







文章目录
一、RCNN
论文地址:https://arxiv.org/abs/1311.2524
R-CNN(Region with CNN feature)

4个步骤:

1.候选区域的生成

1k~2k个候选区域(使用Selective Search方法)
2.对每个候选区域,使用深度网络提取特征

3.特征送入每一类的SVM分类器,判定类别
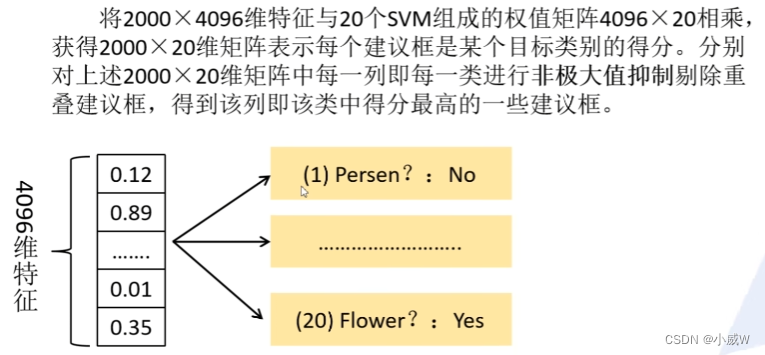
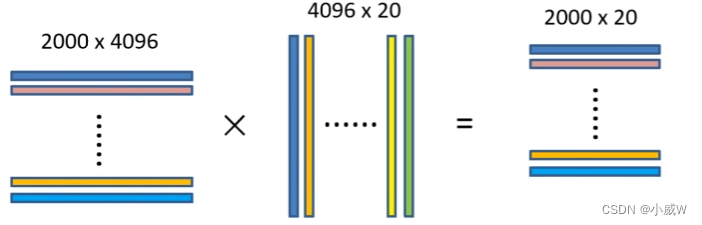
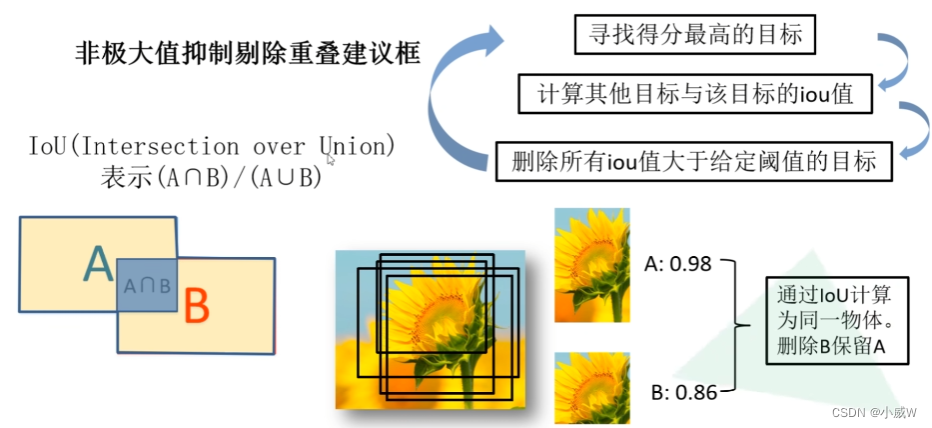
非极大抑制
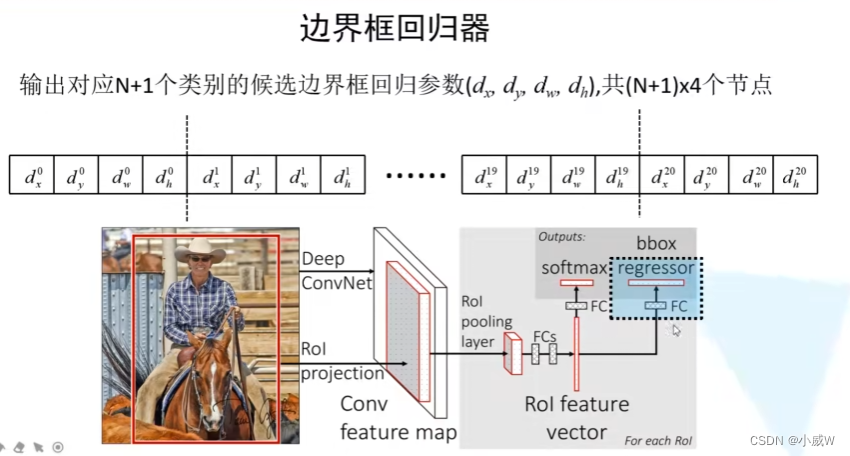
4.使用回归器精细修正候选框位置

4个值:中心点的xy坐标、w和h的缩放因子。


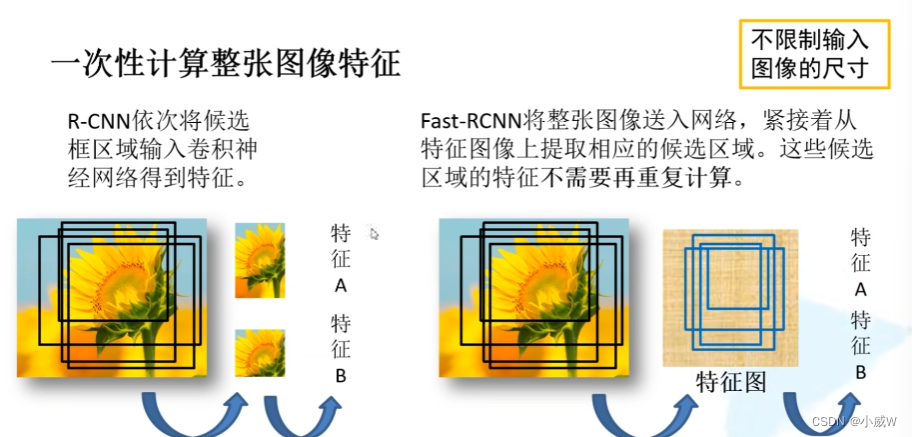
二、FastRCNN
论文地址:https://arxiv.org/abs/1504.08083

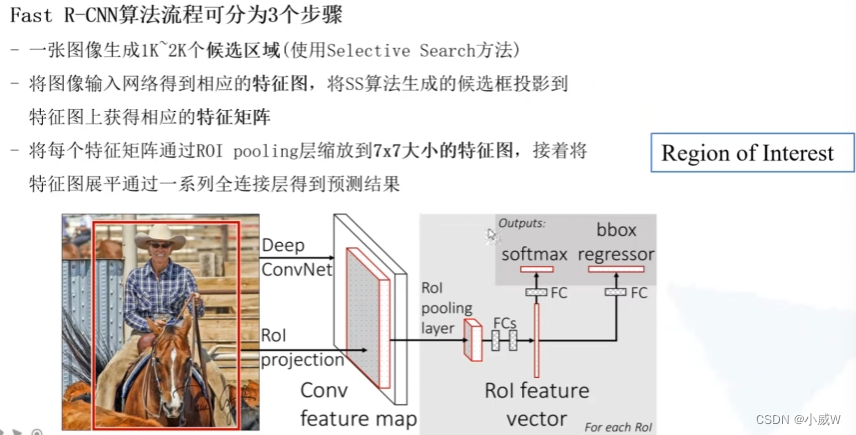
3个步骤:
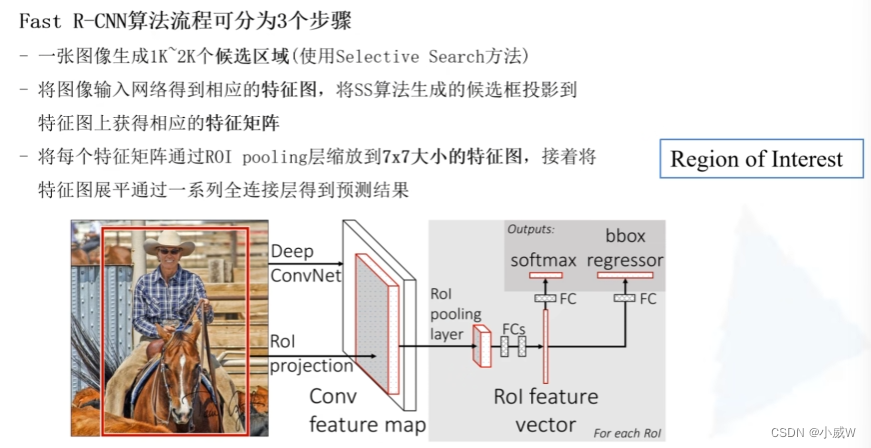
ROI:Region of Interest,感兴趣区域。

正样本和负样本
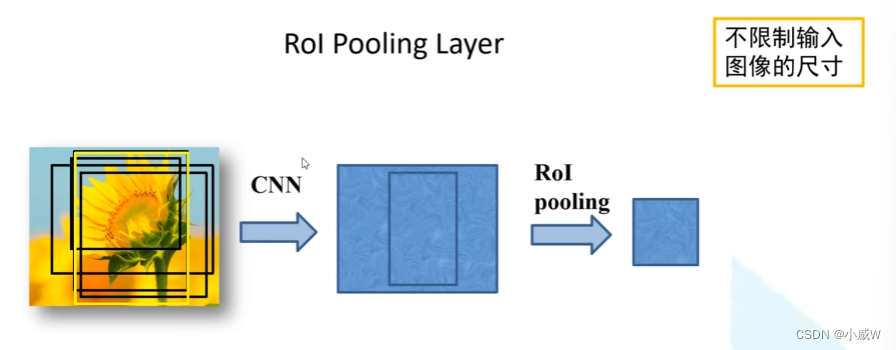 ROI Pooling缩放到统一的尺寸(7×7)
ROI Pooling缩放到统一的尺寸(7×7)
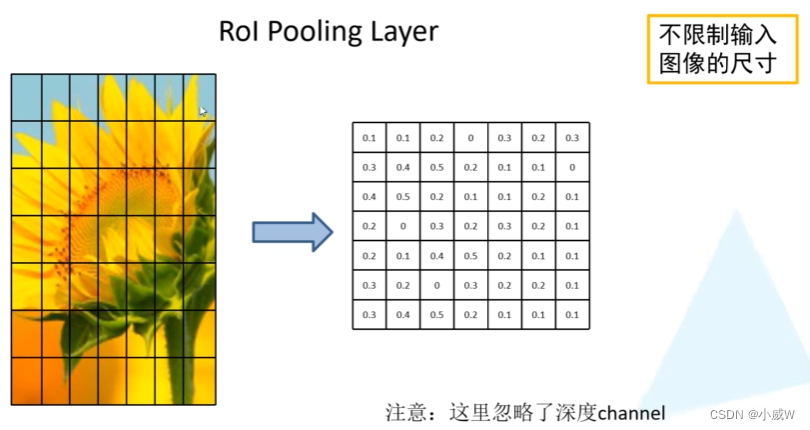
这样就不用限制图像的尺寸。
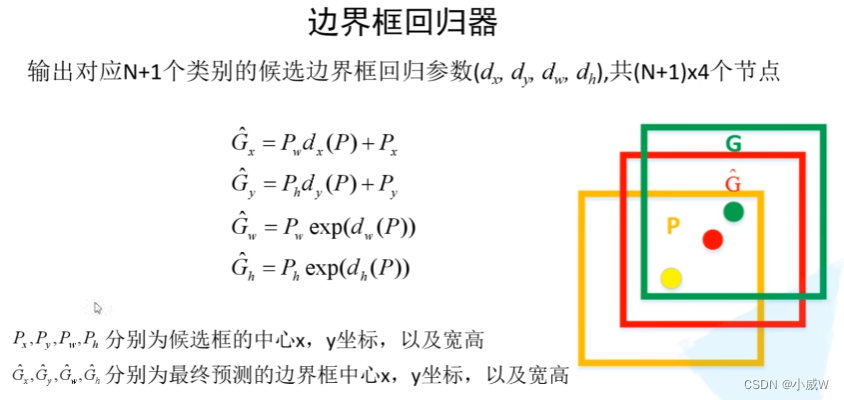
分类器和边界框回归器

并联两个全连接层:一个用于目标概率预测(分类器),一个用于边界框预测(边界框回归器)。
Multi-task loss

分类损失
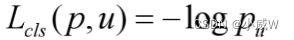
回顾:
见https://blog.csdn.net/qq_43406895/article/details/126361642

假设真实标签的one-hot编码是:[0,0,…1,…,0]
预测的softmax概率为[0.1,0.3,…,0.4,…,0.1]
那么Loss=-log(0.4)
边界框回归损失

x、y、w、h
回归损失函数1:L1 loss, L2 loss以及Smooth L1 Loss的对比
[u>=1]表示当u>=1时值为1,否则为0。

计算速度瓶颈在于 Selective Search 算法。
三、FasterRCNN
论文地址:https://arxiv.org/abs/1506.01497

回顾,Fast R-CNN
Faster R-CNN(RPN + Fast R-CNN):3个步骤

RPN网络结构
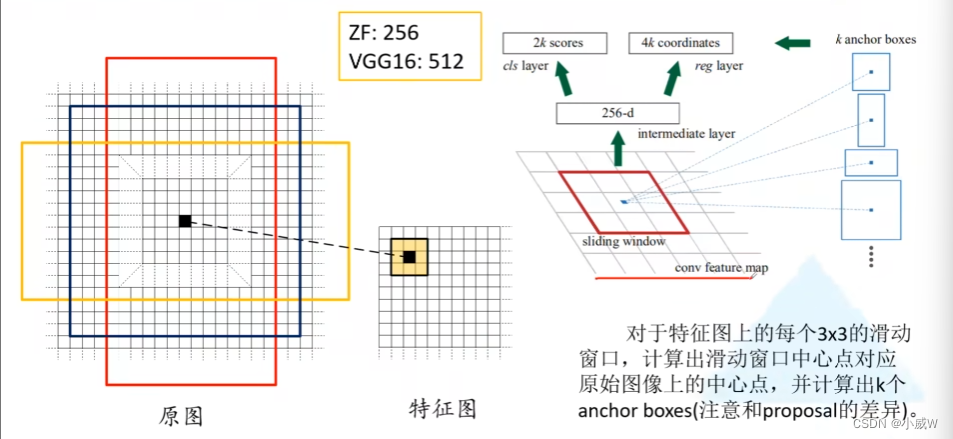
cls layer 中的 2k scores 中的 2 分别对应 前景和背景 的概率。
intermediate layer的256-d对应ZF的256,如果使用VGG16的话会变成512-d。

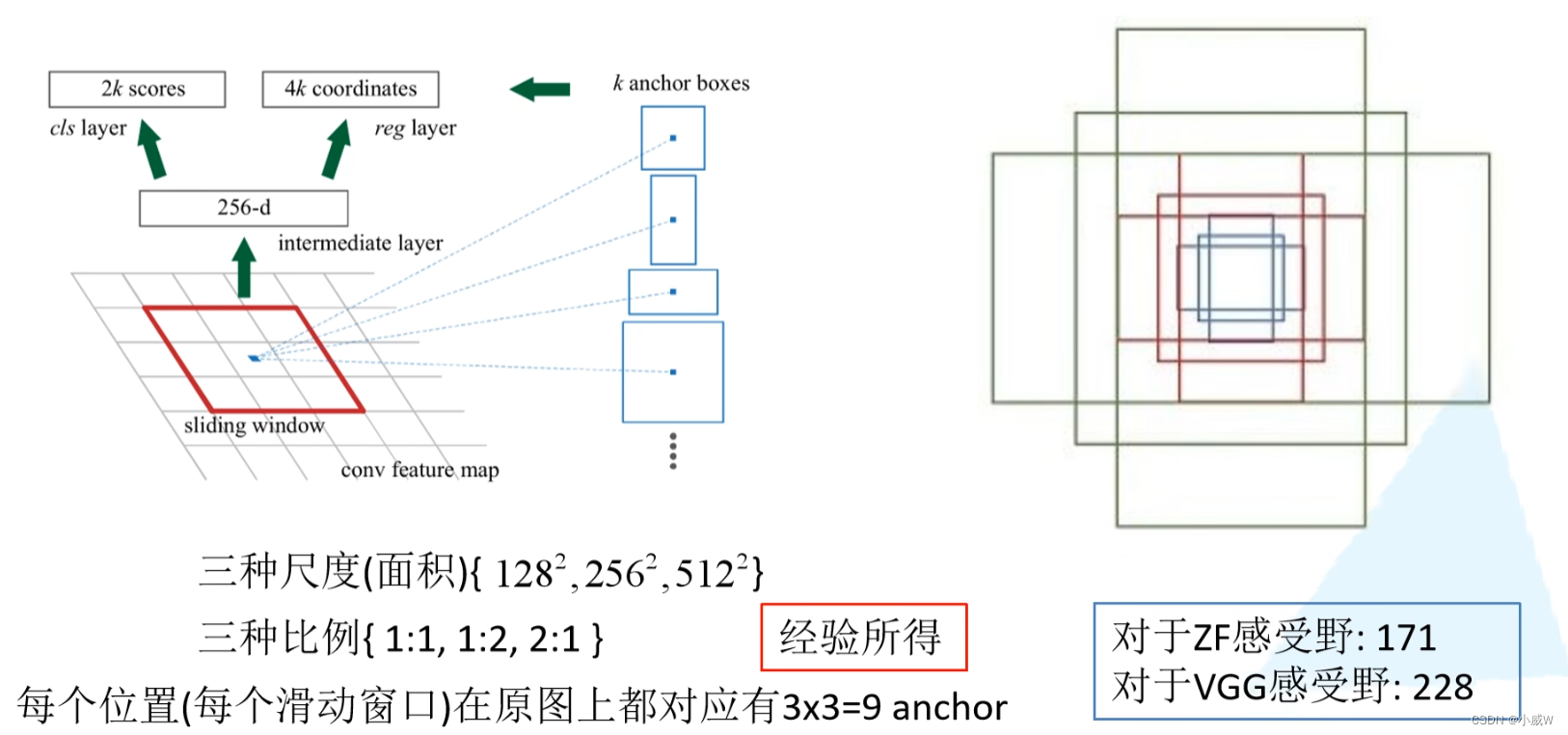
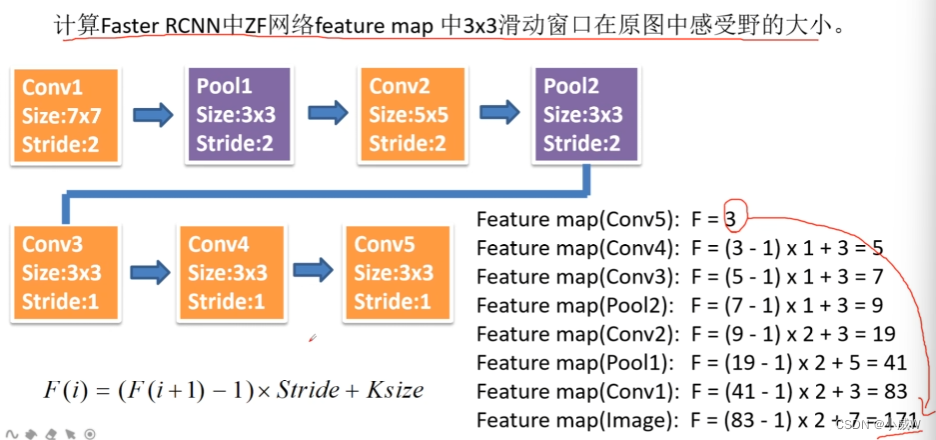
回顾:感受野的计算方式
F(i)=(F(i+1)-1)×Stride+Ksize
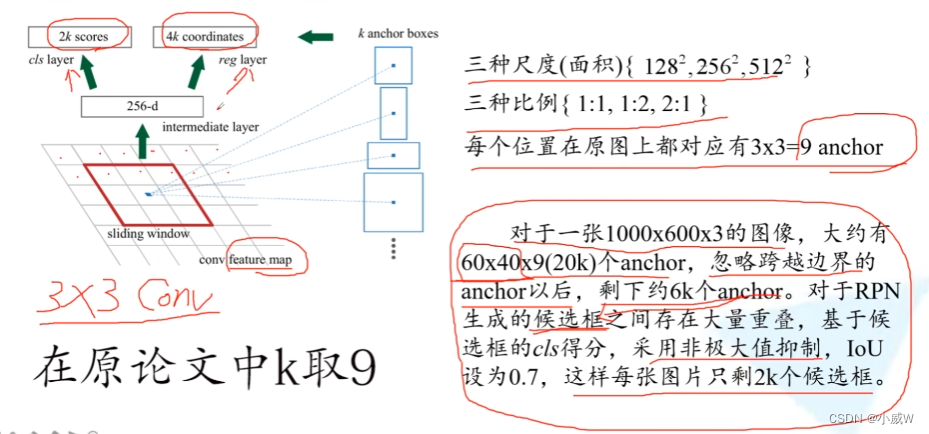
正样本和负样本

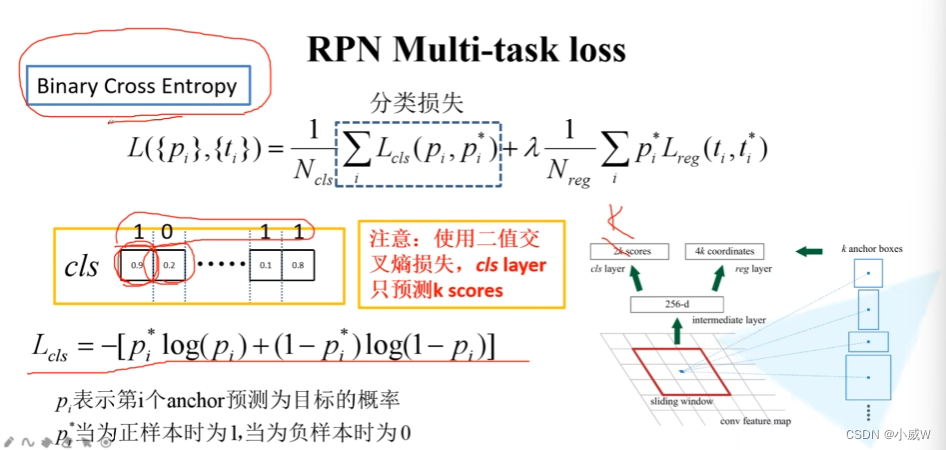
损失

分类损失
2k。多类别的交叉熵损失。
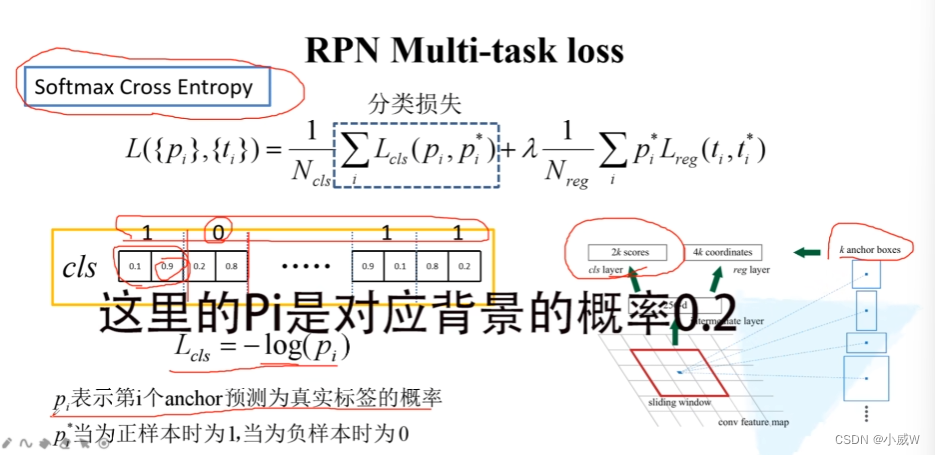
k。二分类的交叉熵损失。
边界框回归损失

Fast R-CNN损失

Faster R-CNN训练



















 334
334











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











