







基于神经网络的空气质量指数预测
1 项目背景
1.1背景
随着我国经济的快速发展,大量的工厂企业以及尾气排放使得大气环境污染日益严重,所以大气污染的预测防治工作应该加大力度[1]。通过预测未来影响空气质量指数的污染物浓度,实现我们对短期空气质量状况和变化趋势的判断则变得尤为重要。
空气质量指数是将对人群产生影响的空气质量,通过对评价空气质量的污染物浓度计算得到的无量纲数值。用不同得等级表示空气污染状况的程度。空气质量指数主要是通过CO、NO、O3、PM10、 PM2.5、SO2这主要6种污染物浓度的规定的限值标准计算得到[2]。该指数被分为五个等级,按0~500的取值范围划分,从I级到V级的分级标准分别对应从优到严重污染的空气污染程度。空气污染的程度越严重对人体健康或是环境生态的影响越大[2]。为相关部门做出合理的决策提供科学的数据支撑,同时该研究成果对我国大气环境质量污染研究具有一定的参考价值和指导意义
1.2研究现状
目前空气质量数值预报的研究大多建立在气象数据和历史统计数据的基础上[4]。如郭飞等人在通过对沈阳大气环境质量历史数据和空气质量详细数据分析,用改进的支持向量机的方法精准的预测了污染物浓度[5]。使用变化权重组合实现多种方法的ARIMA、SVR组合模型达到理想的提高预测拟合效果[6]。张超利等人,结合数据相关性分析分析利用改进的粒子群算法的神经网络方法实现了河南省的空气质量的预测[3]。空气数据通过结合各种优化算法可以达到预期效果。
由此可见深度学习等方法的普及出现了许多新理论和创新,对大型地域的空气质量的从时空演化特[7]实现大规模分析并且从多种角度进行空气质量的数值预测。可总结空气质量数值预报技术主要有3个方向:首先基于历史污染物浓度数据记录或气象数据,利用统计学规律建立回归模型[8];第二种是时间序列的分析,通过历史的数据进行如ARIMA[9]模型建立,LSTM时间序列预测[10],通过结合数据特点来建立曲线拟合以及参数估计的拟合模型;第三种是利用大数据进行神经网络的建模方法,比如模糊推理系统,粒子群算法[10],改进如多类天气识别的区域选择和并发模型[12]等,使在空气质量预测的研究方向上提供了更多的思路。
1.3研究内容
本文基于石家庄地区的空气质量监测站和气象数据监测站得到的2019年石家庄空气质量的详细数据,利用神经网络的相关技术,通过数据的相关性分析,建立神经网络模型来预测未来第4小时的CO、NO、O3、PM10、PM2.5、SO2这6种污染物浓度,从而计算得到空气质量指数实现预警,课题研究思路如图2-1。本文的研究内容包括以下两点:
(1)数据相关性分析
由于获取的历史气象条件污染物浓度数据众多,不同污染物浓度的变化关系,通过自变量回归方法得到我们定义数据相关性系数,对于同一种污染物数据取相关系数较大的数据作为参考。以及实现神经网络模型的建立数据集提供参考依据。
(2)神经网络模型的建立
通过研究和学习BP神经网络,确定输入数据集,网络参数的确定实验,掌握前向传播和反向传播过程算法,确定学习率,网络节点个数的影响,建立能够实现预测未来小时的各个污染物浓度的模型,并通过污染物浓度计算空气质量指数实现预警。
本课题内容通过5个章节进行论述,第一章引述了课题研究的意义背景,将空气质量预测的相关研究成果和研究方向进行论述。第二章进行获取的空气质量数据集进行相关性分析,分析了污染物的季节变化特征,结合神经网络的特性,利用相关性系数为不同污染物的模型数据集提供依据。第三章简述了人工神经网络的算法,并且引入了算法的常见相关问题和相关概念,推导了两层前馈网络的前向传播和反向传播的公式。第四章介绍了实现空气质量指数预警的流程,得到优化的实验参数和完成了实验结果的验证。第五章总结了课题的研究思路,并对课题研究的发展趋势提出了观点。
2 项目方法
数据相关性分析
2.1 污染物的特点
分析主要的六种污染物为CO、NO、O3、PM10、PM2.5、SO2。这些污染物的主要来源是化学燃料的大量燃烧,资源燃烧会产生氮氧化物和硫化物,如春冬季节的锅炉供暖,日常交通的机动车辆运行等[4],大型企业工厂生产过程的烟尘颗粒和废气排放,这也会导致酸雨的形成,对建筑、生态环境产生危害,而当气象条件恶劣或空气流动性差时固体颗粒物与空气中物质融合变成气溶胶状态发生沉降,这也是导致雾霾产生的主要原因。
2.2 污染物浓度数据的相关性分析
通过中国气象数据网站,可以获取到石家庄2019年全年每小时6种污染物浓度数据和小时的空气质量指数。其中6种污染物默认CO的浓度单位为mg/m3,NO、 O3、SO2、PM10、PM2.5的浓度单位为μg/m3。通过对Excel表格软件操作,对全年的数据进行整理计算,得到每种污染物浓度的过去4个小时平均数值、过去12小时平均数值、过去第4小时数值、过去第12小时数值和过去第24小时数值共6种情况。6种污染物共计36种数据。通过研究预测的每个污染物的未来第4小时污染物浓度与36种数据的相关性,利用相关性系数选择网络的输入节点,并且相关性在后期对神经网络建模的参数选择上有着重要影响。
2.2.1 相关性系数的计算公式
相关性系数表示是两种变量数据之间的相关程度关系,通过回归模型可以表示变量在数据上的拟合相关程度,我们采用的计算公式是: 网络获取到的污染物浓度数据通常为有单位的如mg/m^3
而且以当前小时的六组数据co,no,o3,pm10,pm2.5,so2,六种污染物浓度。如果单纯用【1*6】向量数据作为输入,可能存在相关性低的数据。所以采用扩充数据,将六种污染物过去第6小时,第12小时的数据,过去24小时的平均,过去48小时平均数据。

其中Cov表示矩阵的协方差矩阵,它是以变量个数为维度的对称矩阵,假设和都是列向量,表示相关度即相关性系数,相关系数的绝对值越大,意味着两个随机变量线性相关性越大;相关系数的绝对值越小,意味着两个随机变量的线性相关性越小[12],并且根据数值和相关程度有以下表格定义相关程度。
经过分析可得
可以得出结论,按季节分的数据集相关性系数更大,然而按全年数据的气候条件得到反而相关性有所下降,所以数据集并非是越大越好,取决于相关性程度,除了SO2浓度数据选择的半年数据相关性较高之外,其他数据按季度相关性来划分数据集,这样在网络训练时会有更好的表现。
3 平台
Matlab2012以上。
2数据集建立
经过相关性分析筛选这些数据和预测未来第四小时的污染物浓度 。
相关系数 相关程度
0.00-±0.30 微相关
±0.30-±0.50 实相关
±0.50-±0.80 显著相关
±0.80-±1.00 高度相关
按照以上的程度,筛选0.5以上的作为输入的变量。
最终获得预测co的变量输入共19个输入。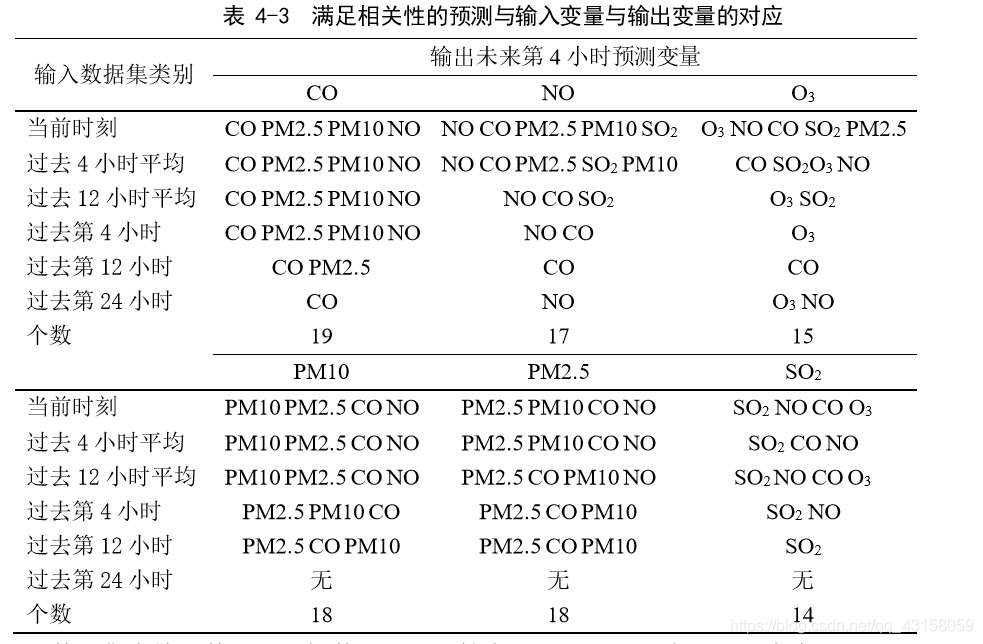

由于不同季节空气质量有不同时空分布。所以我们先建立一个秋季的数据集为例。按小时算一年8740小时,秋季在4300-6500小时。并且归一化整个数据集在-1.1范围内。
3神经网络建立
结尾程序文件中提供了3层的网络程序。
网络参数:输入层,h1层,h2层,输出层 。
学习率:采用预训练方式(手动调节),
权值矩阵初始化方式:随机分布(-1,1)
epoch(数据集训练轮数),Iteration(单条数据训练轮数)与学习率配合选择。
激活函数:tanh(值域范围【-1,1】)
损失函数:0.5*(predict-goal)^2。
更新权值算法:梯度下降算法。
整个的算法流程如下:

部分程序


4网络训练
调参是一个很枯燥的过程常见学习率满足下图规律
所以加入了R^2确定系数,作为一个拟合指标,并根据次参数实现基础网络自动调参训练。
程序非常好用
5 拟合效果与测试效果展示
我们训练数据随机输入下,加上预训练的结果如下。


尺度还原的效果,反归一化

网络的基本训练好的网络权值和数据已保存在文件夹下,其他的函数文件有相关的注释。我是一个初学小弟。有望大佬指教。
之后,空气质量指数的计算是输入为污染物浓度的线性函数。这个倒是可以网上查一下。我可以提供一个函数(自己编的比较粗糙)calaqi.m
这个函数没有写入主函数,需要者,自行建立接口。
某一个污染物浓度的预测结果:

总结
本课题通过对影响空气质量指数的主要污染物浓度数据相关性分析,得到的相关的数据选择实验结论,并在前馈神经网络的建模中控制变量实验得到的相关网络参数的参数选择结论,以此进行了模型的大量实验,确定6种污染物浓度的最优模型。最终基于前馈神经网络的污染物浓度预测模型的测试样本的确定系数均能达到0.6以上,模型拟合性良好,网络训练达到的均方误差基本都在0.15以下,并且实现IAQI带有浓度限值的计算过程后,误差进一步减小,基本可以实现空气质量指数(AQI) 的准确预测。因此利用神经网络的非线性函数映射能力,在预测污染物浓度变化实现空气质量指数预警具有可行性。
展望
空气质量指数的预警建立在数据分析和预测模型的基础之上,可以利用大数据分析技术结合泛化能力更强预测模型。本课题将不同污染预测都建立基于前馈网络的模型,具有不同差异,如O3浓度的预测效果相对较差,对于O3浓度可采用更简便的模型进行建立。而且前馈网络模型参数调整较为复杂,如隐含层个数的选择,数据集大小的影响等。对于未来可以在多输入多输出系统中进一步发展将会为预测模型的建立提供极大的便利性。
附件
附件种有两个主函数,一个是加自动调学习率的,一个是不加的基础结构(mainbp2.m)
变量中修改which可得到预测不同污染物的选择。
数据集变量是four.mat,在函数中自动导入
创建数据集导入的方法下期讲解。
程序已经调通,下载整体可直接运行,全部自动操作。
建议cpu i5 7代以上。
代码地址:
















 5151
5151

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











