









!!! 有需要的小伙伴可以通过文章末尾名片咨询我哦!!!
💕💕作者:小马
💕💕个人简介:混迹在java圈十年有余,擅长Java、微信小程序、Python、Android等,大家有这一块的问题可以一起交流!
💕💕各类成品java系统 。javaweb,ssh,ssm,springboot等等项目框架,源码丰富,欢迎咨询交流。学习资料、程序开发、技术解答、代码讲解、源码部署,需要请看文末联系方式。
基于Web的爬虫系统设计与实现
摘要:随着信息技术的飞速发展,互联网上的信息数量出现了爆炸式的增长。如何从海量数据中提取并利用有用信息成为一大挑战。网络爬虫的出现有效地解决了这一问题,它可以按照人们设计的规则,凭借计算机的强大处理能力,快速地获取并提炼出有价值的数据.相对于人工获取信息的方式,网络爬虫获取信息的方式具有更高的效率。
本文通过Python语言实现一个对Ajax异步加载的网站(智联招聘)的爬虫。通过爬虫程序实现对全国不同岗位的信息批量抓取,具体信息包含:职位名称、薪资、信息更新时间、工作地点等,在进行数据分析。
文章首先对Web数据挖掘技术进行概括,分别从数据挖掘技术概念,技术应用优势与技术原理三方面进行论述。其次,重点探讨基于Python基础上的Web数据挖掘技术开发设计方法,对数据挖掘过程中的各类爬虫技术应用优势进行对比,可以作为数据挖掘系统构建过程中的理论参照。
Design and implementation of the crawler system based on Web
Abstract: With the rapid development of information technology, the number of information on the Internet has shown an explosive growth.How to extract and use useful information from huge amounts of data has become a big challenge.The emergence of network crawler effectively solves this problem, which can quickly obtain and extract valuable data according to the rules designed by people, with the powerful processing ability of computers. Compared with the way of manually acquiring the information, the way of the network crawler obtaining the information is more efficient.
This paper implements a crawler asynchronously loaded on the Ajax website (Zhaopin) in the Python language.Through the crawler program, the information of different positions in the country is captured in batches. The specific information includes: job name, salary, information update time, work place, etc., for data analysis.
The article first summarizes the Web data mining technology, respectively from the concept of data mining technology, technology application advantages and technical principles.Secondly, focus on the development and design method of Web data mining technology based on Python, and compare the application advantages of various crawler technologies in the process of data mining, which can be used as a theoretical reference in the construction process of data mining system.
目 录
1 绪论 1
1.1 选题背景 1
1.1.1 课题的国内外的研究现状 1
1.1.2 课题研究的必要性 2
1.2 课题研究的内容 3
2 开发软件平台介绍 4
2.1 软件平台 4
2.2 开发语言 4
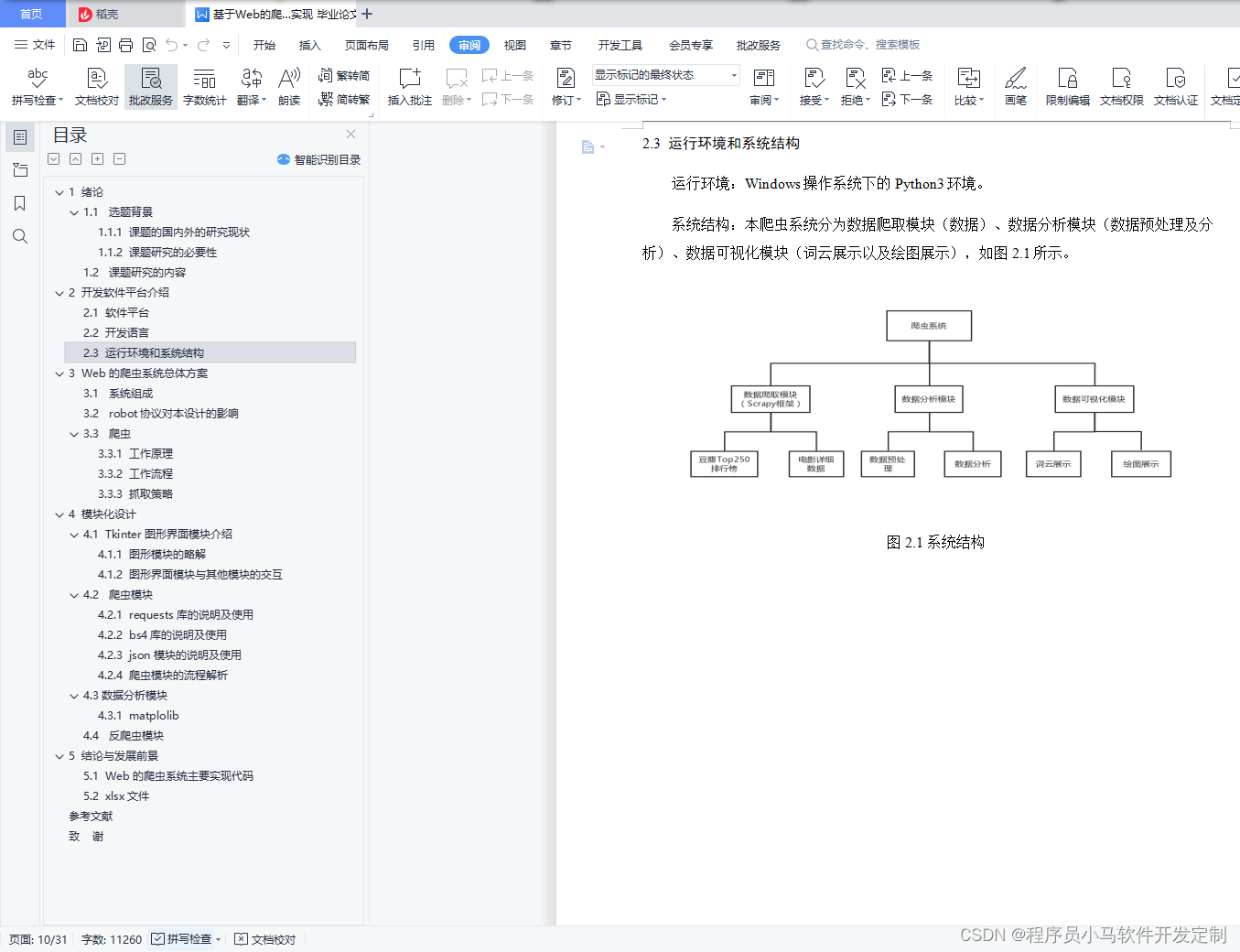
2.3 运行环境和系统结构 5
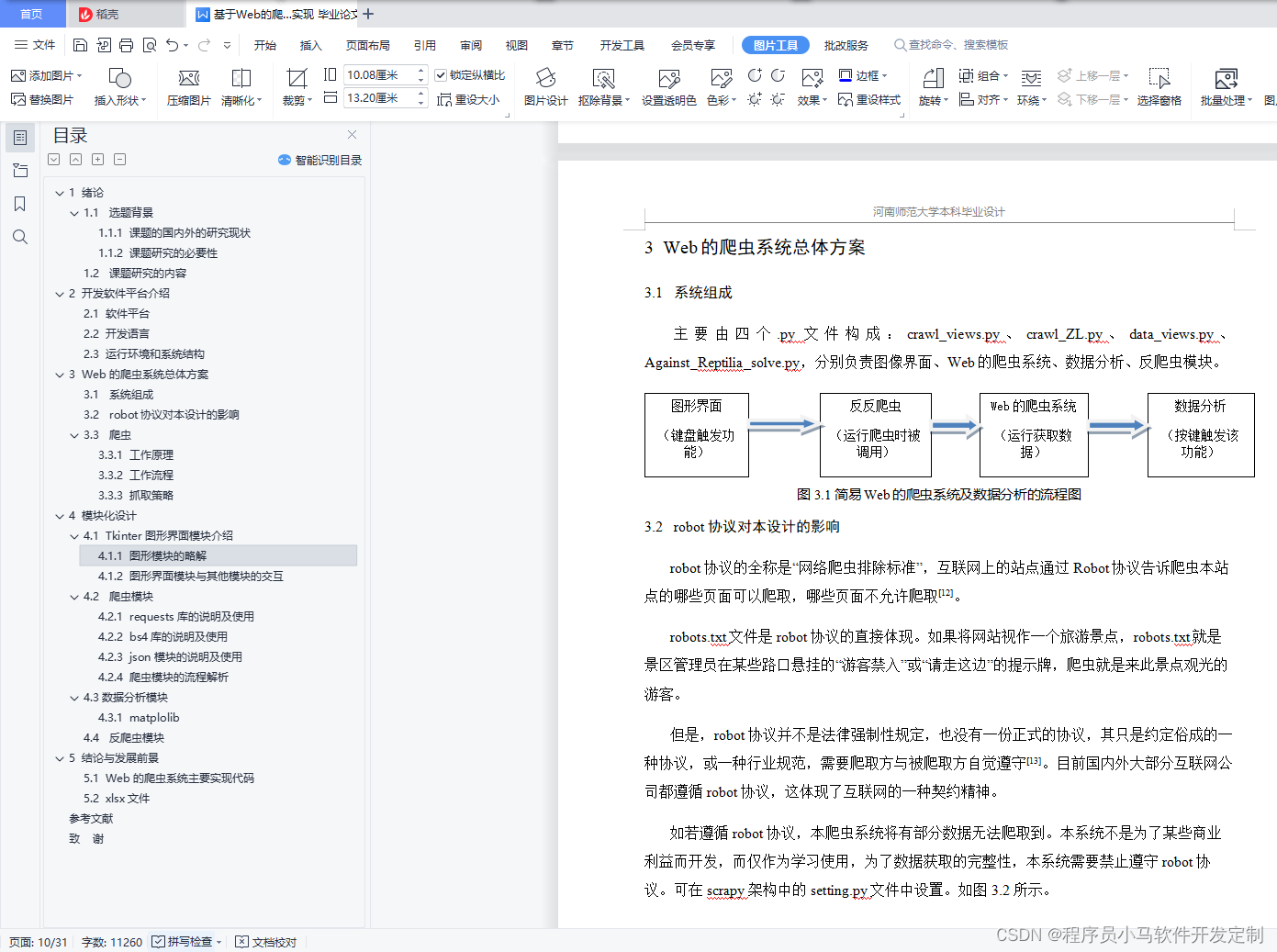
3 Web的爬虫系统总体方案 6
3.1 系统组成 6
3.2 robot协议对本设计的影响 6
3.3 爬虫 7
3.3.1 工作原理 7
3.3.2 工作流程 7
3.3.3 抓取策略 7
4 模块化设计 9
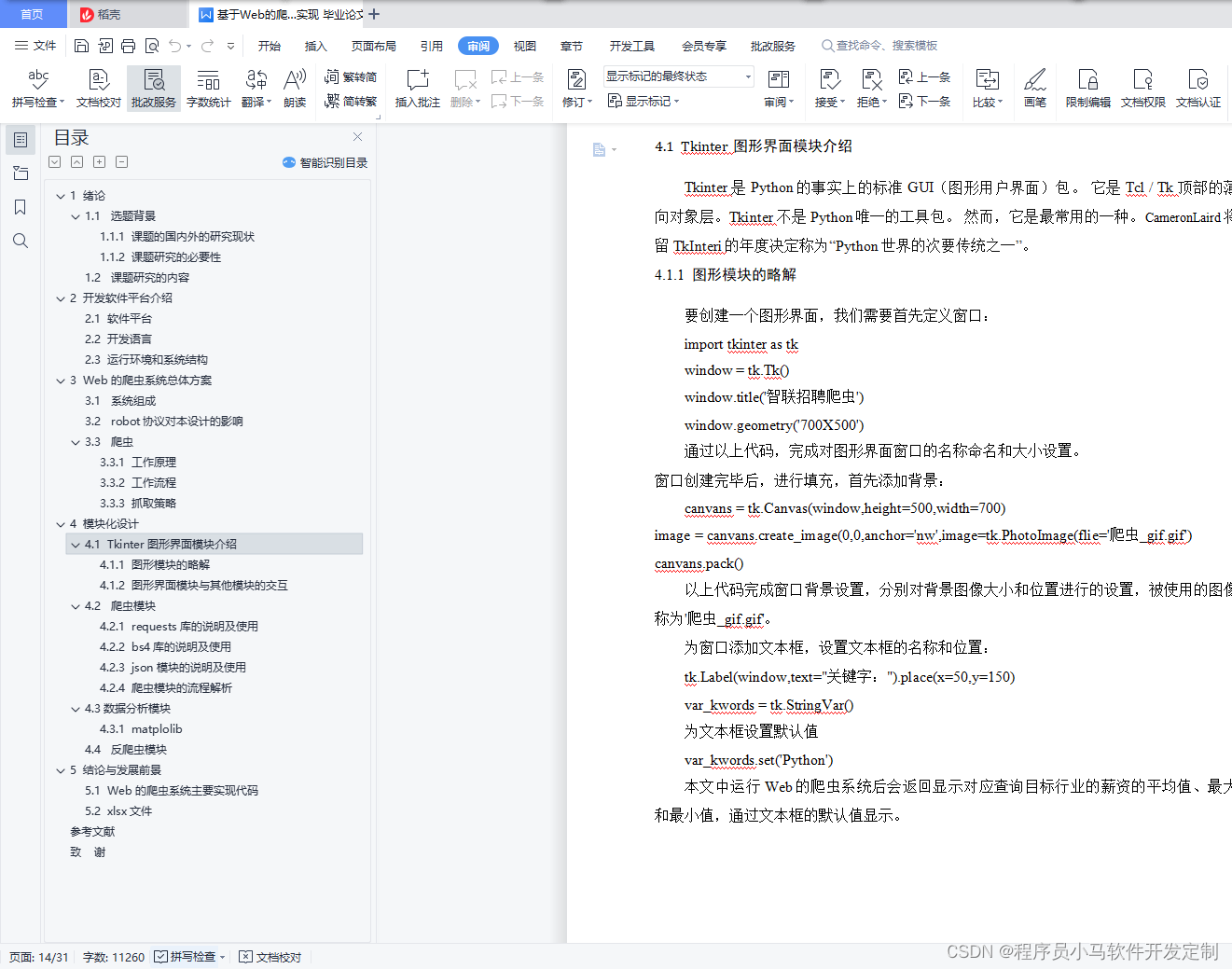
4.1 Tkinter图形界面模块介绍 9
4.1.1 图形模块的略解 9
4.1.2 图形界面模块与其他模块的交互 10
4.2 爬虫模块 12
4.2.1 requests库的说明及使用 12
4.2.2 bs4库的说明及使用 12
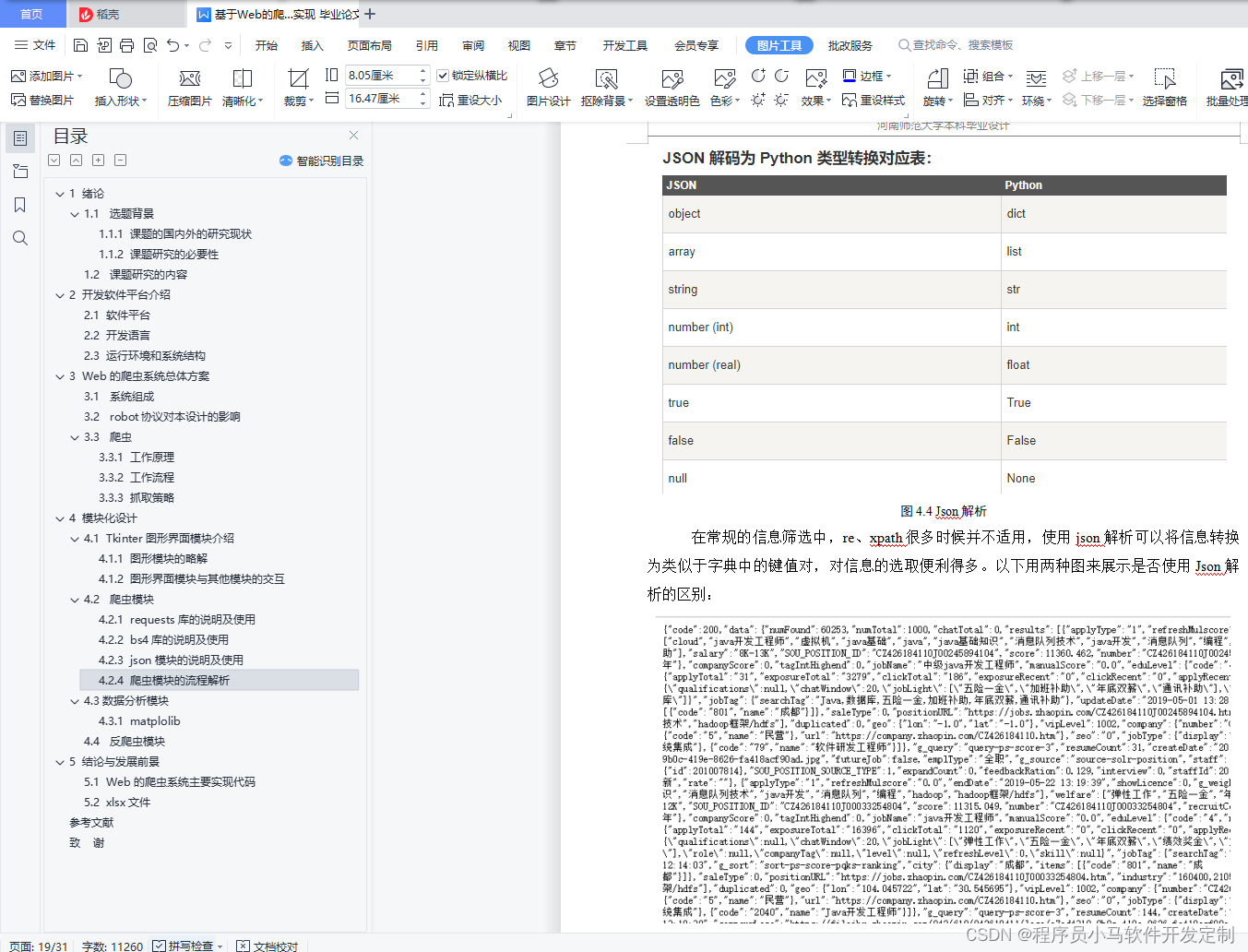
4.2.3 json模块的说明及使用 13
4.2.4 爬虫模块的流程解析 16
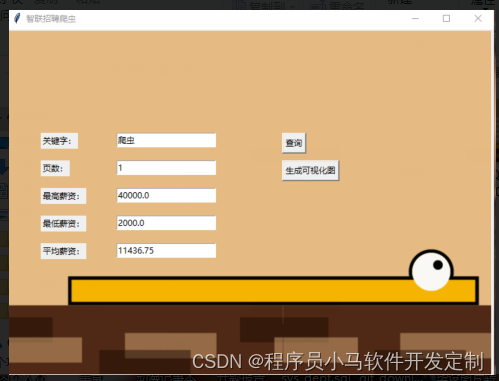
4.3 数据分析模块 20
4.3.1 matplolib 20
4.4 反爬虫模块 22
5 结论与发展前景 23
5.1 Web的爬虫系统主要实现代码 23
5.2 xlsx文件 24
参考文献 25
致 谢 26
更多项目:
另有1000+份项目源码,项目有java(包含springboot,ssm,jsp等),小程序,python,php,net等语言项目。项目均包含完整前后端源码,可正常运行!
!!! 有需要的小伙伴可以点击下方链接咨询我哦!!!
















 1万+
1万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











