







Learning Selective Self-Mutual Attention for RGB-D Saliency Detection–RGB-D
显著性检测的学习选择性自相互注意,来自CVPR2020。
1 Motivation
-
相比于传统的RGB显著性检测方法,包含深度信息的RGB-D检测可以更好地识别出图像的阳性区域。
-
以往的RGB-D检测使用的融合策略(如早期融合、结果融合)作用有限。
2 Contribution
-
基于Non-Local,提出一种新的中间融合策略,通过融合深度注意,准确定位出对象的主体。
-
将注意力机制应用于双流CNN模型,并引入新的残差融合模块,提高了显著性检测的性能,优于所有现存方法。
3 Approach
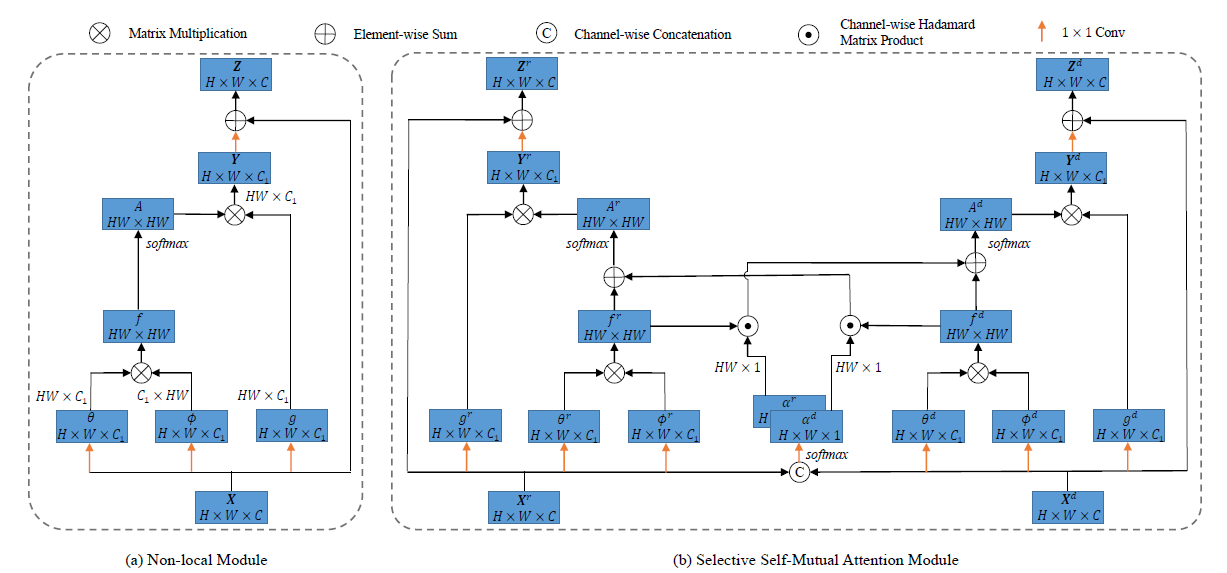
本文使用的注意力模型基于Non Local,是在此基础上进行的改进。整个模型框架如下图右侧图像所示:
 如上图所示,不包含深度信息的RGB方法的检测结果含有很严重的假阳性高亮区域。
如上图所示,不包含深度信息的RGB方法的检测结果含有很严重的假阳性高亮区域。
3.1 Non Local模块
首先简要介绍一种non local模块,如上图左侧部分所示,Non Local模型首先将输入的feature map X \boldsymbol{X} X用三个不同权值的1×1卷积层嵌入到三个通道数均为 C 1 C_1 C1的特征空间中。
之后,计算经过 W θ W_{\theta} Wθ与 W ϕ W_{\phi} Wϕ嵌入之后的 X \boldsymbol{X} X两个不同视图每个像素点之间的相关性。此处的计算方法是简单的矩阵乘法:
f ( X ) = θ ( X ) ϕ ( X ) ⊤ f(\boldsymbol{X})=\theta(\boldsymbol{X}) \phi(\boldsymbol{X})^{\top} f(X)=θ(X)ϕ(X)⊤
然后,使用softmax对 f ( X ) f(\boldsymbol{X}) f(X)进行行归一化处理得到 X \boldsymbol{X} X的注意力矩阵,第 i i i一行即表示像素点 i i i与其他点之间的注意力权重情况。
A ( X ) = s o f t m a x ( f ( X ) ) A(\boldsymbol{X})=softmax(f(\boldsymbol{X})) A(X)=softmax(f(X))
再将得到的注意力矩阵与 X \boldsymbol{X} X的另一个嵌入视图 g ( X )
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章
















 1216
1216











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









