







2022/05/26,27,31
Delving into Deep Imbalanced Regression
连续分布的不平衡
Real-world data often exhibit imbalanced distributions, where certain target values have significantly fewer observations.
Existing techniques for dealing with imbalanced data focus on targets with categorical indices, i.e., different classes.
However, many tasks involve continuous targets, where hard boundaries between classes do not exist.
This causes ambiguity when directly applying traditional imbalanced classification methods such as re-sampling and re-weighting.
Moreover, continuous labels inherently possess a meaningful distance between targets, which has implication for how we should interpret data imbalance.
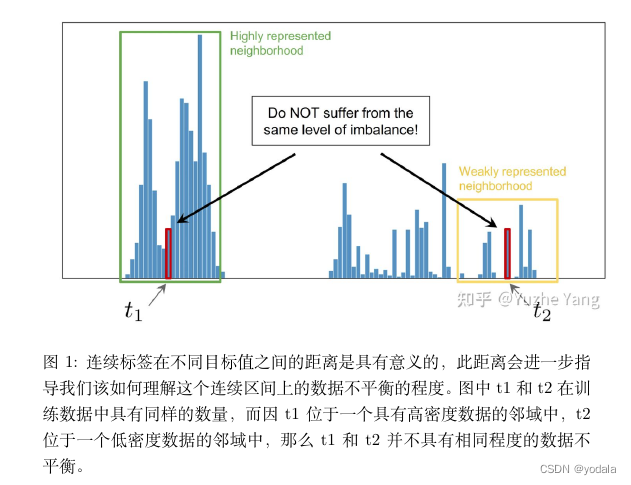
怎么解决不平衡
- 重采样(re-sampling):这是解决数据类别不平衡的非常简单而暴力的方法,更具体可以分为两种,对少样本的过采样,或是对多样本的欠采样。当然,这类比较经典的方法一般效果都会欠佳,因为过采样容易overfit到minor classes,无法学到更鲁棒易泛化的特征,往往在非常不平衡的数据上泛化性能会更差;而欠采样则会直接造成major class严重的信息损失,甚至会导致欠拟合的现象发生。
- 数据合成(synthetic samples):若不想直接重复采样相同样本,一种解决方法是生成和少样本相似的“新”数据。一个最粗暴的方法是直接对少类样本加随机高斯噪声,做data smoothing。此外,此类方法中比较经典的还有SMOTE,其思路简单来讲是对任意选取的一个少类的样本,用K近邻选取其相似的样本,通过对样本的线性插值得到新样本。
- 重加权(re-weighting):顾名思义,重加权是对不同类别(甚至不同样本)分配不同权重,主要体现在重加权不同类别的loss来解决长尾分布问题。注意这里的权重可以是自适应的。此类方法的变种有很多,有最简单的按照类别数目的倒数来做加权,按照“有效”样本数加权,根据样本数优化分类间距的loss加权,等等。
- 迁移学习(transfer learning):这类方法的基本思路是对多类样本和少类样本分别建模,将学到的多类样本的信息/表示/知识迁移给少类别使用。
- 解耦特征和分类器(decoupling representation and classifier):最近的研究发现将特征学习和分类器学习解耦,把不平衡学习分为两个阶段,在特征学习阶段正常采样,在分类器学习阶段平衡采样,可以带来更好的长尾学习结果。
连续分布的不平衡
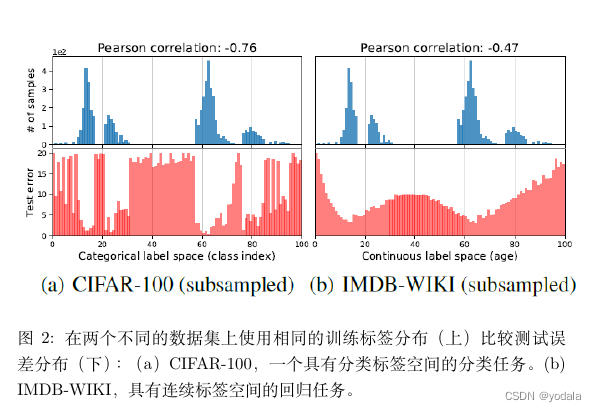
由图2 可以得出,对于连续标签,其经验标签密度(empirical label density),也就是直接观测到的标签密度,不能准确反映模型或神经网络所看到的不平衡。
因此,在连续的情况下,empirical label density是不能反映实际的标签密度分布。
这是由于相临近标签(例如,年龄接近的图像)的数据样本之间是具有相关性,或是互相依赖的。
Label Distribution Smoothing
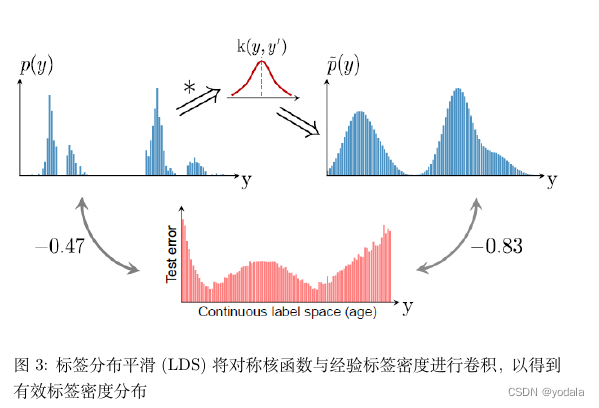
This paper proposes Label Distribution Smoothing (LDS) ,来估计在连续标签情况下的有效的 label density distribution。
该方法参考了在统计学习领域中的核密度估计,kernel density estimation 的思路,来在这种情况下估计 expected density。
具体而言,给定连续的经验标签密度分布,LDS 使用了一个 symmetric kernel distribution 对称核函数
k
k
k ,用经验密度分布与之进行卷积,来拿到一个 kernel-smoothed 的版本,称之为 effective label density,也就是有效的标签密度,用来直观体现临近标签的数据样本具有的信息重叠的问题。
k
(
y
,
y
′
)
=
k
(
y
′
,
y
)
,
∇
y
k
(
y
,
y
′
)
+
∇
y
′
k
(
y
′
,
y
)
=
0
,
∀
y
,
y
′
∈
Y
\mathrm{k}\left(y, y^{\prime}\right)=\mathrm{k}\left(y^{\prime}, y\right), \nabla_{y} \mathrm{k}\left(y, y^{\prime}\right)+\nabla_{y^{\prime}} \mathrm{k}\left(y^{\prime}, y\right)=0, \forall y, y^{\prime} \in \mathcal{Y}
k(y,y′)=k(y′,y),∇yk(y,y′)+∇y′k(y′,y)=0,∀y,y′∈Y
p
~
(
y
′
)
≜
∫
Y
k
(
y
,
y
′
)
p
(
y
)
d
y
\tilde{p}\left(y^{\prime}\right) \triangleq \int_{\mathcal{Y}} \mathrm{k}\left(y, y^{\prime}\right) p(y) d y
p~(y′)≜∫Yk(y,y′)p(y)dy
where
p
(
y
)
p(y)
p(y) is the number of appearances of label of
y
y
y in the training data, and
p
~
(
y
′
)
\tilde{p}(y^{\prime})
p~(y′) is the effective density of label
y
′
y^{\prime}
y′.
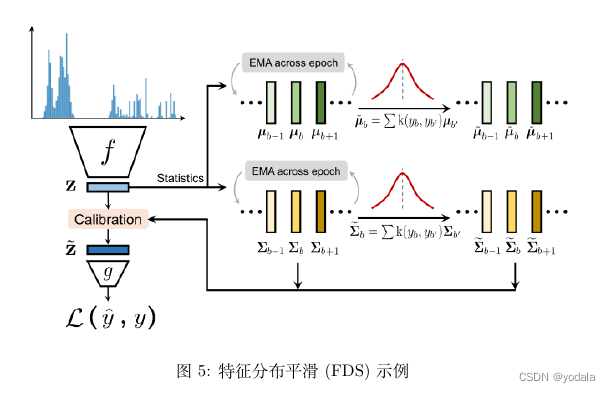
Feature Distribution Smoothing
目标空间中的连续性应该在特征空间中创建相应的连续性。也就是说,如果模型工作正常且数据平衡,那么目标与目标附近相对应的特征统计信息彼此接近。
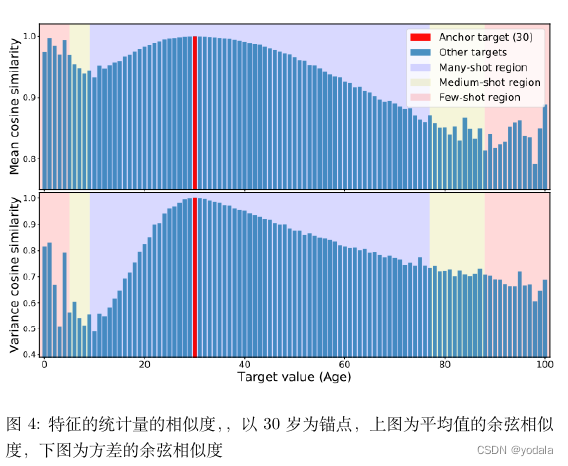
年龄范围0到6岁(以粉红色显示)此范围内的平均值和方差与30岁的人有出人意料的高度相似性。与17岁相比,30岁时的特征统计数据更接近1岁。这种不合理的相似性是由于数据不平衡造成的。具体而言,由于没有足够的图像用于0到6岁的年龄段,因此此范围从数据量最大的范围(即30岁左右的范围)继承其先验值。
μ
b
=
1
N
b
∑
i
=
1
N
b
z
i
Σ
b
=
1
N
b
−
1
∑
i
=
1
N
b
(
z
i
−
μ
b
)
(
z
i
−
μ
b
)
⊤
\begin{aligned} \boldsymbol{\mu}_{b} &=\frac{1}{N_{b}} \sum_{i=1}^{N_{b}} \mathbf{z}_{i} \\ \boldsymbol{\Sigma}_{b} &=\frac{1}{N_{b}-1} \sum_{i=1}^{N_{b}}\left(\mathbf{z}_{i}-\boldsymbol{\mu}_{b}\right)\left(\mathbf{z}_{i}-\boldsymbol{\mu}_{b}\right)^{\top} \end{aligned}
μbΣb=Nb1i=1∑Nbzi=Nb−11i=1∑Nb(zi−μb)(zi−μb)⊤
不失一般性,用协方差代替方差,以反映特征之间的关系。
μ
~
b
=
∑
b
′
∈
B
k
(
y
b
,
y
b
′
)
μ
b
′
\begin{aligned} \tilde{\boldsymbol{\mu}}_{b} &=\sum_{b^{\prime} \in \mathcal{B}} \mathrm{k}\left(y_{b}, y_{b^{\prime}}\right) \boldsymbol{\mu}_{b^{\prime}} \end{aligned}
μ~b=b′∈B∑k(yb,yb′)μb′
Σ
~
b
=
∑
b
′
∈
B
k
(
y
b
,
y
b
′
)
Σ
b
′
\begin{aligned} \widetilde{\boldsymbol{\Sigma}}_{b} &=\sum_{b^{\prime} \in \mathcal{B}} \mathrm{k}\left(y_{b}, y_{b^{\prime}}\right) \boldsymbol{\Sigma}_{b^{\prime}} \end{aligned}
Σ
b=b′∈B∑k(yb,yb′)Σb′
再次使用对称核
k
k
k来平滑特征均值和协方差。
结果
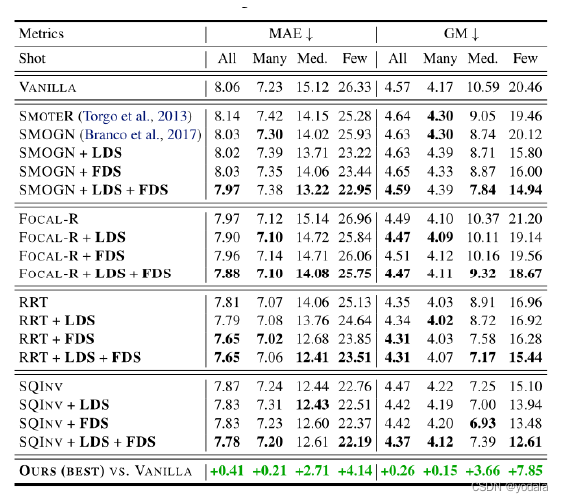
vanilla来表示一个模型,该模型不包括任何处理不平衡数据的技术。
为了将vanilla模型与LDS相结合,通过将损失函数乘以每个目标箱的LDS估计密度的倒数来重新加权损失函数。
与FDS的结合则是把该方法结合到特征的提取之后,在做最后的回归之前,即使用FDS对提取的特征进行一个修正。
总结
提出了一个新的任务,称为深度不平衡回归(DIR),系统性地研究了DIR,并提出了对应的简单而有效的新方法LDS和FDS,以解决具有连续目标的学习不平衡数据的问题。
问题
本文所描述的不平衡问题是否适用于标签分布学习?















 172
172











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









