









留个笔记自用
FroDO: From Detections to 3D Objects
做什么
3D object detection。3维目标检测

对于输入的3D点云,像2D一样使用一个bounding box去将相应的物体包围起来,不过这里使用的bounding box也同样变成了3维的
做了什么
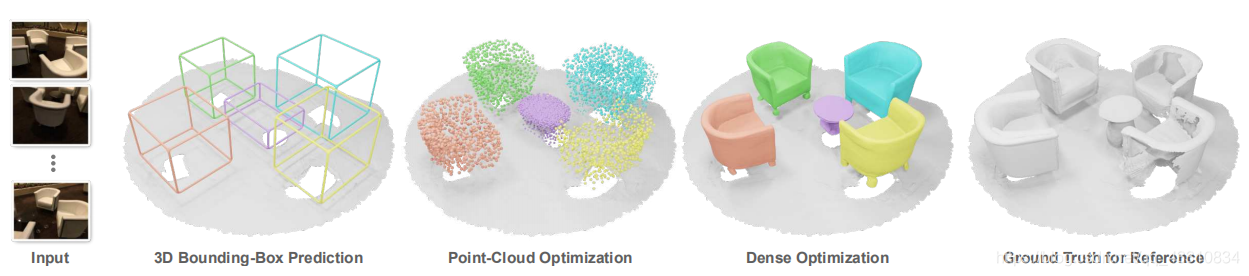
一种从RGB视频中精确重建物体实例的方法,这里的关键是在一个新颖的学习空间中嵌入对象形状,允许在稀疏点云和密集深度之间无缝切换。
怎么做
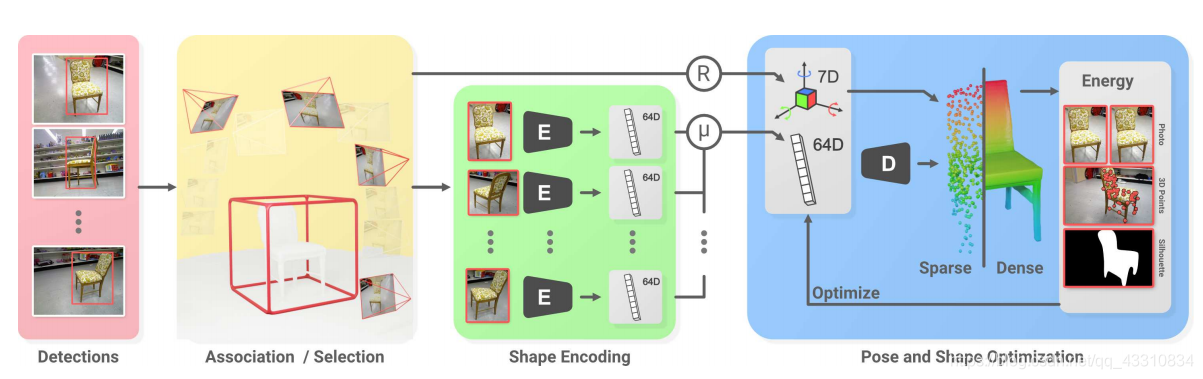
整体结构分为四个部分,Detection部分、Selection部分、Shape encoding部分、Pose and shape optimization(PSO)部分
首先先看看结构整体的流程
这里的输入是一串RGB图片也就是一段视频。第一部分Dection部分使用一个off-the-shelf detector就是现成的目标检测器对输入的图片进行目标检测,可以简单理解成做一个目标向的预处理。
第二部分Selction部分在不同图像中的相同对象实例的检测之间建立对应关系,并且2D包围盒被提升到3D,简单来说就是在一段视频中寻找相同对象然后建立个联系。
第三部分shape encoding部分,将前面检测出来的视频中的2D图片的同一对象使用一个新构建的卷积网络将其编码成64D特征向量,然后融合成一个64D的对象特征码。
最后一个PSO部分,将形状信息和检测信息进行进一步的优化和细化
然后就是具体到部分

首先是第一部分,这里采用的现有网络是mask rcnn,这个网络也是老经典了,使用现有的baseline来获得输入视频的bounding box b和对象mask M。
然后是第二部分,也就是建立不同图像的同一对象间的联系

这里采用的方法和imvotenet相似,同一对象的2D对象框的中心引出的射线必定是3D对象中心的方向,所以来自所有对象对应检测的射线集合应该近似相交,图示↓

然后就可以将寻找对应的问题转换成聚类问题,其目标是识别未知数量的近似相交于单个点的线段集,这里采用了DP-means聚类方法,其中聚类观察值是线段,聚类中心点是3D点
然后聚类结束后,对于每个对象实例k它都会与一串RGB图片联系也就是表示这一串RGB图片中存在这个对象,而RGB图片里提供了检测的bounding box,同时这个k还会对应着一个3D的bounding box,然后通过比较3D对象边界框和2D检测框的投影,拒绝所有低IOU的框
然后是第三部分,得到某一对象k的各个2D图像后,将其输入Shape encoding模块
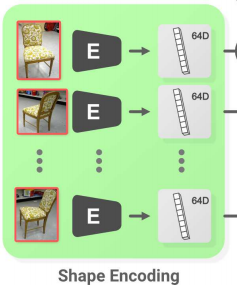
对每一张单个图片encode出一个64D的向量来表示对象形状
这里选用encoder的baseline是resnet,将输出改为嵌入向量大小即64D
然后就是将多个形状向量融合(因为它们属于同一对象)
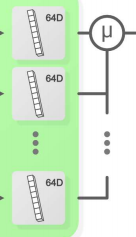
这里提出了两种融合方法,第一种就是对64D向量的每一维直接进行平均,第二种是Majority voting,简单来说就是对每个向量,都在数据集里寻找4个最近邻,被选中也就是当选最近邻次数最多的那一个向量成为最后的vote结果
然后是最后一个部分,PSO部分
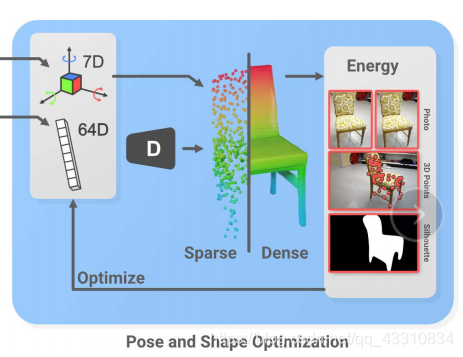
首先,对于每一个对象k,是通过前面得到的64D的形状向量作为输入,经过一个形状解码器得到它的稀疏点云表示(sparse),然后加上前面第二部分得到的它的pose(3D bounding box),穷举旋转矩阵至它符合重力规则立于地面(就是让它放置于地面的方式更加合理)
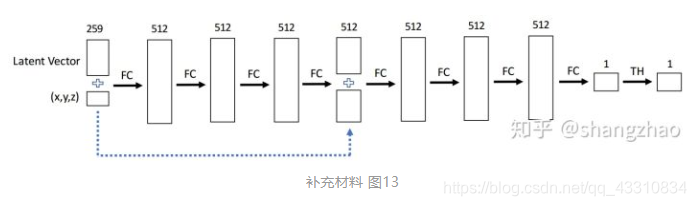
然后将其作为先验,通过deepsdf来得到它的Dense表示(计算点云中每个点的sdf,也就是离散点到surface的距离来进行3D建模),deepsdf↓
然后是训练的LOSS,其实就是energy,这里设计了四个LOSS,2D轮廓LOSS Es,光度一致性LOSS Ep,几何损失LOSS Eg,形状正则化LOSS Er
这里也分为了两个部分,一个是Sparse部分的LOSS,一个是Dense部分的LOSS
首先是Sparse部分的
首先是2D轮廓损失Es,这里是通过当前3D对象形状估计的投影获得的2D轮廓和第一部分用mask预测的的差异进行训练的LOSS
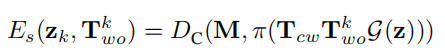
这里的M就是对mask的sample,Tcw是已知的相机pose(自己选定的合适pose),Two是由第二部分的3D bounding box得到的pose,π(x)的意思是将3D点云投影成一张2D图,G就是将64D形状重建为3D稀疏点云的decoder函数,Dc是一种距离计算方式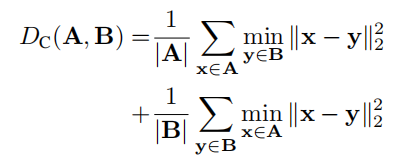
这里的目的就是跟前面设计的一样,为了使直接对2D预测mask得到的轮廓和3D形状预测后再投影得到的轮廓相似
然后是光度损失Ep,鼓励3D点的颜色在各个视图之间保持一致
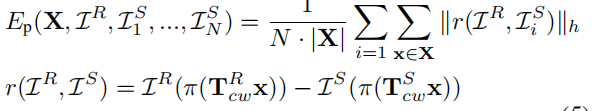
这里的做法在稀疏情况下,通过一个已知的姿态下观察对象,假设当前帧内的点是2048个点云集(标注为X),将其每个点投影至N近邻帧的同一对象上,以对比投影前和投影后的光度差距
这里的IS就是源X,IR就是参考图像就是对比图,所以上面的LOSS含义就是将相邻帧的点云投影至2D图像后,对对比帧之间的逐帧进行对比,为了保证的是稀疏点云下同一对象的光度相似。
最后是几何损失Eg,这里最小化的是形状预测得到的点云和3D SLAM得到的算是GT点云之间的对比
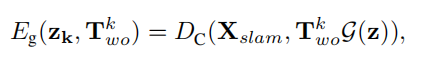
这里的标号均同上
然后是第二部分,Dense部分的LOSS
这里的光度损失Ep和几何损失Eg跟稀疏表示的相同
主要是轮廓损失Es
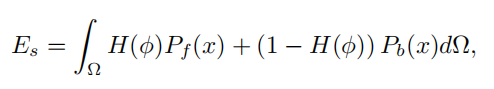
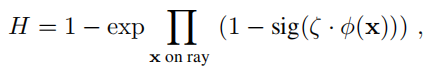
φ是3D或2D形状核,而H是到2D前景概率场的映射,类似于当前状态的对象mask
ζ是一个平滑函数,后面的1-sig部分是得到点x的背景概率,pb是观察的2D点x的背景概率,Pf是2D点x的前景概率
简单来说,根据图像中每个点的前景概率和背景概率来限制3d下点前景和背景的概率,保证3d下轮廓的正确性
总结
1.整体做法上感觉有新意的点是sparse和dense的energy设置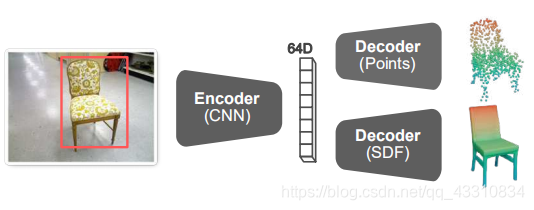
感觉很多地方可以更改,比如64D的shape融合,还有聚类部分

















 4万+
4万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









