







论文原作者Yuzhe Yang的讲解: https://zhuanlan.zhihu.com/p/369627086.
以前数据不平衡问题主要的解决方案大致两种:
基于数据的解决方案和基于模型的解决方案。
基于数据的解决方案要么对少数群体类别进行过度采样,要么对多数群体进行不足采样,例如SMOTE算法[1],该算法通过线性插值同一类别中的样本来生成少数群体类别的合成样本。 而基于模型的解决方案包括对损失函数的重加权(re-weighting)[2],或是直接修改损失函数[3],以及利用相关的特定学习技巧,例如 transfer learning[4],meta-learning[5],以及 two-stage training[6]。该作者的相关调研https://www.zhihu.com/question/372186043/answer/1501948720.
针对类别不平衡的分类问题(也即长尾分布学习,long-tailed recognition),该作者的调研总结方法(目前主流的方法大致有以下几种(reference只列举出了比较有代表性的)):
1.重采样(re-sampling): 这是解决数据类别不平衡的非常简单而暴力的方法,更具体可以分为两种,对少样本的过采样[1],或是对多样本的欠采样[2]。当然,这类比较经典的方法一般效果都会欠佳,因为过采样容易overfit到minor classes,无法学到更鲁棒易泛化的特征,往往在非常不平衡的数据上泛化性能会更差;而欠采样则会直接造成major class严重的信息损失,甚至会导致欠拟合的现象发生。
2. 数据合成(synthetic samples): 若不想直接重复采样相同样本,一种解决方法是生成和少样本相似的“新”数据。一个最粗暴的方法是直接对少类样本加随机高斯噪声,做data smoothing[3]。此外,此类方法中比较经典的还有SMOTE[4],其思路简单来讲是对任意选取的一个少类的样本,用K近邻选取其相似的样本,通过对样本的线性插值得到新样本。说道这里不禁想到和mixup[5]很相似,都是在input space做数据插值;当然,对于deep model,也可以在representation上做mixup(manifold-mixup)。基于这个思路,最近也有imbalance的mixup版本出现[6]。
3. 重加权(re-weighting): 顾名思义,重加权是对不同类别(甚至不同样本)分配不同权重,主要体现在重加权不同类别的loss来解决长尾分布问题。注意这里的权重可以是自适应的。此类方法的变种有很多,有最简单的按照类别数目的倒数来做加权[7],按照“有效”样本数加权[8],根据样本数优化分类间距的loss加权[9],等等。对于max margin的这类方法,还可以用bayesian对每个样本做uncertainty估计,来refine决策边界[10]。这类方法目前应该是使用的最广泛的,就不贴更多的reference了,可以看一下这个survey paper[3]。
4. 迁移学习(transfer learning): 这类方法的基本思路是对多类样本和少类样本分别建模,将学到的多类样本的信息/表示/知识迁移给少类别使用。代表性文章有[11][12]。
5. 度量学习(metric learning): 本质上是希望能够学到更好的embedding,对少类附近的boundary/margin更好的建模。有兴趣的同学可以看看[13][14]。这里多说一句,除了采用经典的contrastive/triplet loss的思路,最近火起来的contrastive learning,即做instance-level的discrimination,是否也可以整合到不均衡学习的框架中?
6. 元学习/域自适应(meta learning/domain adaptation): 这部分因为文章较少且更新一点,就合并到一起写,最终的目的还是分别对头部和尾部的数据进行不同处理,可以去自适应的学习如何重加权[15],或是formulate成域自适应问题[16]。
7. 解耦特征和分类器(decoupling representation & classifier): 最近的研究发现将特征学习和分类器学习解耦,把不平衡学习分为两个阶段,在特征学习阶段正常采样,在分类器学习阶段平衡采样,可以带来更好的长尾学习结果[17][18]。
参考
1.^Samira Pouyanfar, et al. Dynamic sampling in convolutional neural networks for imbalanced data classification.
2.^He, H. and Garcia, E. A. Learning from imbalanced data. TKDE, 2008.
3.^abP. Branco, L. Torgo, and R. P. Ribeiro. A survey of predictive modeling on imbalanced domains.
4.^Chawla, N. V., et al. SMOTE: synthetic minority oversampling technique. JAIR, 2002.
5.^mixup: Beyond Empirical Risk Minimization. ICLR 2018.
6.^H. Chou et al. Remix: Rebalanced Mixup. 2020.
7.^Deep Imbalanced Learning for Face Recognition and Attribute Prediction. TPAMI, 2019.
8.^Yin Cui, Menglin Jia, Tsung-Yi Lin, Yang Song, and Serge Belongie. Class-balanced loss based on effective number of samples. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, pages 9268–9277, 2019.
9.^Learning Imbalanced Datasets with Label-Distribution-Aware Margin Loss. NeurIPS, 2019.
10.^Striking the Right Balance with Uncertainty. CVPR, 2019.
11^Large-scale long-tailed recognition in an open world. CVPR, 2019.
12.^Feature transfer learning for face recognition with under-represented data. CVPR, 2019.
13.^Range Loss for Deep Face Recognition with Long-Tail. CVPR, 2017.
14.^Learning Deep Representation for Imbalanced Classification. CVPR, 2016.
15.^Meta-Weight-Net: Learning an Explicit Mapping For Sample Weighting. NeurIPS, 2019.
16.^Rethinking Class-Balanced Methods for Long-Tailed Recognition from a Domain Adaptation Perspective. CVPR, 2020.
17.^Decoupling representation and classifier for long-tailed recognition. ICLR, 2020.
18.^BBN: Bilateral-Branch Network with Cumulative Learning for Long-Tailed Visual Recognition. CVPR, 2020
论文题目《Delving into Deep Imbalanced Regression》
解决的问题:
数据不平衡在现实世界中是无处不在。现实数据通常不会是每个类别都具有理想的均匀分布,而是呈现出尾巴较长的偏斜分布,其中某些目标值的观测值明显较少。major类过拟合,minor类欠拟合。
摘要
真实世界的数据往往呈现出不平衡的分布,其中某些目标值有明显较少的观察。现有的处理不平衡数据的技术侧重于具有分类指标的目标,即不同的类别。然而,许多任务都涉及到连续的目标,在这种情况下,类之间并不存在硬边界。我们将 深度不平衡回归(Deep Imbalanced Regression, DIR)定义为对具有连续目标的不平衡数据进行学习,处理特定目标值的潜在缺失数据,并将其推广到整个目标范围。 基于分类标签空间和连续标签空间之间的内在差异,我们提出了 标签分布平滑 和 特征分布平滑 ,明确承认附近目标的影响,并校准标签和学习的特征分布 。我们从计算机视觉、自然语言处理和医疗保健领域的常见现实任务中筛选和测试大规模DIR数据集。大量的实验证明了我们的策略的优越性能。我们的工作填补了实际的不平衡回归问题的基准和技术的空白。
1、研究背景与动机
在现实世界中,数据不平衡是普遍存在和固有的。数据往往呈现出带有长尾的偏态分布(Buda et al., 2018;Liu et al., 2019),其中某些目标值具有明显较少的观测值。这种现象给深度识别模型带来了巨大的挑战,并激发了许多以前解决数据不平衡的技术(Cao等人,2019;Cui et al., 2019;Huang et al., 2019;Liu et al., 2019;Tang et al., 2020)。
然而,现有的不平衡数据学习解决方案都侧重于具有分类指标的目标,即目标是不同的类别。然而,许多现实世界的任务涉及连续的甚至是无限的目标值。 例如,在视觉应用中,人们需要根据不同人的视觉外观来推断他们的年龄,而年龄是一个连续的目标,可能是高度不平衡的。把不同年龄的人当作不同的阶层来对待不太可能产生最好的结果,因为它没有利用年龄相近的人之间的相似性。 在医疗应用中也会出现类似的问题,因为许多健康指标,包括心率、血压和氧饱和度,都是连续的,而且在患者人群中分布往往是倾斜的。

在本工作中,我们系统地研究了现实世界中产生的深度不平衡回归(DIR)(见图1)。我们将DIR定义为从自然不平衡数据中学习连续目标,处理某些目标值的潜在丢失数据,并将其推广到在整个连续目标值范围内平衡的测试集。这个定义类似于类失衡问题(Liu et al., 2019),但重点是连续设置。DIR带来了不同于分类版本的新挑战。首先,给定连续的(可能是无限的)目标值,类之间的硬边界不再存在,直接应用重采样和重加权等传统的不平衡分类方法会造成模糊性。此外,此外,连续标签固有地在目标之间具有有意义的距离,这对于我们应该如何解释数据不平衡具有重要意义。例如,假设两个目标标签t1和t2在训练数据中有少量观察值。然而,t1位于一个高度代表性的邻域中(即,在[t1]范围内有许多样本)− ∆, t1∆]), 而t2位于一个弱表示的邻域中。在这种情况下,t1与t2的不平衡程度不同。最后,与分类不同,某些目标值可能根本没有数据,这促使需要进行目标外推&插值。

在本文中,我们提出了两种简单而有效的解决DIR的方法: 标签分布平滑(LDS)和特征分布平滑(FDS)。两种方法背后的一个关键思想是 利用附近目标之间的相似性,通过使用核分布在标签和特征空间中执行显式分布平滑。这两种技术都可以很容易地嵌入到现有的深层网络中,并允许以端到端方式进行优化。我们证实,我们的技术不仅成功地校准了内在的潜在不平衡,而且当与其他方法结合时,还提供了巨大和一致的收益。
为了支持不平衡回归的实际评估,我们为计算机视觉、自然语言处理和医疗保健领域的常见现实任务筛选和测试大规模DIR数据集。它们的范围从单值预测(如年龄)、文本相似度得分、健康状况得分,到密集值预测(如深度)。我们进一步设立适当的DIR绩效评估基准。
我们的贡献如下:
- 我们将DIR任务正式定义为从具有连续目标的不平衡数据中学习,并将其推广到整个目标范围。DIR提供全面和公正的评估学习算法在实际设置。
- 为了DIR,我们开发了两种简单、有效、可解释的LDS和FDS算法,利用标签和特征空间中邻近目标之间的相似性。
- 我们管理不同领域的基准DIR数据集:计算机视觉、自然语言处理和医疗保健。我们为适当的DIR绩效评估建立了强有力的基线和基准。
- 大规模DIR数据集上的广泛实验验证了我们的策略的一致性和卓越性能。
2、相关工作
不平衡的分类。 之前的很多工作都集中在不平衡分类问题(也称为长尾识别(Liu et al., 2019))上。过去的解决方案可以分为 基于数据的解决方案和基于模型的解决方案:基于数据的解决方案要么是对少数群体过度采样,要么是对多数群体样本不足(Chawla et al., 2002;garcia´ıa & Herrera, 2009;他等人,2008)。例如,SMOTE通过线性插值同一类中的样本生成少数类的合成样本(Chawla et al., 2002)。基于模型的解决方案包括重新加权或调整损失函数以补偿阶级失衡(Cao et al., 2019;Cui et al., 2019;Dong et al., 2019;Huang et al., 2016;2019)并利用相关学习范式,包括迁移学习(Yin et al., 2019)、度量学习(Zhang et al., 2017)、元学习(Shu et al., 2019)和两阶段训练(Kang et al., 2020)。最近的研究也发现,半监督学习和自监督学习会导致更好的不平衡分类结果(Yang & Xu, 2020)。与过去的工作相比,我们发现了将类不平衡方法应用于回归问题的局限性,并引入了特别适合于学习连续目标值的新技术。
不平衡的回归。 对不平衡数据的回归没有进行很好的探讨。关于这个主题的大部分工作都是直接将SMOTE算法调整到回归场景(Branco等人,2017;2018;Torgo等人,2013)。通过直接插值输入和目标(Torgo et al., 2013)或使用高斯噪声增强(Branco et al., 2017),可以为预定义的稀有目标区域创建合成样本。还引入了一种bagging-based的集成方法,该方法包含多个数据预处理步骤(Branco et al., 2018)。然而,这些方法存在一些内在的缺陷。首先,他们没有考虑目标之间的距离,而是启发式地将数据集划分为稀有集和频繁集,然后插入基于分类的方法。此外,现代数据具有极高的维度(如图像和生理信号);这类数据的两个样本的线性插值不会产生有意义的新合成样本。我们的方法在方法上与过去的工作本质上是不同的。它们可以与现有的方法相结合以提高性能,如我们在第4节所示。此外,我们的方法在计算机视觉、NLP和医疗保健领域的大规模真实数据集上进行了测试。
3、方法

问题设置。 设{(xi, yi)}N i=1为训练集,其中xi∈rd表示输入,yi∈R为标号,是一个连续目标。我们为标签空间Y引入了一个额外的结构,我们将Y分成B组(箱子),间隔相等,即,[y0, y1),[y1, y2),…, (yB−1、yB)。在整篇文章中,我们用b∈b表示目标的组索引,其中b ={1,…, B}⊂Z+是索引空间。在实践中,定义的容器反映了我们在回归任务中对数据进行分组时所关心的最小分辨率。例如,在年龄估计中,我们可以定义δy, yb+1−yb= 1,表明最小年龄差为1是有趣的。最后,我们将z = f(x;θ)表示为x的特征,其中f(x;θ)由一个含参数θ的深度神经网络模型参数化。最终的预测ˆy是由一个在z上运行的回归函数g(·)给出的。
3.1. 标签分布平滑
我们首先展示一个例子来说明当出现不平衡时分类和回归之间的区别。

Motivating Example. 我们使用两个数据集:(1)CIFAR100 (Krizhevsky et al., 2009),这是一个100类分类数据集,(2)IMDB-WIKI数据集(Rothe et al., 2018),这是一个大规模图像数据集,用于从视觉外观估计年龄。这两个数据集具有本质上不同的标签空间:CIFAR-100是分类标签空间,目标是类索引,而IMDB-WIKI是连续标签空间,目标是年龄。我们将年龄范围限制在0 ~ 99,使两个数据集具有相同的标签范围,并对它们进行子抽样,以模拟数据不平衡,同时确保它们具有完全相同的标签密度分布(图2)。我们使两个测试集均衡。然后我们在两个数据集上训练一个普通的ResNet-50模型,并绘制它们的测试误差分布。
由图2(a)可知,误差分布与标签密度分布相关。具体来说,测试误差作为类指标的函数,与类别标签空间中的标签密度分布(即−0.76)存在高度负皮尔逊相关。这种现象是预料之中的,因为样本更多的多数班比少数班学习得更好。但有趣的是,从图2(b)可以看出,即使标签密度分布与CIFAR-100相同,连续标签空间下IMDB-WIKI的误差分布也有很大的不同。特别是,误差分布更加平滑,不再与标签密度分布(−0.47)有很好的相关性。
这个例子之所以有趣,是因为所有的不平衡学习方法,直接或间接地,都是通过补偿经验标签密度分布的不平衡来运作的。这对于类别不平衡很有效,但是对于连续的标签,经验密度并不能准确地反映神经网络所看到的不平衡。因此,基于经验标签密度的数据不平衡补偿对于连续标签空间是不准确的。

不平衡数据密度估计的LDS
由上面的例子可以看出,在连续情况下,经验的标签分布并不能反映真实的标签密度分布。这是因为邻近标签(例如,相近年龄的图像)的数据样本之间的依赖性。事实上,有一个重要的统计文献是关于如何估计这种情况下的预期密度(Parzen, 1962)。因此,标签分布平滑(LDS)提倡使用核密度估计来学习连续目标对应的数据集中的有效不平衡。
LDS将对称核与经验密度分布进行卷积,提取核平滑版本,解决邻近标签数据样本信息重叠的问题。对称核是任意满足k(y, y’) = k(y’, y)和∇yk(y, y’) +∇y’k(y’, y) = 0,∀y, y’∈y的核。注意,高斯核或拉普拉斯核是对称核,而k(y, y’) = yy’不是。对称核函数描述了目标值y’与目标空间中任意y的距离之间的相似性。因此,LDS计算的有效标签密度分布为:
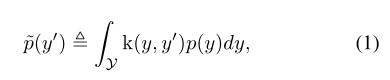
其中p(y)为y标签在训练数据中出现的次数。p(y’)是标签y’的有效密度。
图3显示了LDS和它如何平滑标签密度分布。进一步表明,由LDS计算得到的标签密度与误差分布(−0.83)有很好的相关性。这表明LDS捕获了影响回归问题的真正不平衡。
既然有了有效的标签密度,那么解决类不平衡问题的技术可以直接适应DIR上下文。例如,一个直接的适应方法可以是成本敏感的重新加权方法,我们通过将损失函数乘以每个目标LDS估计的标签密度的倒数来重新加权损失函数。我们在第4节中展示了LDS可以与广泛的技术无缝结合,以提高DIR性能。
3.2. 特征分布平滑
我们的动机是直觉,即目标空间中的连续性应在特征空间中创建相应的连续性。也就是说,如果模型工作正常且数据平衡,则期望与附近目标相对应的特征统计数据彼此接近。

Motivating Example. 我们使用一个说明性示例来突出显示DIR中数据不平衡对特性统计的影响。同样,我们使用一个经过IMDB-WIKI数据集训练的普通模型,从一个人的视觉外观推断出他的年龄。我们专注于学习的特征空间,即z。我们使用最小的bin大小为1,即yb+1−yb= 1,并将具有相同目标值的特征分组在同一bin中。然后计算每个箱子里数据的特征统计量(即均值和方差),我们用{µb,σb} b b=1表示。为了可视化特征统计数据之间的相似度,我们选择一个锚仓b0,并计算b0与所有其他容器之间特征统计数据的余弦相似度。图4总结了b0= 30时的结果。图中还用紫色、黄色和粉色显示了不同数据密度的区域。
从图4可以看出,b0= 30前后的特征统计量与b0= 30时的特征统计量高度相似。具体来说,25到35岁之间所有箱子的特征均值和特征方差的余弦相似度与它们在30岁(锚定年龄)时的值相差几个百分点。而且,当锚周围的距离越小,相似度越高。请注意30号仓落在高处。事实上,它是拥有最多样本的少数箱子之一。因此,图证实了直觉,当有足够的数据时,对于连续的目标,特征统计类似于附近的bins。有趣的是,这张图也显示了数据样本很少的地区的问题,比如0到6岁(用粉色表示)。注意,这个范围的平均值和方差显示出出乎意料的与30岁高度相似。事实上,令人震惊的是,30岁的特征统计数据更接近于1岁,而不是17岁。这种不合理的相似性是由于数据不平衡造成的。具体来说,由于没有足够的0到6岁的图像,这个范围因此从数据量最大的范围继承了它的先验值,也就是30岁左右的范围。
FDS算法 受到这些观察结果的启发,我们提出了特征分布平滑(feature distribution smoothing, FDS),它对特征空间进行分布平滑,即在邻近的目标容器之间传输特征统计量。这个程序的目的是校准特征分布的潜在偏差估计,特别是训练数据中未充分表示的目标值(例如,中镜头和少镜头组)。FDS是通过首先估计每个容器的统计信息来执行的。在不失一般性的前提下,我们用特征的协方差代替方差,以反映特征 z 内部元素之间的关系。
给定特征统计量,我们再次使用对称核函数 symmetric kernel k 来 smooth 特征均值和协方差的分布。这样我们可以拿到统计信息的平滑版本。现在,利用估计的和平滑的统计量,我们遵循标准的 whitening and re-coloring[10] 过程来校准每个输入样本的特征表示。那么整个FDS的过程可以通过在最终特征图之后插入一个特征的校准层,来实现将FDS的集成到深度网络中。最后,我们在每个epoch 采用了对于 running statistics的 momentum update,也就是动量更新。这个是为了获得对训练过程中特征统计信息的一个更稳定和更准确的估计。

4、基准DIR数据集
Datasets. 我们策划了五个DIR基准,涵盖计算机视觉、自然语言处理和医疗保健。图6显示了这些数据集的标签密度分布及其不平衡程度。

- IMDB-WIKI-DIR(vision,age):从包含人面部的图像来推断估计相应的年龄。基于IMDB-WIKI[9]数据集,我们手动构建了验证集和测试集,使其保持了分布的平衡。
- AgeDB-DIR(vision,age):同样是根据单个输入图像进行年龄估算,基于AgeDB[11]数据集。注意到与IMDB-WIKI-DIR相比,即使两个数据集是完全相同的task,他们的标签分布的不平衡也不相同。
- NYUD2-DIR(vision, depth):除了single value的prediction,我们还基于NYU2数据集[12]构建了进行depth estimation的DIR任务,是一个dense value prediction的任务。我们构建了NYUD2-DIR数据集来进行不平衡回归的评估。
- STS-B-DIR(NLP, text similarity score):我们还在NLP领域中构建了一个叫STS-B-DIR的DIR benchmark,基于STS-B数据集[13]。他的任务是推断两个输入句子之间的语义文本的相似度得分。这个相似度分数是连续的,范围是0到5,并且分布不平衡。
- SHHS-DIR(Healthcare, health conditionscore):最后,我们在healthcare领域也构建了一个DIR的benchmark,叫做SHHS-DIR,基于SHHS数据集[14]。这项任务是推断一个人的总体健康评分,该评分在0到100之间连续分布,评分越高则健康状况越好。网络的输入是每个患者在一整晚睡眠过程中的高维PSG信号,包括ECG心电信号,EEG脑电信号,以及他的呼吸信号。很明显可以看到,总体健康分数的分布也是极度不平衡的,并存在一定的target value是没有数据的。
Network Architectures. 我们使用ResNet-50 (He et al., 2016)作为IMDB-WIKI-DIR和AgeDB-DIR的骨干网络。接下来(Wang et al., 2018),我们对STSB-DIR采用相同的BiLSTM + GloV e词嵌入基线。对于NYUD2-DIR,我们使用了(Hu et al., 2019)中引入的基于resnet -50的编解码器架构。最后,对于SHHS-DIR,我们使用与(Wang et al., 2019)相同的CNN-RNN结构和ResNet块用于PSG信号。
Baselines. 由于文献中关于DIR的建议很少,加上过去关于不平衡回归的工作(Branco et al., 2017;Torgo et al., 2013),我们采用了一些不平衡的分类方法进行回归,并提出了一组较强的基线。下面,我们将描述基线,以及如何将LDS与每种方法结合起来。对于FDS,它可以直接与任何基线集成作为校准层,如章节3.2所述。
- Vanilla model: 我们使用术语Vanilla来表示一个不包含任何处理不平衡数据的技术的模型。为了将Vanilla model与LDS结合,我们将损失函数乘以每个目标bin的LDS估计密度的逆来重新加权。
- Synthetic samples: 我们选择现有的不平衡回归方法,包括SMOTER (Torgo et al., 2013)和SMOGN(Branco et al., 2017)。SMOTER首先使用原始标签密度定义频繁区域和罕见区域,然后通过线性插值输入和目标为预定义罕见区域创建合成样本。SMOGN进一步向SMOTER添加高斯噪声。我们注意到,在分割目标空间时,LDS可以直接用于更好地估计标签密度。
- Error-aware loss: 受Focal loss (Lin et al., 2017)的启发,我们提出了一种称为Focal- R的回归版本,其中缩放因子被一个连续函数代替,将绝对误差映射到[0,1]。精确地说,基于L1 distance的Focal-R损耗可以表示为1npn i=1σ(|βei|)γei,其中eii为第i个样本的L1error, σ(·)为Sigmoid函数,β, γ为超参数。为了将Focal-R与LDS相结合,我们将损耗与估计的标签密度的逆频率相乘。
- Two-stage training: 继(Kang等人,2020年)将特征和分类器分为两个阶段进行解耦和训练之后,我们提出了一种称为回归器重新训练(RRT)的回归版本,其中在第一阶段我们正常训练编码器,在第二阶段冻结编码器并用反向重新加权重新训练回归器g(·)。添加LDS时,第二阶段中的重新加权基于通过LDS估计的标签密度。
- Cost-sensitive re-weighting: 由于我们将目标空间划分为有限个箱子,因此可以直接插入经典的重新加权方法。我们采用了两种基于标签分布的重加权方案:逆频率加权(INV)及其平方根加权变量(SQINV)。当与LDS结合时,我们使用LDS估计的目标密度,而不是使用原始标签密度。
评估过程和指标。 在评估过程中,我们在平衡的测试集上评估每种方法的性能。我们进一步将目标空间划分为几个不相交的子集:称为many-shot,medium-shot,few-shot,还有zero-shot region,来反映训练数据中样本数量的不同。比如,many-shot代表对于这个固定的区间,有超过100个training data sample,medium-shot(包含20∼100个training data sample)和few-shot(training data sample少于20个)。报告这些子集的结果以及总体性能。4.2.对于指标,我们使用常用的回归指标,如平均误差(MAE)、均方误差(MSE)和皮尔逊相关性。我们进一步提出了另一个度量,称为误差几何平均值(GM),为了更好的预测公平性,将其定义为(QNI=1ei)1N。
4.1. 实验结果
我们在本节中报告了所有DIR数据集的主要结果。
从图像推断年龄: IMDB-WIKI-DIR& AgeDB DIR。 我们在表1和表2中分别报告了不同方法的性能。对于每个数据集,我们将基线分为四个部分,以反映其不同的策略。首先,正如两个表所示,当应用于现代高维数据(如图像)时,与普通模型相比,SMOTER和SMOGN实际上会降低性能。此外,在每个组中,添加LDS、FDS或两者都可以提高性能,而LDS-FDS通常可以获得最佳效果。最后,与普通模式相比,使用我们的LDS和FDS可以保持或略微提高总体性能和多镜头区域的性能,同时显著提高中镜头和少镜头区域的性能。


4.2. 结果分析

Extrapolation & Interpolation. 在真实的DIR任务中,某些目标值可能根本没有数据(例如,参见图6中的SHHSDIR和STS-B-DIR)。这激发了对目标外推和插值的需求。我们从IMDB-WIKI-DIR的训练集中整理出一个子集,它在某些区域中没有训练数据(图7),但在原始测试集上进行评估,以进行zero-shot 综合分析。
如表6所示,与普通模型相比,LDS和FDS不仅可以改善有数据区域的结果,还可以在无数据区域获得更大的收益。具体而言,目标插值和外推都有了实质性的改进,其中插值的提升幅度更大。
我们在图7中进一步展示了我们的方法相对于Vanilla model的绝对MAE增益。我们的方法提供了对多、中、少以及zero-shot region的综合处理,实现了显著的性能提升。

Understanding FDS. 我们研究了FDS是如何影响特征统计的。在图8(a)和图8(b)中,我们绘制了anchor age 0的特征统计的相似度,使用的是未使用FDS训练的模型和使用FDS训练的模型。从图中可以看出,由于年龄0位于 few-shot region,特征统计会有较大的偏差,即年龄0与图8(a)中40 ~ 80区域有较大的相似性。而加入FDS后,统计数据得到了更好的校准,仅在其邻域相似性较高,相似性评分随着目标值的增大而逐渐降低。如图8©所示,我们进一步将训练时的运行统计信息{µb,Σb}与经过平滑的统计信息{µb, eΣb}之间的L1 distance 可视化。有趣的是,平均L1 distance会随着训练的发展而变小,并逐渐减小,这表明模型学习生成更精确的特征,即使没有平滑,最终平滑模块可以在推理过程中移除。

5、结论
我们引入了DIR任务,它从具有连续目标的自然不平衡数据中学习,并将其推广到整个目标范围。我们提出了两种简单有效的DIR算法,利用标签和特征空间中邻近目标之间的相似性。在五个精心策划的大规模真实世界DIR基准测试上的广泛结果证实了我们的方法的优越性能。我们的工作填补了实际DIR任务的基准和技术方面的空白
算法附录:
















 1086
1086











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









