







Association Rules Mining
关联规则(Association Rules)是反映一个事物与其他事物之间的相互依存性和关联性,是数据挖掘的一个重要技术,用于从大量数据中挖掘出有价值的数据项之间的相关关系。
常见的购物篮分析
该过程通过发现顾客放入其购物篮中的不同商品之间的联系,分析顾客的购买习惯。通过了解哪些商品频繁地被顾客同时购买,这种关联的发现可以帮助零售商制定营销策略。其他的应用还包括价目表设计、商品促销、商品的排放和基于购买模式的顾客划分。
可从数据库中关联分析出形如“由于某些事件的发生而引起另外一些事件的发生”之类的规则
频繁项集评估标准
常用的频繁项集的评估标准有支持度,置信度和提升度三个
- 支持度:几个关联的数据在数据集中出现的次数占总数据集的比重

- 置信度:一个数据出现后,另一个数据出现的概率,或者说数据的条件概率。
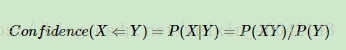
- 提升度:表示含有Y的条件下,同时含有X的概率,与X总体发生的概率之比
![]()
频繁集挖掘(Frequent Set Mining)、Aporiori算法理论
Apriori算法是发现频繁项集的一种方法,利用该算法可以计算得到频繁项集,并直接给出上述介绍的支持度,然后再根据需要我们可以进一步处理得到提升度与置信度,但是这个和Apriori算法已经无关了,直接利用上述定义计算即可,所以我们只讲红色部分。
原理:如果一个项集是频繁项集,则它的所有子集都是频繁项集
如果一个集合不是频繁项集,则它的所有父集(超集)都不是频繁项集
关联分析的目标:
- 发现频繁项集:发现满足最小支持度的所有项集
- 发现关联规则:从频繁项集中提取所有高置信度的规则
Apriori算法采用了迭代的方法
- 先搜索出候选1项集及对应的支持度,剪枝去掉低于支持度的1项集,得到频繁1项集。
- 对剩下的频繁1项集进行连接,得到候选的频繁2项集,筛选去掉低于支持度的候选频繁2项集,得到真正的频繁二项集,
- 以此类推,迭代下去,直到无法找到频繁k+1项集为止,对应的频繁k项集的集合即为算法的输出结果
下图来自博客:https://www.cnblogs.com/pinard/p/6293298.html
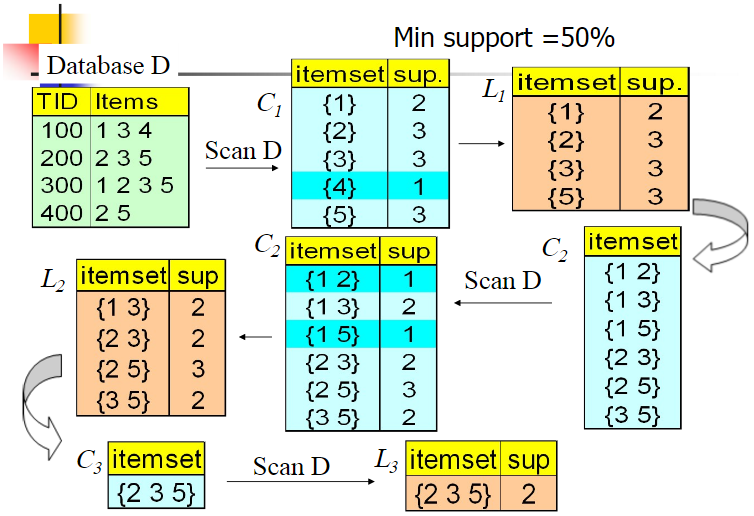
注:上面的每一个TID你可以认为就是一个顾客,每一个items就是这个顾客购买的物品,我们这里叫做item,翻译成项。从而,项集就是item的集合,k项集的意思就是项集里面项的个数为k,1项集就是指这个项集里面只有一个项。
解释:
L1->C2的过程是L1*L1笛卡尔连接,但是要去掉{1,1}这样的本质是1项集的集合,一共有组合数C(4,2)=6项。L2->C3的过程也类似,为了得到3项集,不应该是L2*L2自身的笛卡尔连接,而应该是L2*L1的笛卡尔连接,这样理论有4*4=16项,但是有大量的3项集里面都有项是相同的,比如{1,3,1}等等,这些实际上是一个2项集,去除之后剩下8个真正的3项集,接下来3项集之间又有重复一摸一样的,再去掉之后,得到了完全相异的3项集,这些是候选集,然后再去数据库查找各自的支持度,不过这里为了增快速度的话,比如{1,3,2},根据apriori算法的第二个原理,由于C2中{1,2}已经不是频繁项集,所以超集{1,3,2}也不是,这样,最终只剩下C3中的{2,3,5}。
最后,更正一下上图中的min_support=2。
Aporiori算法实战(python版本)
先安装一下库,
pip install apyori
from apyori import apriori
data = [['豆奶','莴苣'],
['莴苣','尿布','葡萄酒','甜菜'],
['豆奶','尿布','葡萄酒','橙汁'],
['莴苣','豆奶','尿布','葡萄酒'],
['莴苣','豆奶','尿布','橙汁']]
result = list(apriori(transactions=data)
其中result存储了所有项集,以及所有可能被用户问到的置信度与提升度。
所以,别看数据这么小,但是由于组合问题,result却超多。这个时候,如果我们的数据太大,result将会爆掉,因此我们可以利用参数进行过滤,例如我们只想要支持度大于0.5,长度为2以下的,置信度大于0.5的,提升度大于1的result,那么实战如下:
result = list(apriori(transactions=data,max_length=2,min_support=0.5,min_confidence=0.5,min_lift=1))
result
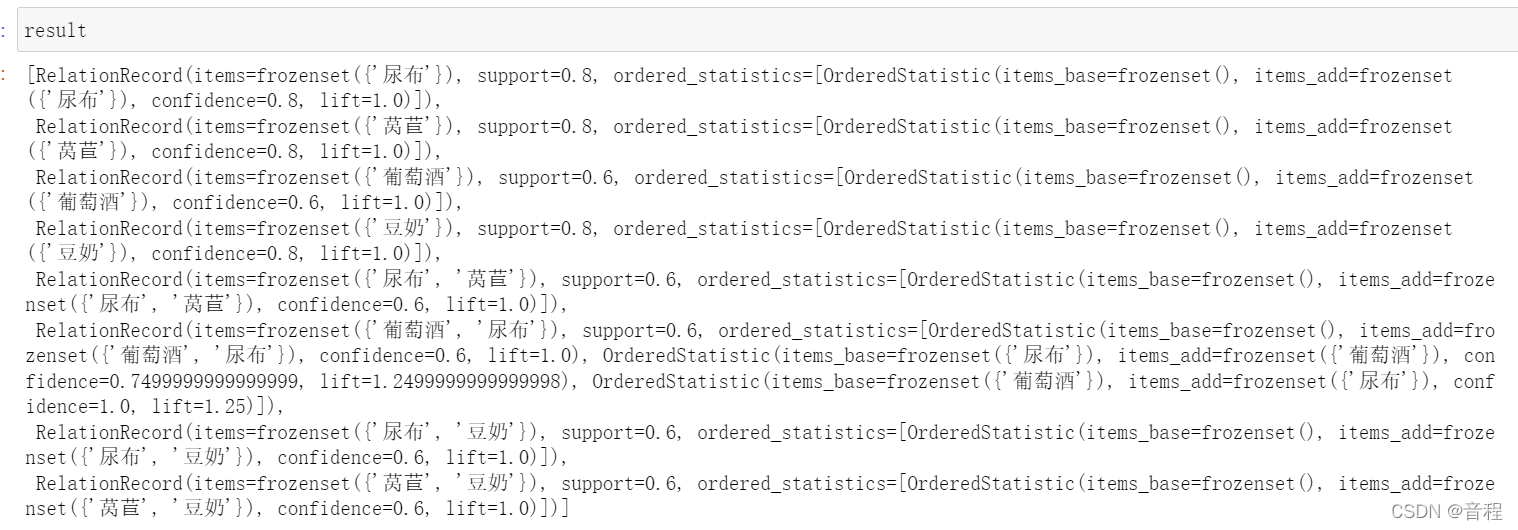
千万要注意:这里有一个极其坑逼的地方,默认min_support=0.1,然而这个值是不合适的,特别是当你的数据集比较大的时候,有可能最终的结果一个都没有,然后你在那里丈二和尚摸不着头脑,这个时候设置min_support=0即可。
我们发现在支持度大于等于0.5的2项集中,只有葡萄酒和尿布是相互支持度以及提升度都满足我们的需求。
解释:其中那个base就是上面介绍支持度,置信度,提升度时候的Y。那个add就是X。
Our results would appear as a list containing multiple entries such as the one that follows:(注,下面这个数据不是上面这个数据,只是为例子做一个解释而已)
RelationRecord(items=frozenset({'beer', 'nuts'}),
support=0.5,
ordered_statistics=[OrderedStatistic(items_base=frozenset({'beer'}),
items_add=frozenset({'nuts'}),
confidence=0.5,
lift=1.0),
OrderedStatistic(items_base=frozenset({'nuts'}),
items_add=frozenset({'beer'}),
confidence=1.0,
lift=1.0)])
Each RelationRecord reflects all rules associated with a specific itemset (items) that has relevant rules. Support (support ), given that it’s simply a count of appearances of those items together, is the same for any rules involving those items, and so only appears once per RelationRecord. The ordered_statistic reflects a list of all rules that met our min_confidence and min_lift requirements (parameterized when we called apriori() ). Each OrderedStatistic contains the antecedent (items_base) and consequent (items_add) for the rule, as well as the associated confidence and lift .
最后附上其参数如下:
apriori(transactions, **kwargs):
Executes Apriori algorithm and returns a RelationRecord generator.
Arguments:
transactions -- A transaction iterable object
(eg. [['A', 'B'], ['B', 'C']]).
Keyword arguments:
min_support -- The minimum support of relations (float).
min_confidence -- The minimum confidence of relations (float).
min_lift -- The minimum lift of relations (float).
max_length -- The maximum length of the relation (integer)
高级实战:注意到,我们上面使用了list(aporiori()),这是因为作者设计aporiori()的时候想得很好,考虑到如果数量量太大的话,这个result所占用内存会爆炸,所以aporiori()返回的是一个生成器generator,这个东西会根据你的调用,动态生成数据,比如有1万个数据,它会按照一个函数来生成,你要多少个,就给你生成多少个。而我们list()之后,就相当于将所有东西的生成完毕了并存储了下来,所以容易爆炸,生成器本身是不会爆炸的。

















 437
437

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









