







🚩前言
- 🐳博客主页:😚睡晚不猿序程😚
- ⌚首发时间:2022.9.9
- ⏰最近更新时间:2022.9.9
- 🙆本文由 睡晚不猿序程 原创,首发于 CSDN
- 🤡作者是蒻蒟本蒟,如果文章里有任何错误或者表述不清,请 tt 我,万分感谢!orz
1. 内容简介
论文标题:Hiding Images in Plain Sight: Deep Steganography
作者:Shumeet Baluja
发布于:NIPS 2017
自己认为的关键词:隐写术,神经网络
阅读目的:了解
阅读方式:泛读
2. 摘要浏览
解决的问题:实现相同图像大小的隐写
本文工作:使用深度神经网络实现了相同图像大小的隐写,编码器解码器同时训练
训练集:ImageNet
和 LSB 算法的区别:作者提出的架构可以将秘密图像的表示压缩并分配到所有的可利用的 bits 上
3. 图片、表格浏览
图一
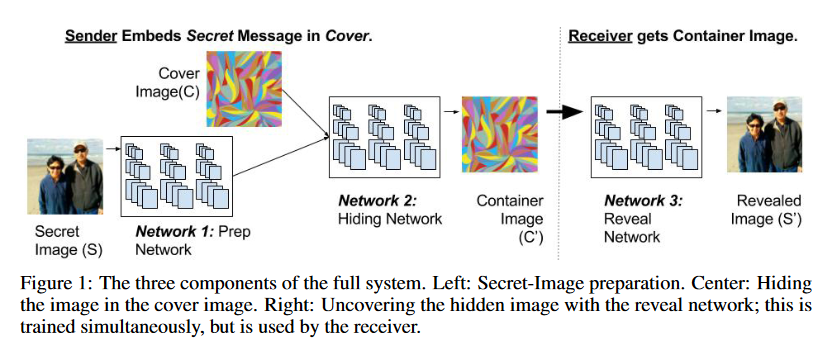
上面这个图片就是整个网络的架构信息了,首先秘密图像先经过一个网络进行预处理,然后和载体图像一起输入到一个隐藏网路中,生成一个载体图像。最后通过一个解码网络,可以把秘密图像重新恢复出来
图二

该图表示了预处理网络所做的变换,左边是最原始的彩色图像,中间是预处理网络提取出来的三个通道的信息。右边是是使用边缘检测器进行聚焦得到的效果,在最容易辨别的例子中,第二个通道的激活为图像的高频区域,(例如纹理和边缘)
图三
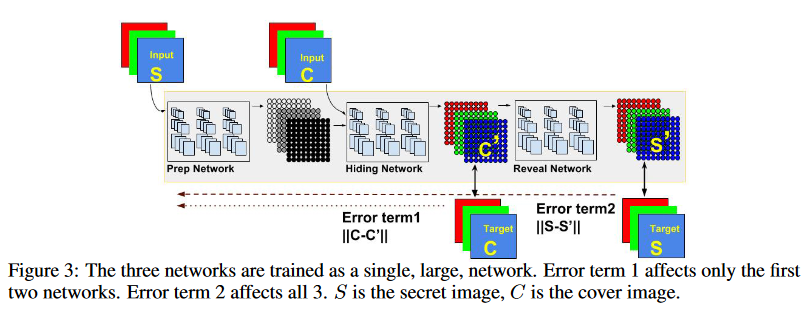
三个网络被联合起来一起训练,其中的 Error term 1 仅对前两个网络起作用,而 Error term 2 只对所有的网络起作用,S 代表的是秘密图像,而 C 代表的是载体图像
图四
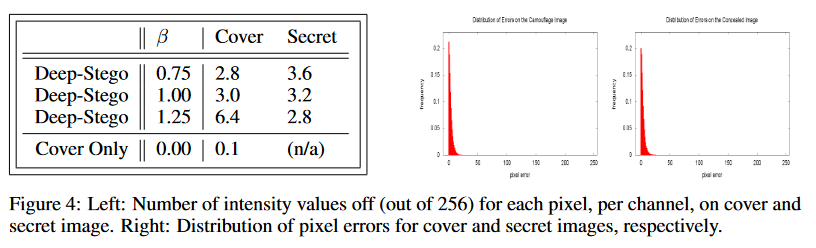
左:载体图像和秘密图像在每一个通道的每一个像素的intensity values off(这个是啥意思)
右:像素误差的分布图,可以看到像素误差基本控制在25以内,并且概率最高仅比 0.2 高一点,感觉效果挺不错的
图五

使用该模型进行隐写的效果图
左:载体图像和秘密图像
中:编码图像和提取出来的秘密图像
右:编码图像和原图像,秘密图像和提取出来的秘密图像之间的误差图,增强了五倍
图六

和训练图像集之外的自然图像进行嵌入的结果,看起来是使用了随机采样的图片,甚至拿了一张空白图片
图七

这个应该是这个网络的小问题
上面三行:如果原始图像泄露,那么可以把编码图像减去原始图像计算得到残差,然后对其增强 20 倍,我们可以看到一部分的秘密图像
下面三行:如果使用一个 error term 来处理,以最小化秘密图像和编码图像之间的关系,可以看到进行相同的操作,秘密图像泄露的信息更少,但是载体图像的像素误差提升了
图八

使用隐写分析工具 StegExpose 对其进行分析,可以看出基本约等于猜测,看起来效果不错哦
图九
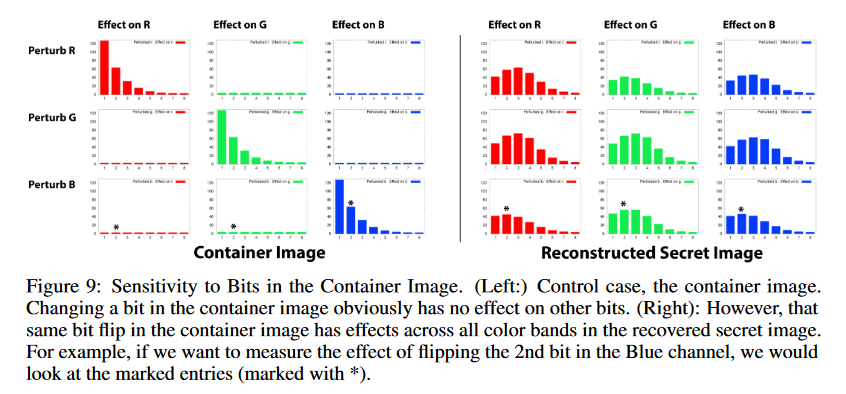
载体图像中位的敏感性(啥意思iai),这里采取了控制变量法,
左边是对载体图像的影响,我们对载体图像反转一个位,对载体图像没有任何印象
右边是对秘密图像的影响,我们对载体图像反转一个位,对解码出来的秘密图像的所有通道都有影像。
4. 引言浏览
这个引言貌似是关于隐写术的介绍
隐写术早在 15 世纪就已经出现了,在现代,隐写术主要注重的数字信息的隐写。隐写过程将会秘密信息插入到一个交换媒介中,这个媒介被称为 carrier,且 carrier 公开可见。为了增强安全性,可能对再对隐藏信息进行加密,
这样可以增强感知随机性并且减小秘密信息被探测并被解密的概率。如果想要得到更全面的隐写数和隐写分析的综述文章可查看底下的引文(一个问题,这个都是2017年的论文了,他的引文不得是上古时期?)
应用:在保持图像质量的情况下,嵌入水印信息,保护版权
挑战:嵌入隐写信息会改变载体的质量,改变的多少取决于两个因素:
- 隐写信息的大小
常见的隐写是将字符信息隐写进图像中,隐写的信息量使用 bits-per-pixel (bpp)这个值来表示,通常来讲这个值低于 0.4bpp。这个值越高,载体图像被修改的越多 - 载体图像
将秘密信息隐写进噪声区域,高频区域将会更难被人察觉(相比于隐藏进平滑区域)
最简单且普遍的隐写术是 LSB 算法,但是他非常容易被数据分析术所察觉。更高级的算法是显式建立模型。在这里作者通过神经网络建立自然图像的隐式模型来执行和载体图像相同大小的秘密图像的嵌入
【作者这里提到,好像大家对使用神经网络进行隐写分析的工作很感兴趣,但是我似乎很少看见这个东西呀?这应该就是神经网络隐写术的矛与盾把】
在那时候好像使用神经网络来进行隐写的研究还非常少,有一些研究甚至选择了用深度神经网络来选择哪一个 LSB 位进行替换来表达文字信息。或者是使用 DNN 来确定从载体图像中的哪一些位置提取比特(这些都是什么歪门邪道卧槽)
作者采用了不一样的方法,作者让神经网络来决定要在何处插入秘密信息,以及如何高效编码秘密信息,并且编码器和解码器网络同时训练。二者同时训练,但是在编码和解码过程中是各自独立的
论文目标:视觉上隐藏一个完整的 N × N × R G B N \times N \times RGB N×N×RGB 的图像到另一个 N × N × R G B N \times N \times RGB N×N×RGB 的图像中去(其中每个通道有八位),并最小化扰动。
成就:之前的研究说 hidden message bit rate 如果达到了 0.1 bpp 那就可能被察觉,但是按照这样说,作者的方法达到的 10-40 倍的比特率。因为写入的信息太大了,我们不指望他可以完全避免被类似数值分析等隐写分析工具所察觉
【这篇文章的引言写的好长啊,详细的介绍了这个方向的研究内容,应用,挑战和现阶段的发展状况,并且指出了自己的工作和前人的工作有何不同,并点到了自己完成的效果】
自由阅读
5. 架构以及误差传播
隐写术经常和图像密码学混为一谈,但是如果是使用作者的这个方式的话,实际上最接近的等价应该算是图像压缩
系统经过了训练,他要学习到如果将来自秘密图像的信息压缩到一个载体图像中,并且最小化他的可见性。下图展示了作者提出的模型架构
上面的这三个网络被串联起来,当作是一个网络来进行训练,把他们拆成部分来进行描述是最简单的
左:预处理网络,先对要隐藏的秘密图像进行预处理,这个组件的设计有两个目的:
- 如果秘密图像的大小比载体图像要小,预处理网络可以放大秘密图像,让他和载体图像的大小相匹配。
- 将原本基于颜色的像素转变成更为有用的特征以便于接下来的编码过程
中:隐藏网络:隐藏网络的输入是 cover img 和 pre img 按照通道的级联
作者在这个网络中尝试了非常多的架构,其中表现最好的有五个卷积层,每个卷积层有 50 个滤波器,分别为 3x3,4x4,5x5 大小(但是还是不知道网路是什么状况的)
右:解码网络:输入载体图像,进行解码
训练损失如下:
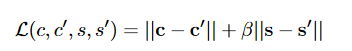
就是简单的减低其图像差距的范数?
C ′ C' C′ 代表的是载体图像, S ′ S' S′ 代表的是恢复出来的秘密图像,需要注意的是,C 的计算只用于更新前面两个网络,而 S 的计算将会用来更新全部的三个网络
为了防止网络仅仅简单的大秘密信息编码到 LSB 中(真的会这么巧吗),在训练的时候一些噪声会被添加到第二个网络的输出当中(也就是编码图像)这些噪声被设置过,会随机的造成 LSB 位的反转,这样就可以保证 LSB 位不会单独的承载图像的秘密信息重建的任务。接下来作者还会讨论图像的秘密信息被隐藏到哪里去了这一问题,接下来作者会测试为什么网络可以在实践当中运行的很好
6. 总结、预告
6.1 总结
看一下这篇论文单纯的是希望了解一下关于用神经网络实现图片隐写这一方面的起源是什么。我发现大部分的图像隐写论文都引用了该论文,应该是使用神经网络来做这一部分内容的第一人了。感觉这篇文章明显和最近几年新的文章写作风格以及内容的排版不大相同。其中甚至有一块经验分析,感觉是很神奇的一章节了。(我真的感觉深度学习有点像中医,像某种经验学科,我们好像不能确切的解释原理,但是他确实起作用了)
他采用的监督也比较简单,直接采用了图像之间的差的范数来作为损失进行监督,但是却不失有效性,也能够很好的来执行图像的隐写任务。而且图像之间的按通道级联,也是后面的 StegaStamp 使用来进行隐写的方式。
在网络训练的过程中,编码器的输出会先加上一部分的噪声然后再输入到解码器,作者说这样可以让网络不把所有的信息隐藏到 LSB 位(后面想了一下好像确实是,网络说不定会学习到把信息隐藏到 LSB 位效果最后,结果把大部分的信息都藏进去了,这不是我们的本意),但是按道理,如果我们可以在这个地方添加更具多样性的噪声,似乎可以增强整个网络的鲁棒性(就如 StegaStamp 网络的方法)
按照这样看,其实这个网络就像是图像隐藏任务的一个 baseline,能改进的地方有很多,其结构的设计也值去深挖。后面都有看到使用各种架构,如使用 INN,甚至是 Transformer 架构来做图像隐写任务。感觉大家的创造力真的都好大。
6.2 预告
最近打算看一下 INN 的内容,看看各位大佬都是如何改进 INN 这个模型的。但是标准化流这种完全基于概率的模型真的有点点难学,而且局限性好像挺大的,但是因为其逆变换确实是无损的,所以感觉如果能将这个优势更好的发挥出来,可能能做到更好的成效。

















 1866
1866

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









