






labelme使用教程
1 Labelme安装
1.1 打开Anaconda3自带的Anaconda Prompt

1.2 创建一个虚拟的py环境:
conda create –name=labelme python=3.7
1.3 安装pyqt:
conda install pyqt
1.4 安装labelme:
pip install labelme==3.16.2 -I https://pypi.tuna.tsinghua.edu.cn/simple
pip install labelme -I https://pypi.tuna.tsinghua.edu.cn/simple
(安装特定版本是为了将背景转换为二值图做铺垫,不然会报错的)
1.5 启动
打开Anaconda Prompt,然后输入activate labelme
然后输入Labelme


2 实现labelme批量json_to_dataset方法
2.1 修改json_to_dataset.py代码
在lableme安装目录下有D:\Anaconda\Lib\site-packages\labelme\cli目录,可以看到json_to_dataset.py文件
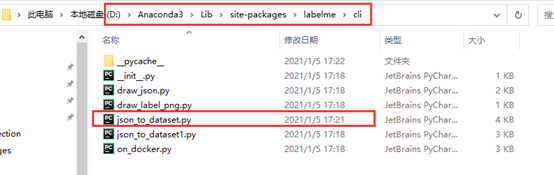
复制json_to_dataset.py文件,代码更改:
import argparse
import json
import os
import os.path as osp
import warnings
import PIL.Image
import yaml
from labelme import utils
import base64
def main():
warnings.warn("This script is aimed to demonstrate how to convert the\n"
"JSON file to a single image dataset, and not to handle\n"
"multiple JSON files to generate a real-use dataset.")
parser = argparse.ArgumentParser()
parser.add_argument('json_file')
parser.add_argument('-o', '--out', default=None)
args = parser.parse_args()
json_file = args.json_file
if args.out is None:
out_dir = osp.basename(json_file).replace('.', '_')
out_dir = osp.join(osp.dirname(json_file), out_dir)
else:
out_dir = args.out
if not osp.exists(out_dir):
os.mkdir(out_dir)
count = os.listdir(json_file)
for i in range(0, len(count)):
path = os.path.join(json_file, count[i])
if os.path.isfile(path):
data = json.load(open(path))
if data['imageData']:
imageData = data['imageData']
else:
imagePath = os.path.join(os.path.dirname(path), data['imagePath'])
with open(imagePath, 'rb') as f:
imageData = f.read()
imageData = base64.b64encode(imageData).decode('utf-8')
img = utils.img_b64_to_arr(imageData)
label_name_to_value = {'_background_': 0}
for shape in data['shapes']:
label_name = shape['label']
if label_name in label_name_to_value:
label_value = label_name_to_value[label_name]
else:
label_value = len(label_name_to_value)
label_name_to_value[label_name] = label_value
# label_values must be dense
label_values, label_names = [], []
for ln, lv in sorted(label_name_to_value.items(), key=lambda x: x[1]):
label_values.append(lv)
label_names.append(ln)
assert label_values == list(range(len(label_values)))
lbl = utils.shapes_to_label(img.shape, data['shapes'], label_name_to_value)
captions = ['{}: {}'.format(lv, ln)
for ln, lv in label_name_to_value.items()]
lbl_viz = utils.draw_label(lbl, img, captions)
out_dir = osp.basename(count[i]).replace('.', '_')
out_dir = osp.join(osp.dirname(count[i]), out_dir)
if not osp.exists(out_dir):
os.mkdir(out_dir)
PIL.Image.fromarray(img).save(osp.join(out_dir, 'img.png'))
#PIL.Image.fromarray(lbl).save(osp.join(out_dir, 'label.png'))
utils.lblsave(osp.join(out_dir, 'label.png'), lbl)
PIL.Image.fromarray(lbl_viz).save(osp.join(out_dir, 'label_viz.png'))
with open(osp.join(out_dir, 'label_names.txt'), 'w') as f:
for lbl_name in label_names:
f.write(lbl_name + '\n')
warnings.warn('info.yaml is being replaced by label_names.txt')
info = dict(label_names=label_names)
with open(osp.join(out_dir, 'info.yaml'), 'w') as f:
yaml.safe_dump(info, f, default_flow_style=False)
print('Saved to: %s' % out_dir)
if __name__ == '__main__':
main()
然后替换之前json_to_dataset.py文件
3 生成标记分割图

找到labelme json_to_dataset.exe文件路径

打开anaconda之后,
(1)先输入D:
(2)然后cd D:\Anaconda3\Scripts
(3)然后labelme_json_to_dataset.exe D:\UAVpic\uav_train\New\labelme\json
之后的文件保存在scripts下面,用的相对路径保存了!

3.1 得到背景为0,目标为1的二值图
3.1.1 Labelme版本(3.16.2)
Labelme的低版本,才有draw.py,改里面的代码,实现目标为1。修改draw.py里面的代码


3.1.2 Labelme高版本的绘图设置
高版本的没有draw.py文件了,是在imgviz里面的label.py修改。

后面的位置可以搜索文件夹!!!
添加的一段代码如下:

4 Shortcuts
为了加快标注进程,加入快捷键
找到.labelmerc 文件 直接以记事本编辑

5 生成mask
5.1 添加标签和图片


把标签放在图片目录下
5.2 导入图片和标签到labelme
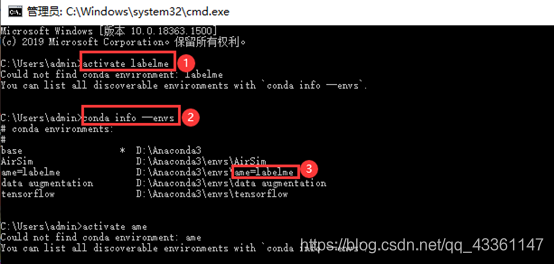
(1)Activate labelme
(2)然后d:
(3)cd D:\UAVpic\uav_train\New\labelme
(4)直接labelme 图片文件夹名(你自己的) --labels labels.txt --nodata --validatelabel exact
导入成功
标注时最好把图片和标注的json放在一起,方便修改标注!
5.3 批量生成最后的文件
python labelme2voc.py image target --labels labels.txt
image里面是标签和图片放在一起!















 1万+
1万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









