







版权声明:本文为博主原创文章,未经博主允许不得转载。 https://blog.csdn.net/u011092188/article/details/78174804 </div>
<div id="content_views" class="markdown_views">
<!-- flowchart 箭头图标 勿删 -->
<svg xmlns="http://www.w3.org/2000/svg" style="display: none;"><path stroke-linecap="round" d="M5,0 0,2.5 5,5z" id="raphael-marker-block" style="-webkit-tap-highlight-color: rgba(0, 0, 0, 0);"></path></svg>
<p><strong>本系列文章为原创,转载请注明出处。</strong> <br>
作者:Tom Bai
邮箱: baidongdong@nudt.edu
若您觉得本博文对您有帮助,请您为我点赞并关注我,以鼓励我写出更优秀的博文。谢谢!
Normalization这个名词在很多地方都会出现,但是对于数据却有两种截然不同且容易混淆的处理过程。对于某个多特征的机器学习数据集来说,第一种Normalization是对于将数据进行预处理时进行的操作,是对于数据集的各个特征分别进行处理,主要包括min-max normalization、Z-score normalization、 log函数转换和atan函数转换等。第二种Normalization对于每个样本缩放到单位范数(每个样本的范数为1),主要有L1-normalization(L1范数)、L2-normalization(L2范数)等,可以用于SVM等应用
第一种 Normalization
数据的标准化(normalization)是将数据按比例缩放,使之落入一个小的特定区间。在某些比较和评价的指标处理中经常会用到,去除数据的单位限制,将其转化为无量纲的纯数值,便于不同单位或量级的指标能够进行比较和加权。其中最典型的就是数据的标准化处理,即将数据统一映射到[0,1]区间上。标准化在0-1之间是统计的概率分布,标准化在某个区间上是统计的坐标分布。目前数据标准化方法有多种。不同的标准化方法,对系统的评价结果会产生不同的影响,然而不幸的是,在数据标准化方法的选择上,还没有通用的法则可以遵循。
标准化(normalization)的目的:
在数据分析之前,我们通常需要先将数据标准化(normalization),利用标准化后的数据进行数据分析。数据标准化处理主要包括数据同趋化处理和无量纲化处理两个方面。数据同趋化处理主要解决不同性质数据问题,对不同性质指标直接加总不能正确反映不同作用力的综合结果,须先考虑改变逆指标数据性质,使所有指标对测评方案的作用力同趋化,再加总才能得出正确结果。数据无量纲化处理主要解决数据的可比性。经过上述标准化处理,原始数据均转换为无量纲化指标测评值,即各指标值都处于同一个数量级别上,可以进行综合测评分析。也就说标准化(normalization)的目的是:
把特征的各个维度标准化到特定的区间
把有量纲表达式变为无量纲表达式
归一化后有两个好处:
1. 加快基于梯度下降法或随机梯度下降法模型的收敛速度
如果特征的各个维度的取值范围不同,那么目标函数的等线很可能是一组椭圆,各个特征的取值范围差别越大,椭圆等高线会更加狭长。由于梯度方向垂直于等高线方向,因而这时优化路线会较为曲折,这样迭代会很慢,相比之下,如果特征的各个维度取值范围相近,那么目标函数很可能很接近一组于正圆,因而优化路线就会较为直接,迭代就会很快。~
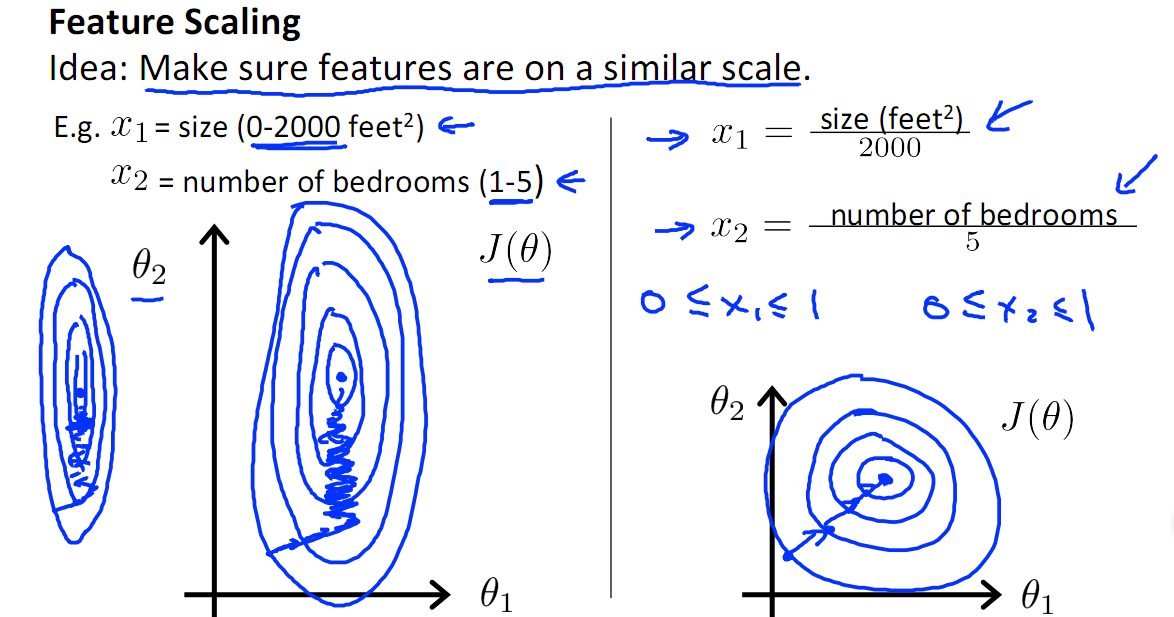
如上图,x1的取值为0-2000,而x2的取值为1-5,假如只有这两个特征,对其进行优化时,会得到一个窄长的椭圆形,导致在梯度下降时,梯度的方向为垂直等高线的方向而走之字形路线,这样会使迭代很慢,相比之下,右图的迭代就很快
2. 提升模型的精度
在多指标评价体系中,由于各评价指标的性质不同,通常具有不同的量纲和量级。当各指标间的水平相差很大时,如果直接用原始指标值进行分析,就会突出数值较高的指标在综合分析中的作用,相对削弱数值水平较低指标的作用。因此,为了保证结果的可靠性,需要对原始指标数据进行标准化处理。
如在涉及到一些距离计算的算法时,例如KNN:如果一个特征值域范围非常大,那么距离计算就主要取决于这个特征,从而与实际情况相悖(比如这时实际情况是值域范围小的特征更重要)。另外在SVM中,最后的权值向量ωω受较高指标的影响较大
所以归一化很有必要,它可以让各个特征对结果做出的贡献相同。
标准化的方法:
1. min-max normalization
这种归一化方法比较适用在数值比较集中的情况。这种方法两有个缺陷:
- 当有新数据加入时,可能导致 max 和 min 发生变化,需要重新定义。
- 如果max和min不稳定,很容易使得归一化结果不稳定,使得后续使用效果也不稳定。实际使用中可以用经验常量值来替代max和min
注意:计算时对每个特征分别进行。将数据按特征(按列进行)减去其均值,并除以其方差。得到的结果是,对于每个特征来说所有数据都聚集在0附近,方差为1。
使用SciKit-Learn实现:
>>> X_train = np.array([[ 1., -1., 2.],
... [ 2., 0., 0.],
... [ 0., 1., -1.]])
...
>>> min_max_scaler = preprocessing.MinMaxScaler()
>>> X_train_minmax = min_max_scaler.fit_transform(X_train)
>>> X_train_minmax
array([[ 0.5 , 0. , 1. ],
[ 1. , 0.5 , 0.33333333],
[ 0. , 1. , 0. ]])
>>> #将相同的缩放应用到测试集数据中
>>> X_test = np.array([[ -3., -1., 4.]])
>>> X_test_minmax = min_max_scaler.transform(X_test)
>>> X_test_minmax
array([[-1.5 , 0. , 1.66666667]])
>>> #缩放因子等属性
>>> min_max_scaler.scale_
array([ 0.5 , 0.5 , 0.33...])
>>> min_max_scaler.min_
array([ 0. , 0.5 , 0.33...])
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
当然,在构造类对象的时候也可以直接指定最大最小值的范围:feature_range=(min, max),此时应用的公式变为:
X_std=(X-X.min(axis=0))/(X.max(axis=0)-X.min(axis=0))
X_scaled=X_std/(max-min)+min
- 1
- 2
2. Z-score normalization
也叫标准差标准化,经过处理的数据符合标准正态分布,即均值为 0,标准差为 1 。其中μ为所有样本数据的均值,σ为所有样本数据的标准差。
注意:计算时对每个特征分别进行。将数据按特征(按列进行)减去其均值,并除以其方差。得到的结果是,对于每个特征来说所有数据都聚集在0附近,方差为1。
实现SciKit-Learn有两种不同的实现方式:
- 使用sklearn.preprocessing.scale()函数,可以直接将给定数据进行标准化。
>>> from sklearn import preprocessing
>>> import numpy as np
>>> X = np.array([[ 1., -1., 2.],
... [ 2., 0., 0.],
... [ 0., 1., -1.]])
>>> X_scaled = preprocessing.scale(X)
>>> X_scaled
array([[ 0. ..., -1.22..., 1.33...],
[ 1.22..., 0. ..., -0.26...],
[-1.22..., 1.22..., -1.06...]])
>>>#处理后数据的均值和方差
>>> X_scaled.mean(axis=0)
array([ 0., 0., 0.])
>>> X_scaled.std(axis=0)
array([ 1., 1., 1.])
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 使用sklearn.preprocessing.StandardScaler类,使用该类的好处在于可以保存训练集中的参数(均值、方差)直接使用其对象转换测试集数据。
>>> scaler = preprocessing.StandardScaler().fit(X)
>>> scaler
StandardScaler(copy=True, with_mean=True, with_std=True)
>>> scaler.mean_
array([ 1. ..., 0. ..., 0.33...])
>>> scaler.std_
array([ 0.81..., 0.81..., 1.24...])
>>> scaler.transform(X)
array([[ 0. ..., -1.22..., 1.33...],
[ 1.22..., 0. ..., -0.26...],
[-1.22..., 1.22..., -1.06...]])
>>>#可以直接使用训练集对测试集数据进行转换
>>> scaler.transform([[-1., 1., 0.]])
array([[-2.44..., 1.22..., -0.26...]])
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
3. log函数转换
4. atan函数转换
注意:使用这个方法需要注意的是如果想映射的区间为[0,1],则数据都应该大于等于0,小于0的数据将被映射到[-1,0]区间上,而并非所有数据标准化的结果都映射到[0,1]区间上。
相关资料:
- https://morvanzhou.github.io/tutorials/machine-learning/ML-intro/3-02-normalization/
- https://morvanzhou.github.io/tutorials/machine-learning/sklearn/3-1-normalization/
- http://www.cnblogs.com/chaosimple/p/4153167.html
- http://www.cnblogs.com/LBSer/p/4440590.html
- 标准化方法的选择
- http://blog.csdn.net/pipisorry/article/details/52247379
第二种Normalization
第二种Normalization对于每个样本缩放到单位范数(每个样本的范数为1),主要有L1-normalization(L1范数)、L2-normalization(L2范数)等
Normalization主要思想是对每个样本计算其p-范数,然后对该样本中每个元素除以该范数,这样处理的结果是使得每个处理后样本的p-范数(比如l1-norm,l2-norm)等于1。
p-范数的计算公式:
该方法主要应用于文本分类和聚类中。例如,对于两个TF-IDF向量的l2-norm进行点积,就可以得到这两个向量的余弦相似性。
实现SciKit-Learn有两种不同的实现方式:
- 可以使用preprocessing.normalize()函数对指定数据进行转换:
>>> X = [[ 1., -1., 2.],
... [ 2., 0., 0.],
... [ 0., 1., -1.]]
>>> X_normalized = preprocessing.normalize(X, norm='l2')
>>> X_normalized
array([[ 0.40..., -0.40..., 0.81...],
[ 1. ..., 0. ..., 0. ...],
[ 0. ..., 0.70..., -0.70...]])
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 可以使用processing.Normalizer()类实现对训练集和测试集的拟合和转换:
>>> normalizer = preprocessing.Normalizer().fit(X) # fit does nothing
>>> normalizer
Normalizer(copy=True, norm='l2')
>>>
>>> normalizer.transform(X)
array([[ 0.40..., -0.40..., 0.81...],
[ 1. ..., 0. ..., 0. ...],
[ 0. ..., 0.70..., -0.70...]])
>>> normalizer.transform([[-1., 1., 0.]])
array([[-0.70..., 0.70..., 0. ...]])
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
相关资料:
作者:Tom Bai
邮箱: baidongdong@nudt.edu
若您觉得本博文对您有帮助,请您为我点赞并关注我,以鼓励我写出更优秀的博文。谢谢!















 5187
5187











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









