







new optimization
SGD with momentum
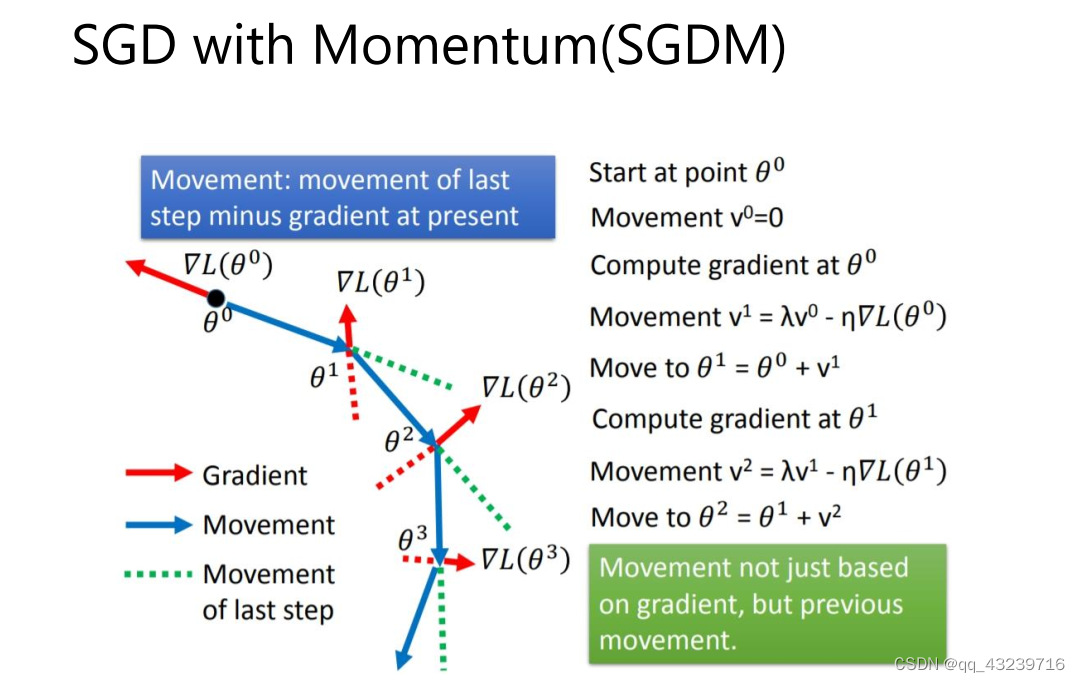
SGDM即为SGD with momentum,它加入了动量机制,1986年提出。
如上所示,当前动量V由上一次迭代动量,和当前梯度决定。第一次迭代时V0=0,由此可得到前三次迭代的动量。
由此可见t迭代的动量,其实是前t-1迭代的梯度的加权和。λ为衰减权重,越远的迭代权重越小。从而我们可以发现,SGDM相比于SGD的差别就在于,参数更新时,不仅仅减去了当前迭代的梯度,还减去了前t-1迭代的梯度的加权和。由此可见,SGDM中,当前迭代的梯度,和之前迭代的累积梯度,都会影响参数更新。
Adagrad
利用迭代次数和累积梯度,对学习率进行自动衰减,2011年提出。从而使得刚开始迭代时,学习率较大,可以快速收敛。而后来则逐渐减小,精调参数,使得模型可以稳定找到最优点。其参数迭代公式如下
与SGD的区别在于,学习率除以 前t-1 迭代的梯度的平方和。故称为自适应梯度下降。
Adagrad有个致命问题,就是没有考虑迭代衰减。极端情况,如果刚开始的梯度特别大,而后面的比较小,则学习率基本不会变化了,也就谈不上自适应学习率了。这个问题在RMSProp中得到了修正。
RMSProp
它与Adagrad基本类似,只是加入了迭代衰减,2013年提出。
观察上式和Adagrad的区别,在于RMSProp中,梯度累积不是简单的前t-1次迭代梯度的平方和了,而是加入了衰减因子α。简单理解就是学习率除以前t-1次迭代的梯度的加权平方和。加入衰减时make sense的,因为与当前迭代越近的梯度,对当前影响应该越大。另外也完美解决了某些迭代梯度过大,导致自适应梯度无法变化的问题。
Adam
Adam是SGDM和RMSProp的结合,它基本解决了之前提到的梯度下降的一系列问题,比如随机小样本、自适应学习率、容易卡在梯度较小点等问题,2015年提出。如下
由上可见,mt即为动量,根号vt即为自适应学习率。加入了两个衰减系数β1和β2。刚开始所需动量比较大,后面模型基本稳定后,逐步减小对动量的依赖。自适应学习率同样也会随迭代次数逐渐衰减。𝜀则是防止除数为0,仅仅是数学计算考虑。
CV领域常用SGDM 、
NLP GAN 强化学习常用Adma















 293
293











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









