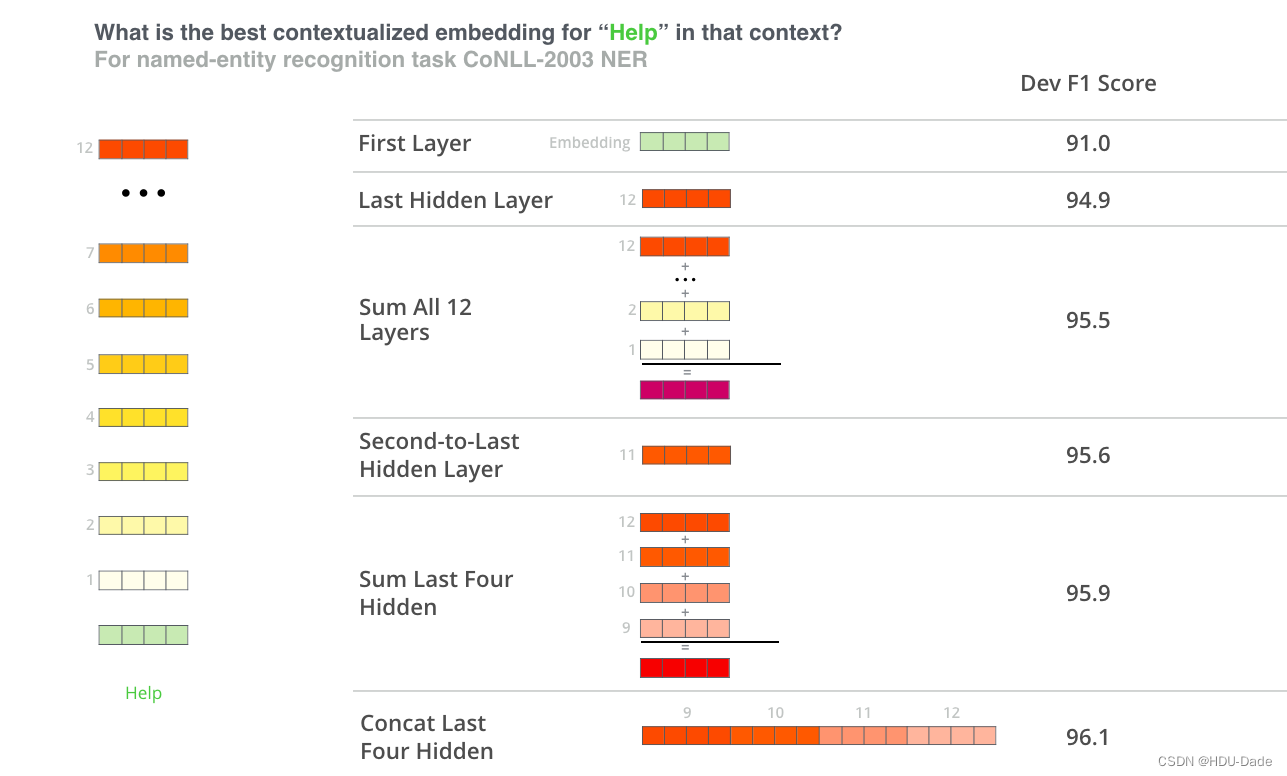
Github 有一个名为 bert-as-service 的开源项目,该项目旨在使用 BERT 为您的文本创建单词嵌入。他尝试了各种方法来组合这些嵌入,并在项目的 FAQ 页面上分享了一些结论和基本原理
-
第一层是嵌入层,由于它没有上下文信息,因此同一个词在不同语境下的向量是相同的
-
随着进入网络的更深层次,单词嵌入从每一层中获得了越来越多的上下文信息
-
但是,当您接近最后一层时,词嵌入将开始获取 BERT 特定预训练任务的信息(MLM 和 NSP)
-
使用倒数第二层比较合理
Why Pre-train Models?
没那么多钱去从头训练一个比较大的模型,所以直接拿别人训练好的来用就行了
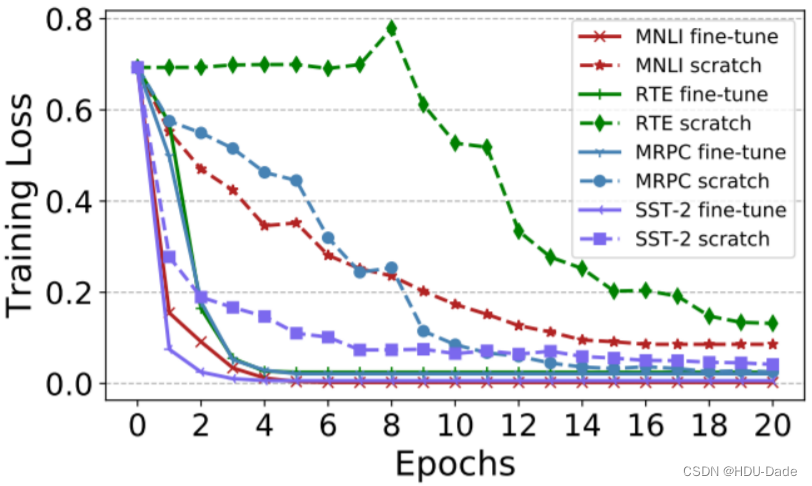
EMNLP 2019 的一篇文章 Visualizing and Understanding the Effectiveness of BERT 从学术角度仔细分析了为什么要使用预训练模型,文章表明,预训练模型可以大大加速损失的收敛,而不使用预训练模型,损失比较难下降。可以理解为,预训练模型提供了一种比随机初始化更好的初始化
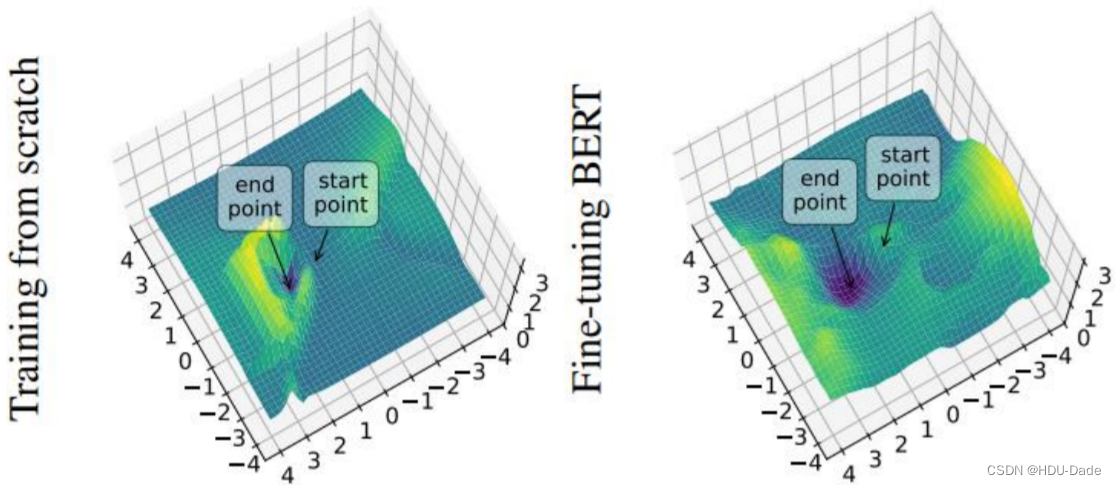
另一个结论是,预训练模型可以大大增加模型的泛化能力。上图表示给模型不同参数时,模型训练后结束点的损失会抵达一个 local minima 的位置。这个 local minima 的位置越陡峭,则泛化能力越差,因为输入稍微变化,它的损失就会有很大的变动;反之,这个 local minima 越平缓,则泛化能力越强
ELMo

传统的 LSTM 只是从左往右过一遍句子,那预测下一个 token 所依赖的信息就只能取决于它左边的内容,为了能真正利用这个 token 的上下文,我们可以从右到左再过一遍句子,即 BiLSTM。但实际上还不够,因为当模型在 encode
w
1
,
w
2
,
w
3
,
w
4
w_1,w_2, w_3,w_4
w1,w2,w3,w4 的时候,它没看到句子后面的部分;而在 encode
w
5
,
w
6
,
w
7
w_5,w_6,w_7
w5,w6,w7 的时候,也没考虑到句子前面的部分,所以 ELMo 在底层进行编码的时候并不是真正的双向。而在上层,由于两边的 embedding 进行了 concat,此时它才同时看到了双向的信息
BERT
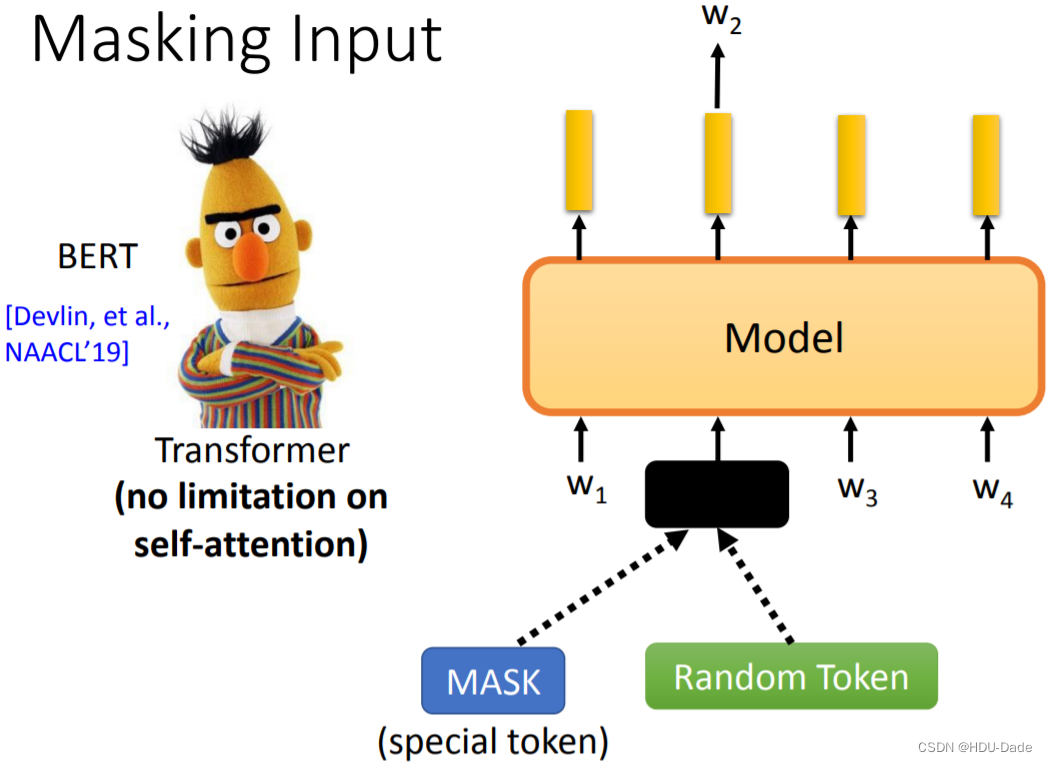
对于 Transformer 类模型(典型代表就是 BERT),自注意力机制使得它能够同时看到上下文,每一个 token 两两之间都能交互,唯一要做的只是随机地把某个 token 用 [MASK] 遮住就可以了
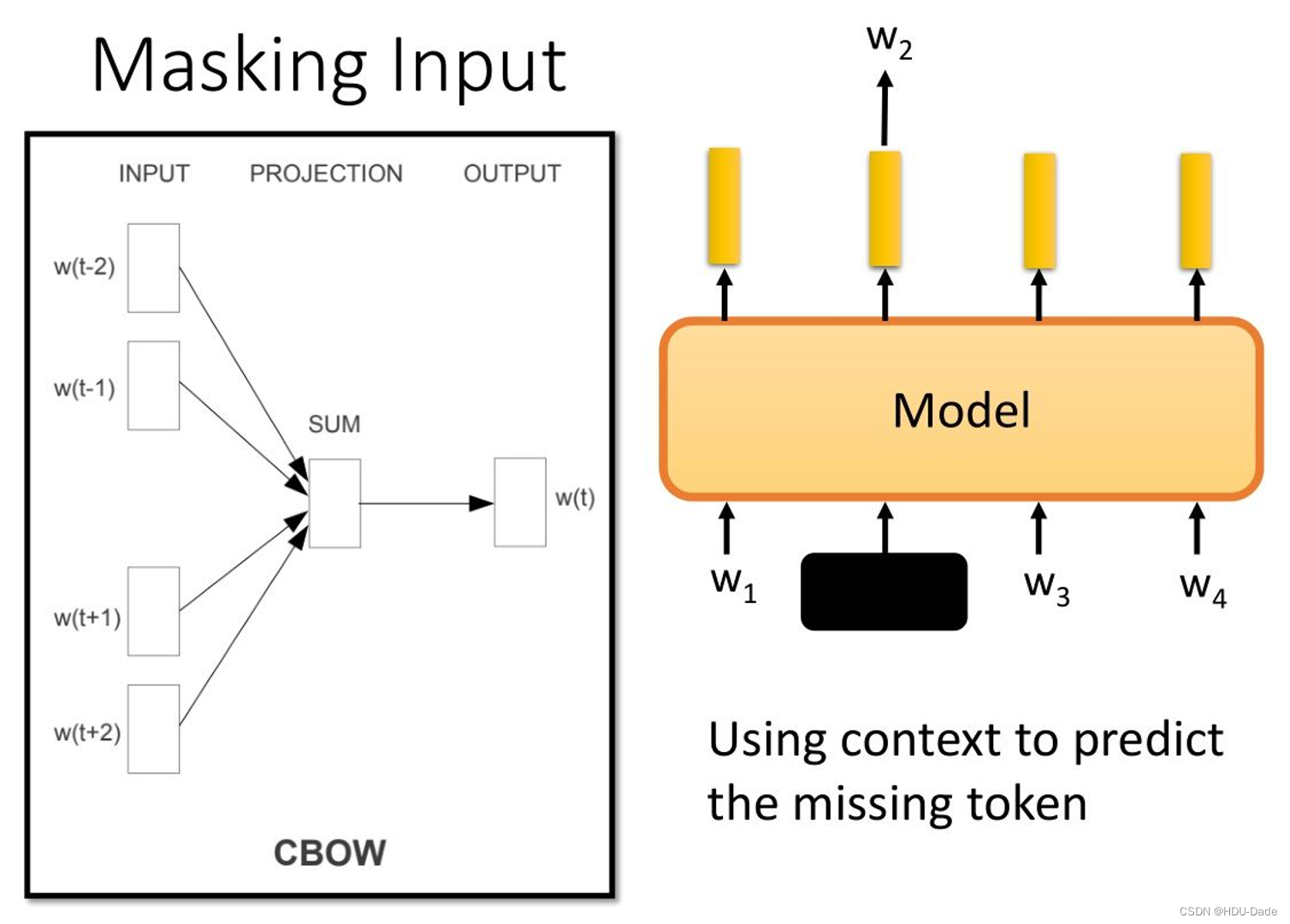
回溯历史, Word2vec 刚刚掀起 NLP 革命的时候,会发现 CBOW 的训练方式和 BERT 几乎一样,它们的主要区别在于,BERT 能关注的范围长度是可变的,而 CBOW 的范围是固定的
Whole Word Masking (WWM)
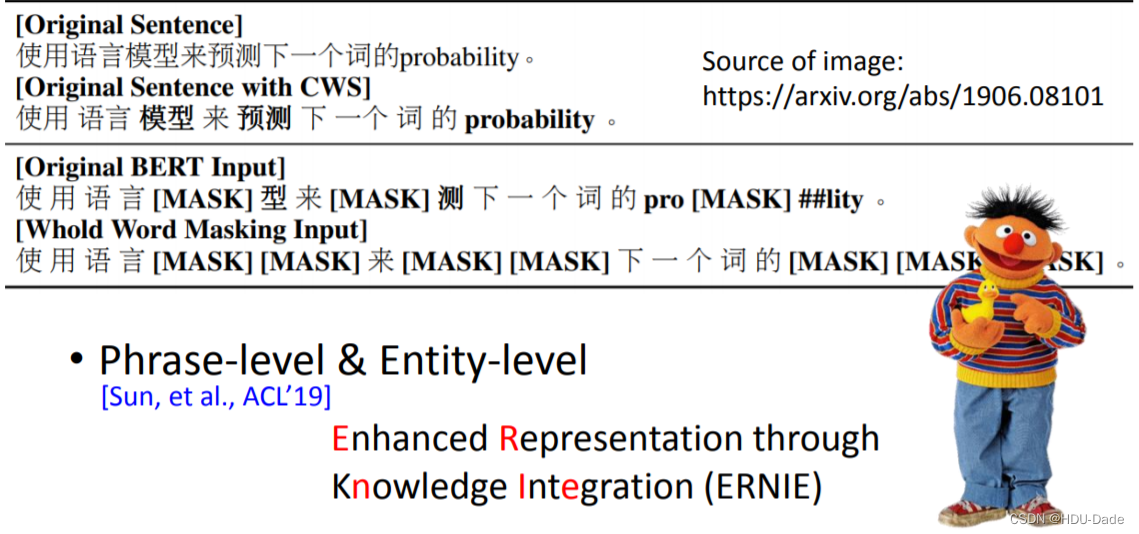
随机地 mask 掉某个 token 效果是否真的好呢?对于中文来说,词是由多个字组成的,一个字就是一个 token。如果我们随机 mask 掉某个 token,模型可能不需要学到很多语义依赖,就可以很容易地通过前面的字或后面的字来预测这个 token。为此我们需要把难度提升一点,盖住的不是某个 token,而是某个词(span),模型需要学到更多语义去把遮住的 span 预测出来,这便是 BERT-wwm。同理,我们可以把词的 span 再延长一些,拓展成短语级别、实体级别(ERNIE)
SpanBERT
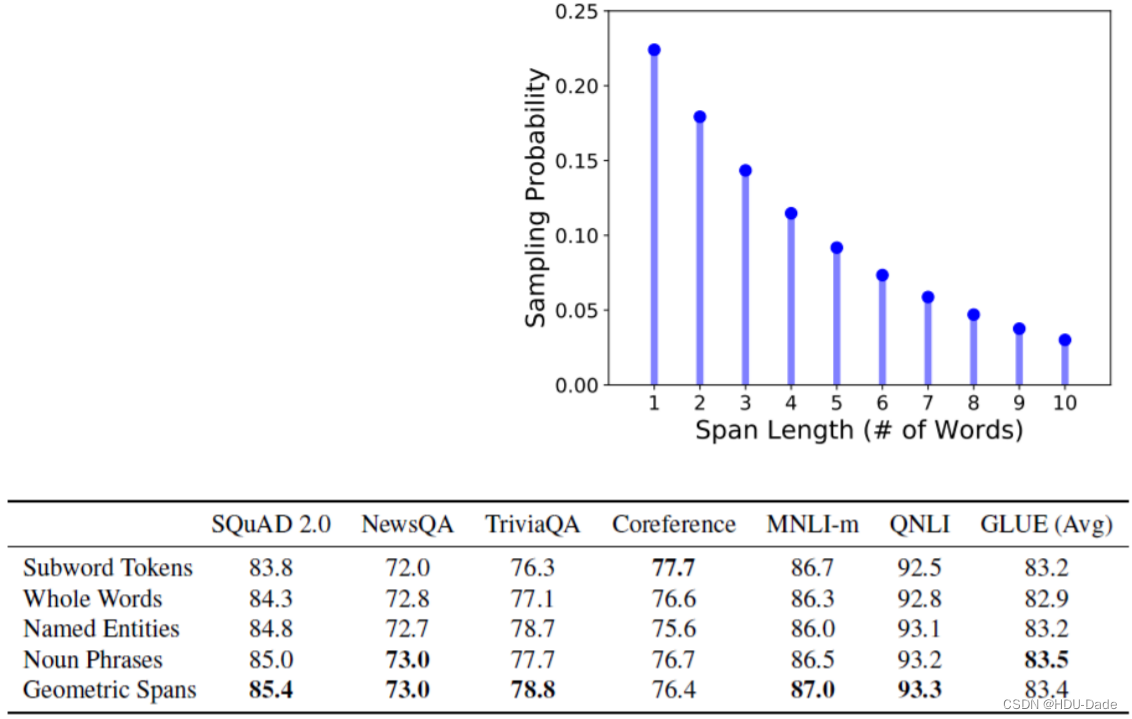
还有一种 BERT 的改进叫 SpanBERT。它每次会盖住 n 个 token,其中 n 是根据上图所示的概率得到的。实验结果发现,这种基于概率选择盖住多少个 token 的方式在某些任务上要更好一些
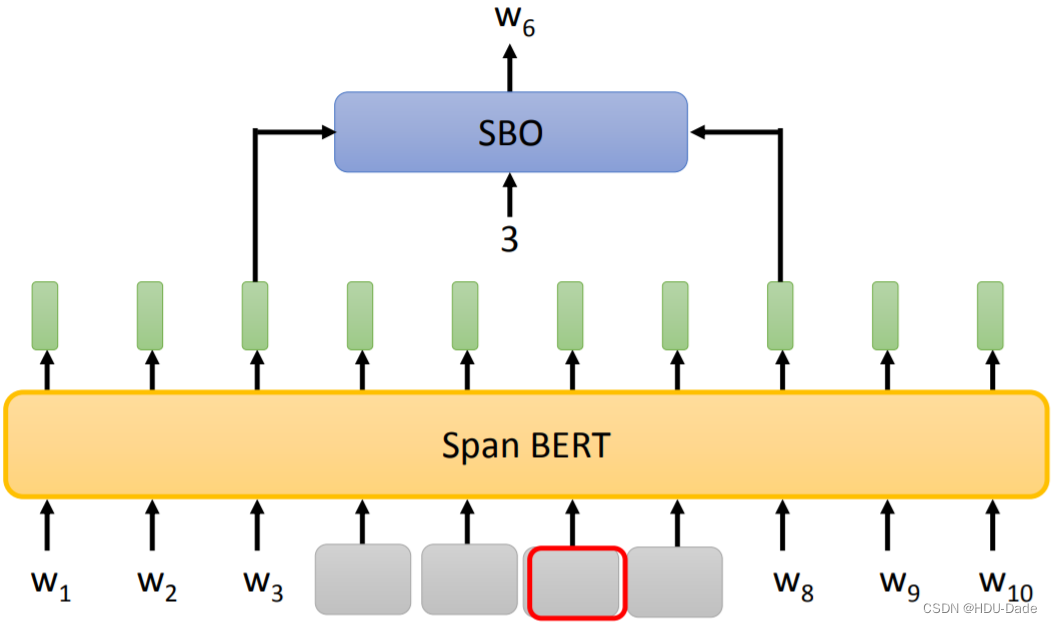
SpanBERT 还提出了一种名为 Span Boundary Objective (SBO) 的训练方法。一般我们训练只是把 masked 的 tokens 给训练出来。而 SBO 希望通过被盖住范围的左右两边的输出,去预测被盖住的范围内有什么样的东西。如上图所示,将
w
3
w_3
w3 和
w
8
w_8
w8 的输出以及一个索引送入后续的网络中,其中这个索引表示我们希望预测的是 span 中哪个位置的词
MASS/BART
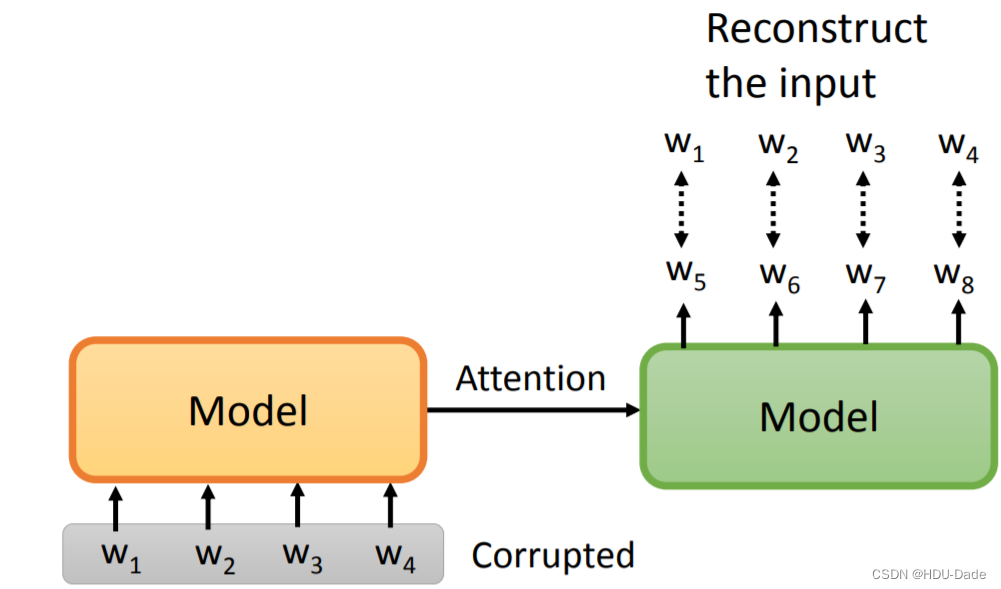
BERT 类模型缺乏生成句子的能力,所以它不太适合做 Seq2Seq 的任务,而 MASS 和 BART 这两个模型就解决了 BERT 不擅长生成的问题。我们首先把一个句子输入到 Encoder,我们希望 Decoder 的 output 就是 Encoder 的 input,但有一点要注意的是,我们必须将 Encoder 的 input 做一定程度的破坏,因为如果没有任何破坏,Decoder 直接将 Encoder 的输入 copy 过来就行了,它可能学不到什么有用的东西
MASS 的做法是,把输入的一些部分随机用 [MASK]token 遮住。输出不一定要还原完整的句子序列,只要能把 [MASK] 的部分预测正确就可以了
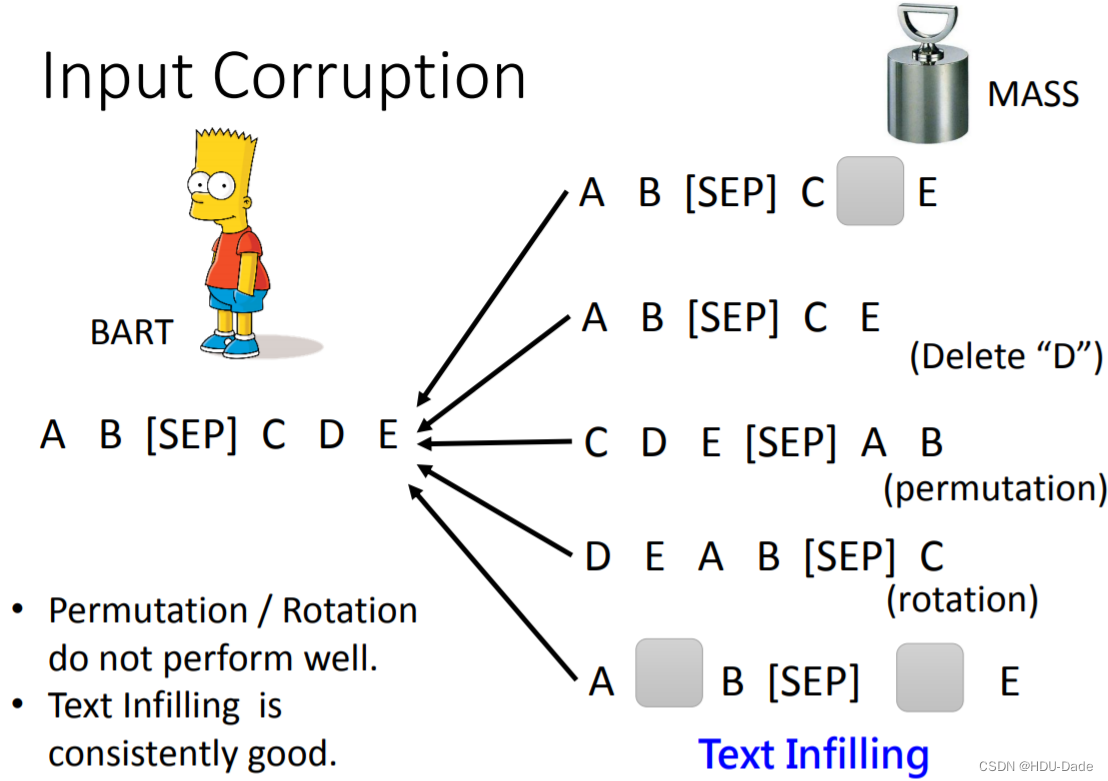
在 BART 的论文中,它又提出了各式各样的方法,除了给输入序列随机 mask 以外,还可以直接删除某个 token,或者随机排列组合等。
RoBERTa
RoBERTa 相较于 BERT 最大的改进有三点:
-
动态 Masking
-
取消 NSP (Next Sentence predict) 任务
-
扩大 Batch Size
静态 Masking vs 动态 Masking
-
静态 Maksing:在数据预处理期间 Mask 矩阵就已生成好,每个样本只会进行一次随机 Mask,每个 Epoch 都是相同的
-
修改版静态 Maksing:在预处理的时候将数据拷贝 10 份,每一份拷贝都采用不同的 Mask,也就说,同样的一句话有 10 种不同的 mask 方式,然后每份数据都训练 N/10 个 Epoch
-
动态 Masking:每次向模型输入一个序列时,都会生成一种新的 Maks 方式。即不在预处理的时候进行 Mask,而是在向模型提供输入时动态生成 Mask
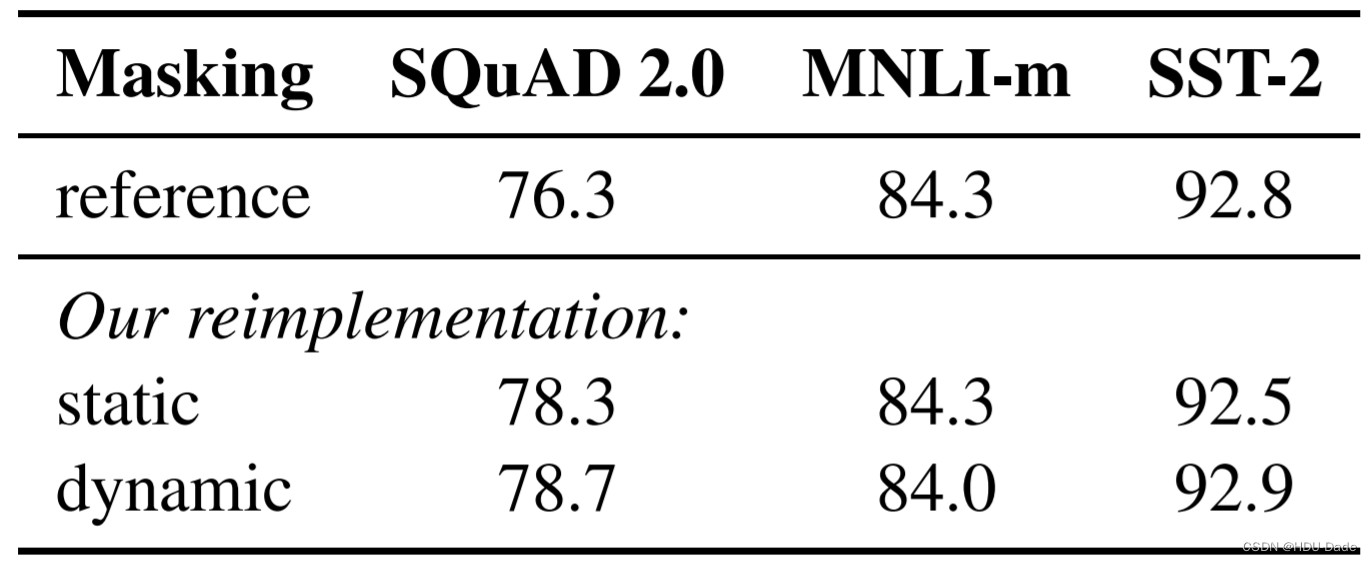
取消 NSP 任务
其实到 2020 年了,很多论文早已不再使用 NSP 任务,但是 RoBERTa 算是比较早的一批质疑 NSP 任务的模型。RoBERTa 实验了 4 种方法:
-
SEGMENT-PAIR + NSP:输入包含两部分,每个部分是来自同一文档或者不同文档的 segment (segment 是连续的多个句子),这两个 segment 的 token 总数少于 512 。预训练包含 MLM 任务和 NSP 任务。这是原始 BERT 的做法
-
SENTENCE-PAIR + NSP:输入也是包含两部分,每个部分是来自同一个文档或者不同文档的单个句子,这两个句子的 token 总数少于 512 。由于这些输入明显少于 512 个 tokens,因此增加 batch size 的大小,以使 tokens 总数保持与 SEGMENT-PAIR + NSP 相似。预训练包含 MLM 任务和 NSP 任务
-
FULL-SENTENCES:输入只有一部分(而不是两部分),来自同一个文档或者不同文档的连续多个句子,token 总数不超过 512 。输入可能跨越文档边界,如果跨文档,则在上一个文档末尾添加标志文档边界的 token 。预训练不包含 NSP 任务
-
DOC-SENTENCES:输入只有一部分(而不是两部分),输入的构造类似于 FULL-SENTENCES,只是不需要跨越文档边界,其输入来自同一个文档的连续句子,token 总数不超过 512 。在文档末尾附近采样的输入可以短于 512 个 tokens, 因此在这些情况下动态增加 batch size 大小以达到与 FULL-SENTENCES 相同的 tokens 总数。预训练不包含 NSP 任务
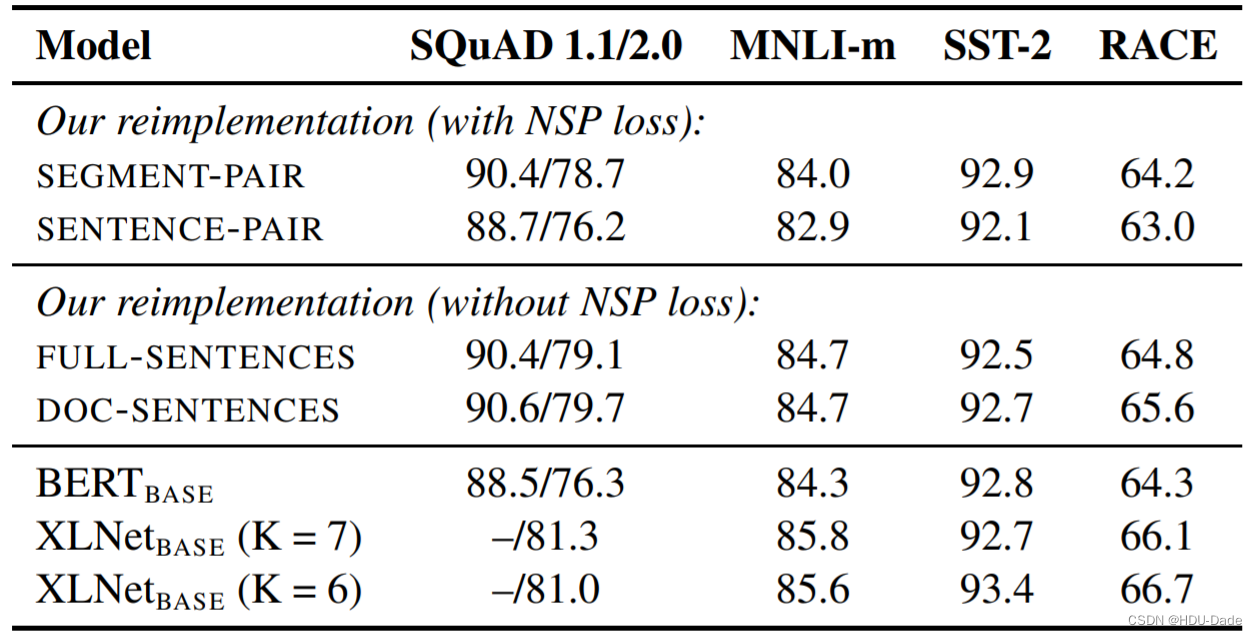
扩大 Batch Size
之前看到过一个说法:降低 batch size 会显著降低实验效果
RoBERTa 论文作者也做过相关实验,采用大的 Batch Size 有助于提高性能
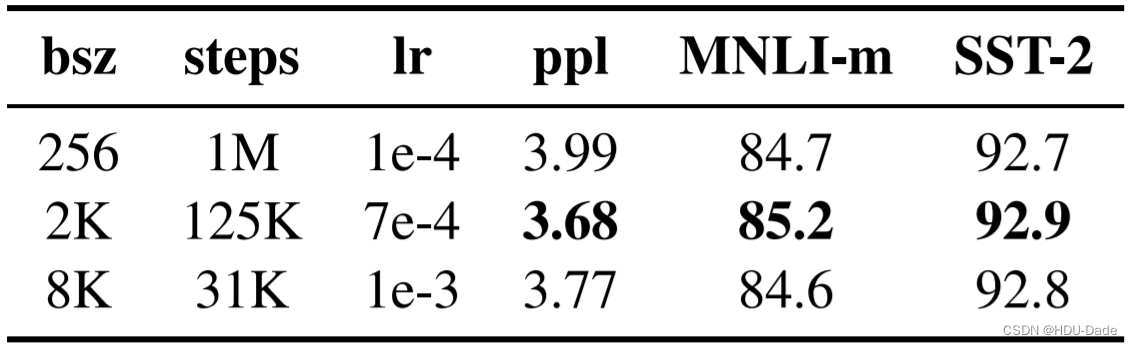
其中,bsz 是 Batch Size;steps 是训练步数(为了保证 bsz*steps 近似相同,所以大 bsz 必定对应小 steps);lr 是学习率;ppl 是困惑度,越小越好;最后两项是不同任务的准确率
UniLM

它既可以是编码器,也可以是解码器,还可以是 Seq2Seq。UniLM 由很多 Transformer 堆叠,它同时进行三种训练,包括 BERT 那样作为编码器的方式、GPT 那样作为解码器的方式、MASS/BART 那样作为 Seq2Seq 的方式。它作为 Seq2Seq 使用时,输入被分为两个片段,输入第一个片段的时候,该片段上的 token 之间可以互相注意,但第二个片段,都只能看左边 token
ELECTRA
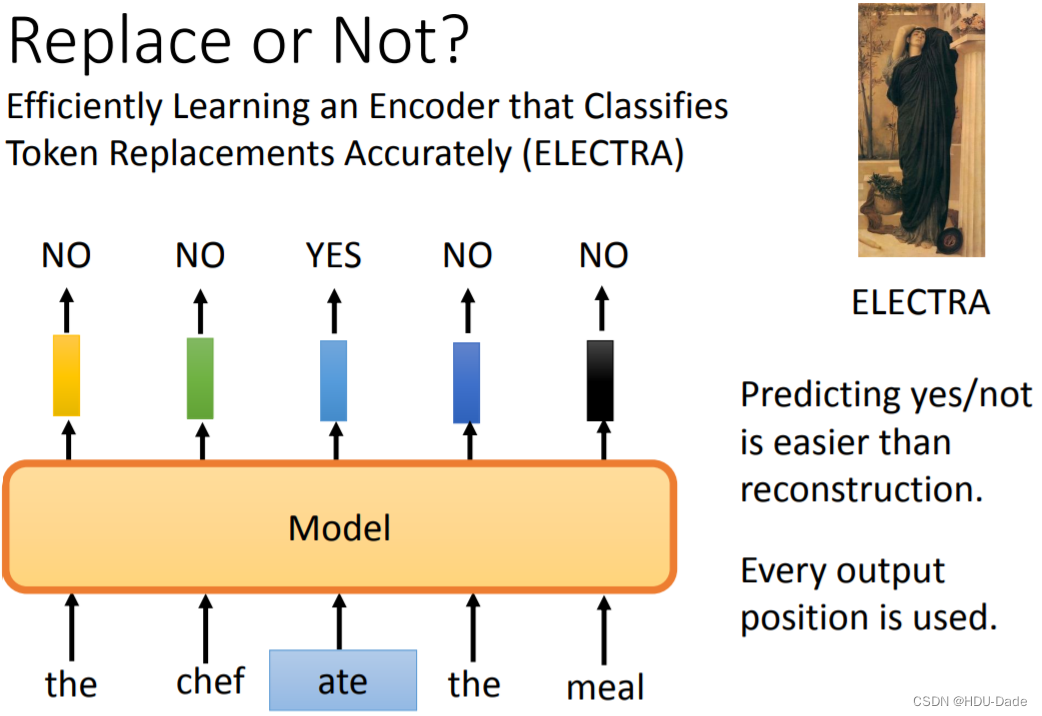
预测一个东西需要的训练强度是很大的,ELECTRA 想要简化这件事情,转为二分类问题,判断输入的某个词是否被随机替换了
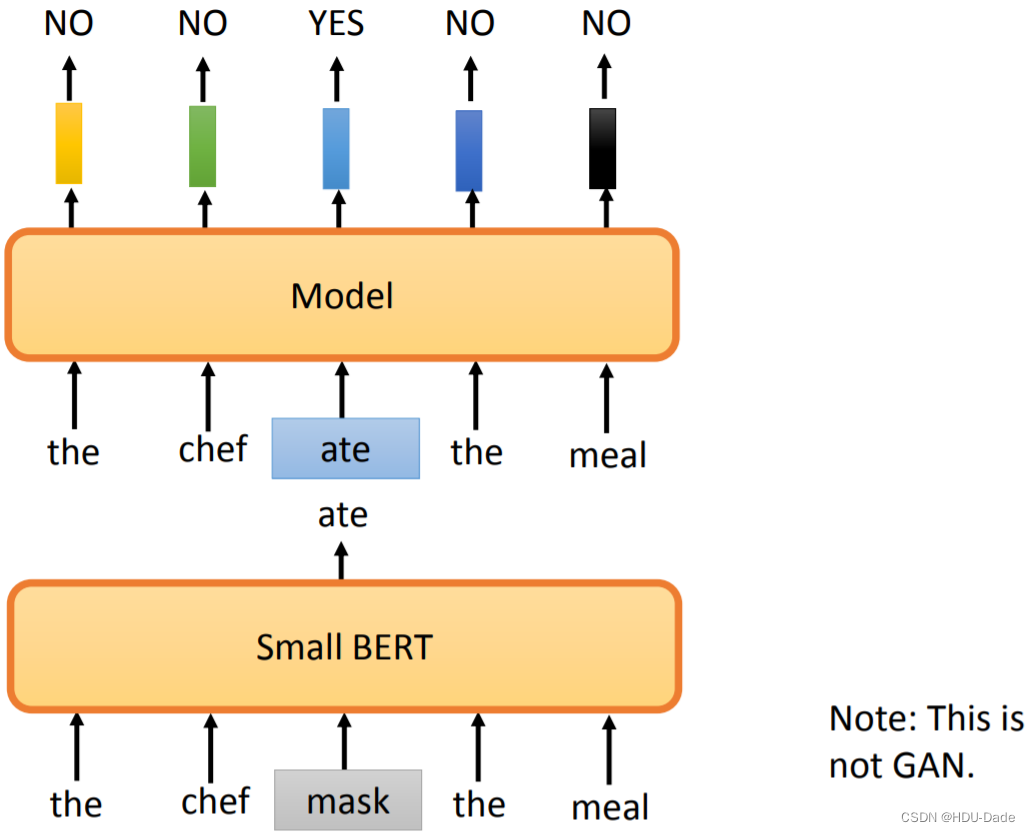
但问题来了,怎样把一些词进行替换,同时保证文法没错,语义也不是那么奇怪的句子呢?因为如果 token 被替换成了一些奇怪的东西,模型很容易就能发现,ELECTRA 就学不到什么厉害的东西了。论文用了另一个比较小的 BERT 去输出被 mask 的单词,这里不需要用很好的 BERT,因为如果 BERT 效果太好,直接就输出了和原来一摸一样的单词,这也不是我们期望的。这个架构看上去有点像 GAN,但实际上它并不是 GAN,因为 GAN 的 Generator 在训练的时候,要骗过 Discriminator。而这里的 small BERT 是自己训练自己的,只要把被 mask 的位置预测出来就好了,至于后面的模型预测的对不对和它没有关系
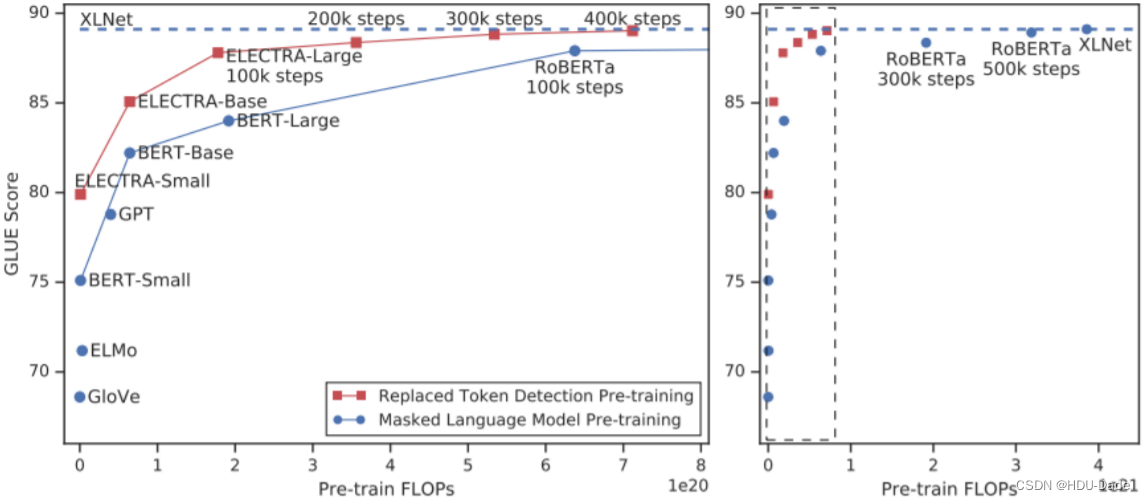
ELECTRA 训练效果很惊人,在相同的预训练量下,GLUE 上的分数比 BERT 要好很多,而且它只需要 1/4 的运算量就可以达到 XLNet 的效果
T5
预训练语言模型需要的资源太多,不是普通人随便就可以做的。谷歌有篇论文叫 T5,它展现了谷歌庞大的财力和运算资源,这篇文论把各式各样的预训练方法都尝试了一次,然后得到了一些结论,让别人没有研究可做

















 955
955

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









