






记录一下自己训了个寂寞的多机多卡
之前一直用的
 这个命令来训练,但是发现会出现 RuntimeError:Socket Timeout的错误,找遍全网不知道为啥,或者改为:
这个命令来训练,但是发现会出现 RuntimeError:Socket Timeout的错误,找遍全网不知道为啥,或者改为:
![]()
还是不对。
后来改成

或者

运行正确了,但是其实是每天机器各自执行了一遍单机四卡的,而不是二机四卡的 ,因为我在执行日志里看到了两个loss。
又一次翻遍全网,还是回到了第一个问题。问题详情:
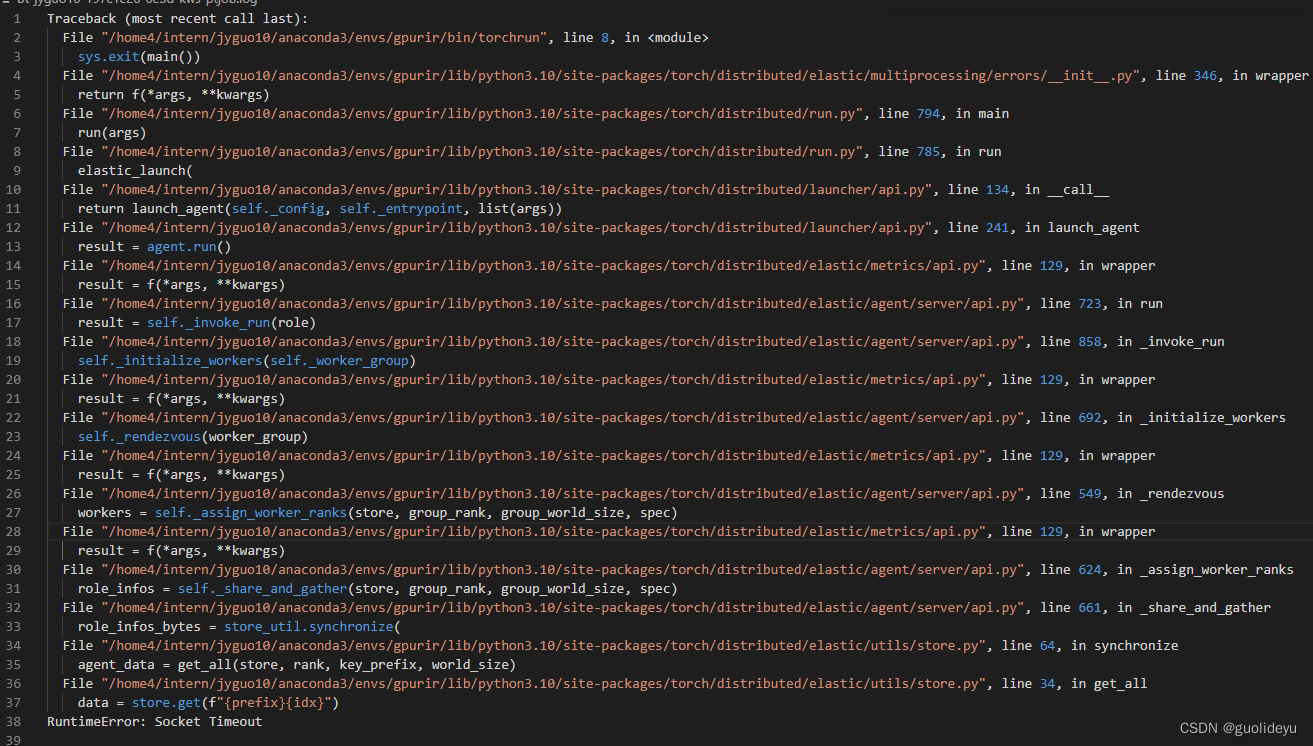
后来在这里:Attribute errors with torch distributed - distributed - PyTorch Forums找到了这段话:
来到了这个网站:torchrun (Elastic Launch) — PyTorch 2.0 documentation
重新写了.sh文件:

终于 成功了!!!!
具体为:
torchrun
--nnodes=$NUM_NODES
--nproc-per-node=$NUM_TRAINERS
--max-restarts=3
--rdzv-id=$JOB_ID
--rdzv-backend=c10d
--rdzv-endpoint=$HOST_NODE_ADDR
YOUR_TRAINING_SCRIPT.py (--arg1 ... train script args...)在网址里有具体说明。感谢天感谢地!终于成了。















 1万+
1万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









