








Knowledge-enhanced Hierarchical Attention for Community Question Answering with Multi-task and Adaptive Learning
介绍
作者认为社区QA存在下列问题:
- 外部事实知识没有得到充分利用(KB)
- CQA模型应当考虑输入序列的不同语义级别(attention)
- 现有的CQA模型没有考虑输入question的类别,可能丢失重要特征(多任务:QA+question 分类)
- 现有的CQA模型不能有效的处理噪声数据
问题定义
给定一个问题 q q q =[ w w w q ^q q 1 _1 1, w w w q ^q q 2 _2 2,…, w w w q ^q q n _n n]和一个答案 a a a=[ w w w a ^a a 1 _1 1, w w w a ^a a 2 _2 2,…, w w w a ^a a m _m m],CQA任务旨在推断标签 Y Y Y ∈ ∈ ∈{good,bed}。此外还假设每个问题 q q q有一个类别标签 x x x。
The Overall Architecture:five modules
(1) Knowledge-enhanced Representation Learning with Hierarchical Attention
包括三个阶段的attention
- Word-level Mutual Attention
首先嵌入。word2Vec:词嵌入和ELMo:character-level嵌入,将两个嵌入连接作为异构词向量:
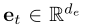
所以每个 q q q和 a a a的上下文表示分别为:
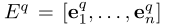
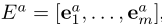
然后通过n-gram匹配进行实体检测,并为输入文档中提及的每个实体从知识库中获取前
K
K
K个实体候选。实体嵌入用的DeepWalk。在形式上,第
t
t
t个实体的候选实体称为{
e
e
e
n
n
n
t
t
t
t
_t
t
1
_1
1,
e
e
e
n
n
n
t
t
t
t
_t
t
2
_2
2,…,
e
e
e
n
n
n
t
t
t
t
_t
t
K
_K
K}
∈
∈
∈
R
R
R
K
^K
K
×
^×
×
d
^d
d
k
^k
k
b
^b
b,其中
d
d
d
k
_k
k
b
_b
b是嵌入
K
K
K
B
B
B中的实体的维数。上下文引导的注意力模型被设计为计算文档中提到的每个实体的知识表示,其计算如下:
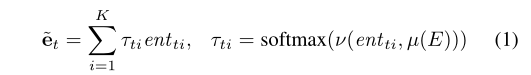
v
v
v是注意力计算函数(MLP),
E
E
E为
q
q
q或
a
a
a的上下文表示,所以经过attention后获得知识-aware的
q
q
q和
a
a
a表示:
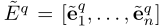
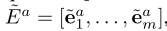
在获得实体和单词嵌入后,作者设计了单词级的相互注意机制来识别上下文和知识表示之间的关系。采用上下文和知识表示之间的点积来计算问题
q
q
q的相关矩阵
M
q
M_q
Mq,如下所示:
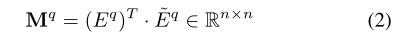
矩阵中每一个元素表示上下文表示和知识表示的相关性(0-1之间)。然后对矩阵中的每行和每列都都做一个取平均值操作,分别为上下文表示和知识表示计算注意向量:
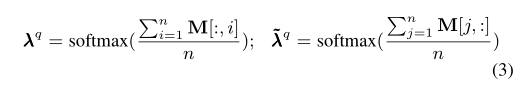
最后,相互感知:
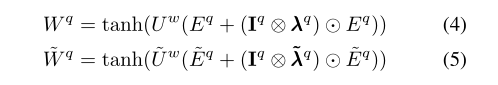
I
q
I^q
Iq=[1,…,1]
T
^T
T,维度为d,⊗表示科罗纳乘积:可以进行两个不同维度的矩阵运算。 ⚪表示元素对乘法。
- Phrase-level Attention
首先将 W q W^q Wq和 W W W − ^- − q ^q q用一个 C C C N N N N N N处理得到feature maps:
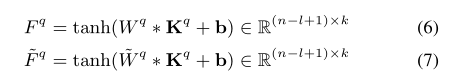
然后设计了一种Phrase-level Attention来学习重要的局部n-gram组块:
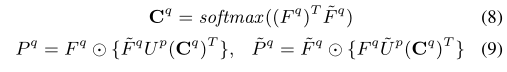
P q P^q Pq和 P P P − ^- − q ^q q表示短语级别的知识强化的上下文表示和短语级别的上下文强化的知识表示。
最后使用两个独立的LSTM对 P q P^q Pq和 P P P − ^- − q ^q q编码:
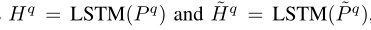
- Document-level Attention
使用知识表示作为关注源来关注上下文,以便选择那些关键的知识增强的上下文词块来组成知识感知文档表示。在形式上,文档级关注的定义如下
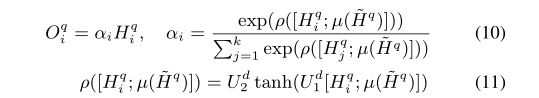
µ µ µ是mean pooling操作,文档级别的attention的输出 O O O q ^q q i _i i表示为对于 q q q的文档级别的知识强化表示。
执行相同的操作得到知识增强的答案表示 O O O a ^a a。
(2)Interactive Question/Answer Representation Learning
多头注意力处理
O
O
O
a
^a
a和
O
O
O
q
^q
q。
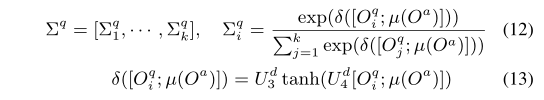
其中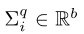
表示关注矩阵的第
i
i
i行,
b
b
b是关注的跳数。同样,可以计算问题感知答案表征的注意矩阵
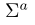
然后计算交互:
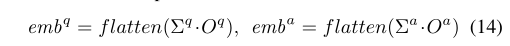
faltten是将矩阵展平操作。
(3)Question Categorization
问题表征
e
e
e
m
m
m
b
b
b
q
^q
q被feed特定任务的全连接层输出类别概率:
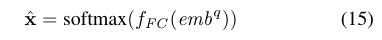
loss为交叉熵:
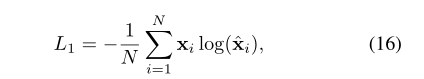
(4)Community Question Answering
- Category-aware Representation Learning
作者开发了一个类别感知转换过程,使转换后的问题嵌入保持类别信息。在形式上,模型将问题表示 e e e m m m b b b q ^q q转换为特定类别的问题表示 e e e m m m b b b q ^q q − ^- −
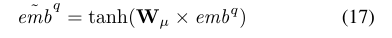
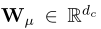 是转换矩阵。
是转换矩阵。
为了使得转换后的问题表示能够捕获类别信息。引入了 X X X(类别数)个子矩阵( W 1 W_1 W1,…, W X W_X WX),其中每个子矩阵对应于一个问题类别。类别感知变换矩阵 W µ W_µ Wµ可以计算为子矩阵的加权和:
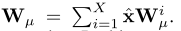
对于CQA任务,连接最终的问题和答案表示,并将它们馈送到特定于任务的完整连接层即可:
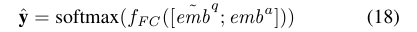
CQA任务的loss仍然为交叉熵:
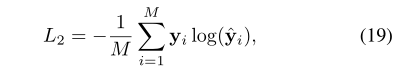
- Ensemble Learning
作者从SemEval-2017测试集中随机选择100个被KHAMA错误预测的问题进行错误分析。我们观察到,错误预测的问题在问题类别中是不平衡的。“Family Life in Qatar”和“Moving to Qatar”等问题类别中的样本比“Doha Shopping”和“Carsand driving”等其他类别中的样本更难预测。为了建立一个更加稳定和鲁棒的预测模型,作者构造了多个CQA分类器,并集成它们的结果作为最终的预测结果,他们从自适应boosting算法中学习到多个分类器,基于训练误差更新第
i
i
i个CQA分类器
g
i
g_i
gi的权重
α
i
α_i
αi:
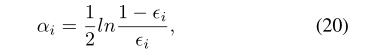
最终预测模型G通过加权投票获得:
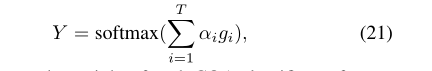
(5)Multi-task Learning
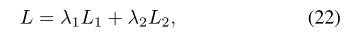
λ
1
λ_1
λ1= 0.2 and
λ
2
λ_2
λ2= 0.8
实验
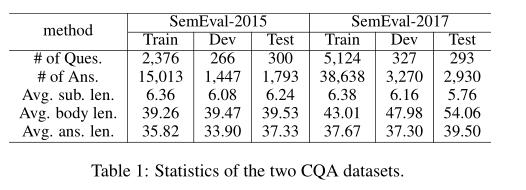
数据集
实验细节
使用Freebase的子集作为KB:FB5M3
根据服从正态分布初始化图嵌入,维度:100
word2vec:100
LSTM hidden_size:200
CNN feature maps :200 个2×2
分类器数量:5
候选实体数量:6
学习率:1×10
−
^-
−
4
^4
4
batch_size:64
L2正则:0.001
dropout:0.2
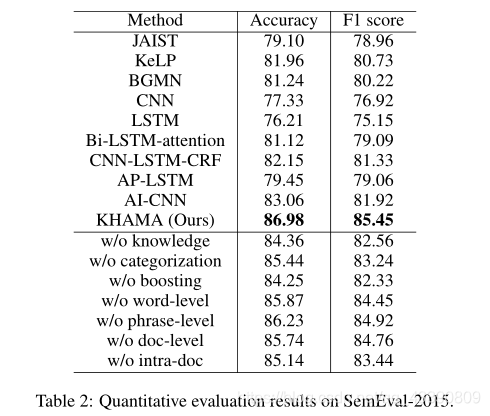
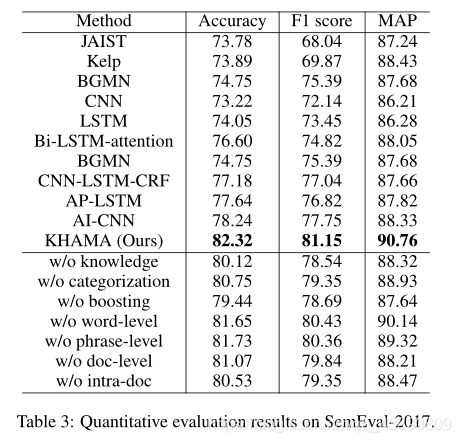
结果
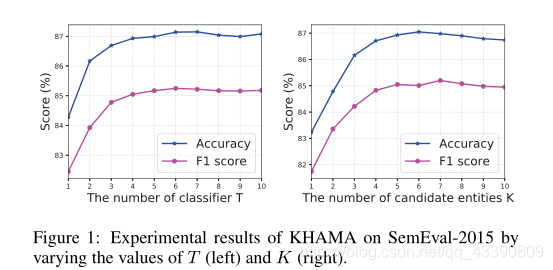
分类器数量和候选实体数量对结果的影响:
















 596
596











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









