







Fast Online Object Tracking and Segmentation: A Unifying Approach
Abstract:
在本文中,展示如何用一种简单的方法实时执行视觉目标跟踪和半监督视频目标分割。方法被称为SiamMask,通过使用二进制分割任务增加损失,改进了用于目标跟踪的流行全卷积Siamese方法的离线训练过程。一旦训练完毕,SiamMask仅依赖单个边界框初始化,并在线操作,产生类无关的对象分割掩码和旋转边界框每秒55帧。
1、Introduction:
对于许多应用来说,重要的是在视频流转的过程中,可以在线进行跟踪。换句话说,跟踪器不应该利用未来的帧来推断物体的当前位置。这就是视觉对象追踪基准所描绘的情景,它们用一个简单的轴对齐或旋转的边界框来表示目标对象。这样一个简单的注释有助于保持低的数据标记成本;此外,它允许用户对目标进行快速和简单的初始化。
与物体追踪类似,半监督视频物体分割(VOS)的任务需要估计视频第一帧中指定的任意目标的位置。然而,在这种情况下,物体表示包括一个二进制分割掩码,它表示一个像素是否属于目标。对于需要像素级信息的应用,如视频编辑和旋转镜,这样一个详细的表示是比较理想的。可以理解的是,产生像素级的估计需要比简单的边界盒更多的计算资源。因此,VOS方法在传统上是很慢的,通常每帧需要几秒钟。最近,人们对更快的方法产生了兴趣。然而,即使是最快的也不能实时操作。
在本论文中,通过提出SiamMask这一简单的多任务学习方法来缩小任意物体追踪和VOS之间的差距,该方法可用于解决这两个问题。我们的方法基于fully convolutional Siamese networks的快速跟踪方法的成功,方法是在数百万对视频帧上离线训练的,以及最近提供的 YouTube-VOS,一个具有像素注释的大型视频数据集。我们的目标是保留这些方法的离线可训练性和在线速度,同时大大改进它们对目标对象的表述,这仅限于一个简单的轴对齐的包围盒。
为了实现这一目标,我们同时在三个任务上训练 Siamese 网络,每个任务都对应着不同的策略来建立目标物体和新帧中的候选区域之间的对应关系。正如Bertinetto等人的完全卷积方法一样,一项任务是以滑动窗口的方式学习目标物体和多个候选区域之间的相似度测量。输出是一个密集的反应图,它只表示物体的位置,而不提供关于其空间范围的任何信息。为了完善这一信息,我们同时学习了两个进一步的任务:使用区域提议网络的边界框回归和不可知类二进制分。值得注意的是,二元标签只需要在离线训练中计算分割损失,而不需要在分割/追踪过程中在线计算。在我们提出的架构中,每个任务由一个不同的分支代表,从一个共享的CNN出发,为最终的损失做出贡献,将三个输出加在一起。
一旦经过训练,SiamMask 只依赖于单个边界框初始化,在没有更新的情况下在线运行,并以每秒55帧的速度产生物体分割掩码和旋转边界盒。尽管SiamMask简单且速度快,但它在VOT-2018上为实时物体跟踪问题建立了一个新的最先进的方法。此外,同一方法在DAVIS-2016和DAVIS-2017上与最近的半监督VOS方法相比也非常有竞争力,同时以很大的优势成为最快的方法。这一结果是通过简单的边界盒初始化(相对于掩码)实现的,并且没有采用VOS方法经常使用的昂贵技术,如微调、数据增强和光流。
问题:
- 1、追踪的预测目标位置定义不同精度也会不同。(用旋转矩形框描述目标位置比坐标轴对齐的矩形框更精确)
- 2、VOS算法的第一帧需要给定目标的mask,这在人机交互的场景中很难时间,这个mask获取成本过高。
- 3、视频物体分割(VOS)领域的大多数方法的速度慢,难以满足实时性。
构想思路:用三个任务训练一个孪生网络,这三个任务的目标不同,对应了不同的针对目标与候选区域建模策略。任务一用来估计目标的位置,任务二和任务三用来估计目标的尺度大小。
- 任务一:参照SiamFC,用滑动窗口的方式学习目标与多个候选目标的相似性。【输出:密集相应图(标记目标可能所在的中心位置,而不估计目标的尺度信息)】
- 任务二:参照SiamRPN利用区域候选网络(RPN)对目标边界框进行回归。
- 任务三:生成前后景(类无关)的二值分割(mask)。
- 任务二与任务三同时学习。
2、Related Works
Visual object tracking:
大多数现代跟踪器,都使用矩形包围框来初始化目标并估计其在后续帧中的位置。尽管简单的矩形很方便,但它常常不能正确地表示对象,这在图1的例子中很明显。这促使我们提出了一个跟踪器能够产生二进制分割掩码,同时仍然只依赖于边界框初始化。

在过去,跟踪器产生目标对象的粗二进制掩码并不少见,然而,最近唯一像我们一样能够在线操作并从边界框初始化开始生成二进制掩码的跟踪器是Yeo等人的基于超像素的方法。但是,在每秒 4 帧 (fps) 时,其最快的变体明显比我们的建议慢。此外,当使用 CNN 功能时,其速度会降低 60 倍,骤降至 0.1 fps 以下。最后,它还没有证明在现代跟踪或VOS基准上具有竞争力 ,与我们类似,Perazzi等人和Ci等的方法也可以从矩形开始,输出每帧掩码。但是,它们需要在测试时进行微调,这使得它们很慢。
Semi-supervised video object segmentation.
任意物体追踪的基准(例如[55,30])假定追踪器以连续的方式接收输入帧。这方面通常被称为在线或因果的属性[30]。此外,方法通常集中在实现超过典型视频帧率的速度上[29]。相反,半监督的VOS算法在传统上更关注对感兴趣的对象的准确表述[44, 46]。
为了利用视频帧之间的一致性,一些方法通过图标记方法将第一帧的监督分割掩码传播到时间上相邻的帧(例如[61, 47, 57, 40, 2])。特别是,Bao等人[2]最近提出了一种非常精确的方法,该方法利用了空间-时间MRF,其中时间依赖性由光流建模,而空间依赖性则由CNN表示。
另一种流行的策略是独立处理视频帧(例如[39,45,60]),类似于大多数跟踪方法中发生的情况。例如,在OSVOS-S中,Maninis等人[39]不使用任何时间信息。他们依赖于一个预先训练好的全卷积网络进行分类,然后在测试时,他们使用第一帧中提供的真实掩码对其进行微调。相反,MaskTrack[45]是在单个图像上从头开始训练的,但它确实在测试时利用了某种形式的时间性,通过使用最新的掩码预测和光流作为网络的额外输入。
为了达到尽可能高的精度,在测试时,VOS方法通常具有计算密集型技术,如微调[39,45,2,60]、数据增强[25,33]和光流[57,2,45,33,10]。因此,这些方法通常具有低帧率和无法在线操作的特点。例如,对于只有几秒钟长的视频,方法需要几分钟[45,11]甚至几个小时[57,2],就像DAVIS的视频一样,这并不少见。
最近,VOS社区对更快的方法越来越感兴趣[40,63,10,9,24,23]。据我们所知,性能与目前技术水平相竞争的最快方法是Yang等人[66]和Wug等人[63]的方法。前者使用元网络“调制器”在测试期间快速适应分割网络的参数,而后者不使用任何微调,采用多阶段训练的编码器-解码器暹罗架构。这两种方法的运行速度都低于每秒10帧,而我们的速度要快6倍以上,而且只依赖于边界框初始化。
3、Methodology
为了实现在线可操作性和快速,我们采用了Bertinetto et al.[4]的 fully-convolutional Siamese framework。此外,为了说明我们的方法对作为起点的特定全卷积方法不可知(例如[4,31,71,67,18]),我们考虑流行的SiamFC[4]和SiamRPN[31]作为两个代表性的例子。我们首先在3.1节介绍它们,然后在3.2节描述我们的方法。
3.1、Fully-convolutional Siamese networks
SiamFC
在孪生网络对于当前帧与参考目标运算之后会得到两个特征图 ( x , z ) (x,z) (x,z),之后使用参考目标的特征图当作滑动窗口(文中对应位 response of a candidate window,RoW)在当前帧的特征图上进行滑动,计算不同位置处的cross-correlated:

其中, n n n就是对应的滑动窗口位置索引。之后 SiamFC 就在这些位置上去寻找最大响应的地方,之后通过卷积的映射关系还原出目标在当前帧的位置,使用的损失函数是Logistic Loss(记为 L s i m L_{sim} Lsim)。文章对相关性分析这块进行了改进,使用了 n ∗ c n*c n∗c 维度上的分组卷积进行实现。
SiamRPN
这个方法是在 SiamFC 的基础上进行改进的,改进之处就是给网络添加了 RPN 的网络结构,每个RoW编码 k k k 个anchor box,输出是每个框的置信度与偏移量回归,使用的损失函数是交叉熵损失函数与Smooth L1损失函数,记作 L s c o r e , L b o x L_{score},L_{box} Lscore,Lbox。
3.2、SiamMask

与现有的依靠低保真物体表征的跟踪方法不同,我们论证了产生每一帧二进制分割掩码的重要性。为此,我们表明,除了相似性分数和边界框坐标,完全卷积的连体网络的RoW也有可能编码产生像素级二进制掩码所需的信息。这可以通过扩展现有的连体追踪器,增加一个额外的分支和损失来实现。
这里假设输入的目标样本分辨率为 w ∗ h w*h w∗h ,则对应的分割分支也需要生成对应大小的mask结果 h ϕ h_{\phi} hϕ ,这是有由两层的卷积网络实现的(对于每个 RoW 都会有一个Mask),这里对分割掩膜的生成与之前的FCN类的分割方法还不太一样,其是在 RoW 的channel维度上增加,从而提升性能。因而对于第 n n n 个RoW其生成的分割掩膜为:
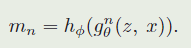
Loss function
在训练过程中,每个RoW都被贴上一个真实的二进制标签 y n ∈ ± 1 y_n∈{±1} yn∈±1,同时也与一个 w × h w×h w×h大小的像素级真实掩码 c n c_n cn相关。让 c n i j ∈ ± 1 c_n^{ij}∈{±1} cnij∈±1表示对应于第 n 个候选 RoW 中物体掩码的像素(i,j)的标签。掩膜预测任务的损失函数 L m a s k L_mask Lmask是一个在所有 RoW上 的二元逻辑回归损失:
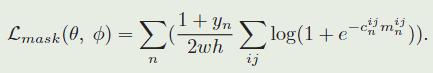
从上面的损失计算过程可以看出这里只对正样本做了损失计算。
Mask representation
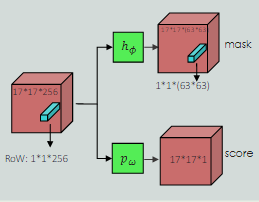
g的大小是 17 × 17 17 \times 17 17×17, h θ h_{\theta} hθ 是两个 1 × 1 1\times 1 1×1 的卷积层组成,一个是通道是256,另一个是 63 × 63 63 \times 63 63×63,大小相同能充分利用信息,对于区分相似的实例很重要。
还使用了上采样层和跳跃连接来微调mask:
refine详细结构:
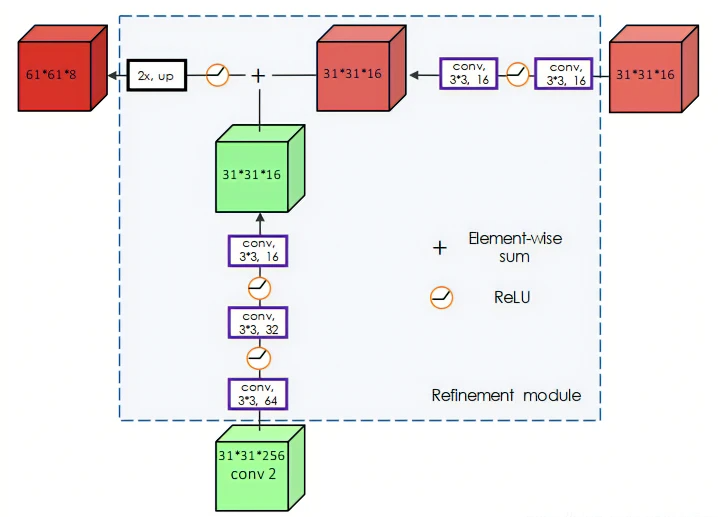
refine轮廓结构:

Two variants.
在我们的实验中,我们用我们的分割分支和loss L m a s k L_{mask} Lmask扩充了SiamFC[4]和SiamRPN[31]的架构,得到了我们所说的SiamMask的双分支和三分支变体。分别优化多任务损失 L 2 B L_{2B} L2B和 L 3 B L_{3B} L3B,定义为:
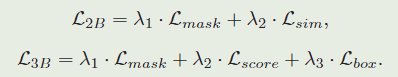
只算正样本,负样本的 y n = − 1 y_n=-1 yn=−1,设置 λ 1 = 32 , λ 2 = λ 3 = 1 \lambda_1 = 32,\lambda_2=\lambda_3=1 λ1=32,λ2=λ3=1λ 。
Box generation.

三种从mask生成bbox的方法,算是先mask后bbox了,跟普通的分割不一样
- Min-max: 对齐对称轴,红色
- MBR: 最小边界矩形,绿色
- Opt: 自动边界框生成方法,蓝色
3.3、Implementation details
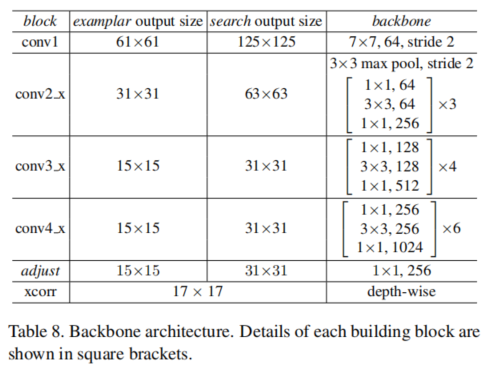

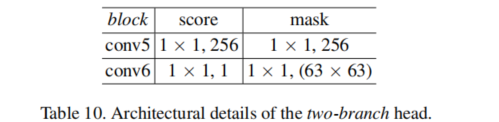
Network architecture
ResNet-50,作为 f θ f_{\theta} fθ,使用了空洞卷积增加感受野,卷积核步长为1
Training
我们分别使用127×127和255×255像素的example 和 search image patches,对这俩做随机抖动、缩放等数据增强
在ImageNet预训练的,还用了COCO,ImageNet-VID,YouTube-VOS预训练。
Inference
二分支中:取分类最高分的输出的mask(多个SiamRPN生成区域),逐像素sigmoid之后,用0.5来做mask的阈值,使用的对齐框来作为参考,来裁剪下一帧的搜索区域
三分支中:取box分支最高的分数
4、Experiments
















 288
288











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









