






本文从图网络的现有论文中梳理出了目前图网络被应用最多的数据集,主要有三大类,分别是引文网络、社交网络和生物化学图结构,分类参考了论文《A Comprehensive Survey on Graph Neural Networks》。(结尾附数据集下载链接)
1.引文网络(Cora、PubMed、Citeseer)
引文网络,顾名思义就是由论文和他们的关系构成的网络,这些关系包括例如引用关系、共同的作者等,具有天然的图结构,数据集的任务一般是论文的分类和连接的预测,比较流行的数据集有三个,分别是Cora、PubMed、Citeseer,它们的组成情况如图1所示,Nodes也就是数据集的论文数量,features是每篇论文的特征,数据集中有一个包含多个单词的词汇表,去除了出现频率小于10的词,但是不进行编码,论文的属性是由一串二进制码构成,只用0和1表示该论文有无这个词汇。
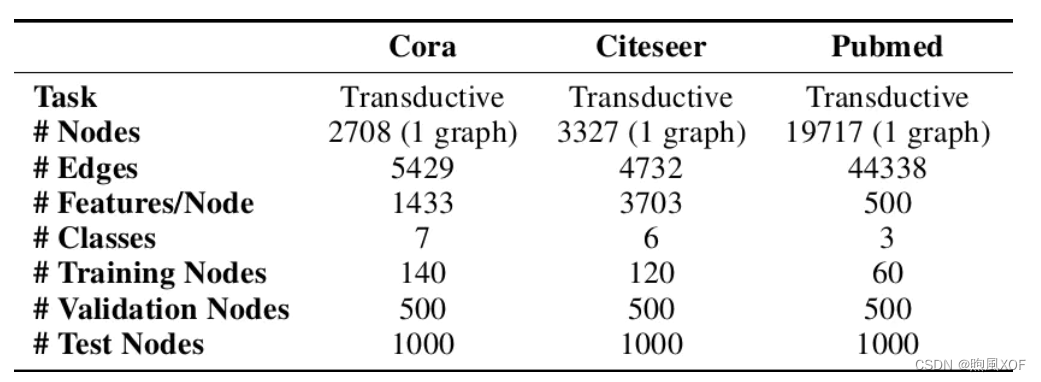
图1:引文网络流行数据集及其组成结构
文件构成
以cora数据集为例,数据集包含两个文件,cora.cites和cora.content,cora.cites文件中的数据如下:
<ID of cited paper> <ID of citing paper>
即原论文和引用的论文,刚好构成了一条天然的边,cora.content文件的数据如下:
<paper id> <word attributes> + <class label>
有论文id、上面说到的二进制码和论文对应的类别组成,其余两个数据集类似。
2.社交网络(BlogCatalog、Reddit、Epinions)
图2:社交网络示例图
BlogCatalog数据集是一个社会关系网络,图是由博主和他(她)的社会关系(比如好友)组成,labels是博主的兴趣爱好。Reddit数据集是由来自Reddit论坛的帖子组成,如果两个帖子被同一人评论,那么在构图的时候,就认为这两个帖子是相关联的,labels就是每个帖子对应的社区分类。Epinions是一个从一个在线商品评论网站收集的多图数据集,里面包含了多种关系,比如评论者对于另一个评论者的态度(信任/不信任),以及评论者对商品的评级。
文件构成
BlogCatalog数据集的结点数为10312,边条数为333983,label维度为39,数据集包含两个文件:
Nodes.csv:以字典的形式存储用户的信息,但是只包含节点id。
Edges.csv:存储博主的社交网络(好友等),以此来构图。
Epinions数据集包含文件如下:
Ratings_data.txt:包含用户对于一件物品的评级,文件中每一行的结构为user_id
item_id rating_value。
Trust_data.txt:存储了用户对其他用户的信任状态,存储方式为source_user_id
target_user_id trust_statement_value,其中信任状态只有信任和不信任(1、0)。
由于Reddit comments 数据集的文件太多,所以这里略过了,如果需要或者感兴趣的话,可以从文末的连接进入查看。
3.生物化学结构(PPI、NCI-1、NCI-109、MUTAG、QM9、Tox21)
PPI是蛋白质互作网络,数据集中共有24张图,其中20张作为训练,2张作为验证,2张作为测试,每张图对应不同的人体组织,实例如图3,该数据是为了从系统的角度研究疾病分子机制、发现新药靶点等等。
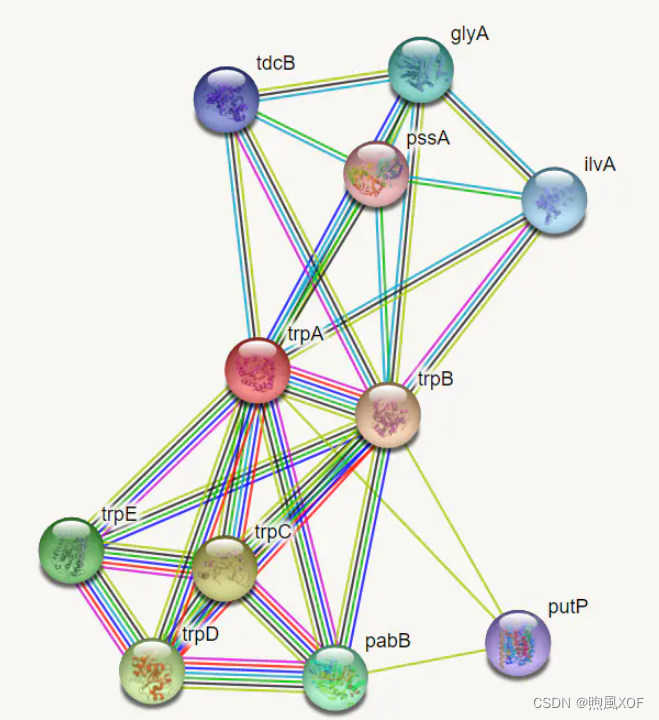
图3:蛋白质互作网络
平均每张图有2372个结点,每个结点特征长度为50,其中包含位置基因集,基序集和免疫学特征。基因本体集作为labels(总共121个),labels不是one-hot编码。
NCI-1、NCI-109和MUTAG是关于化学分子和化合物的数据集,原子代表结点,化学键代表边。NCI-1和NCI-109数据集分别包含4100和4127个化合物,labels是判断化合物是否有阻碍癌细胞增长得性质。MUTAG数据集包含188个硝基化合物,labels是判断化合物是芳香族还是杂芳族。
QM9数据集包括了13万有机分子的构成,空间信息及其对应的属性. 它被广泛应用于各类数据驱动的分子属性预测方法的实验和对比。
Toxicology in the 21st Century 简称tox21,任务是使用化学结构数据预测化合物对生物化学途径的干扰,研究、开发、评估和翻译创新的测试方法,以更好地预测物质如何影响人类和环境。数据集有12707张图,12个labels。
文件构成
PPI数据集的构成:
train/test/valid_graph.json:保存了训练、验证、测试的图结构数据。
train/test/valid_feats.npy :保存结点的特征,以numpy.ndarry的形式存储,shape为[n, v],n是结点的个数,v是特征的长度。
train/test/valid_labels.npy:保存结点的label,也是以numpy.ndarry的形式存储,形为n*h,h为label的长度。
train/test/valid/_graph_id.npy :表示这个结点属于哪张图,形式为numpy.ndarry,例如[1, 1, 2, 1...20].。
NCI-1、NCI-109和MUTAG数据集的文件构成如下:(用DS代替数据集名称)
n表示结点数,m表示边的个数,N表示图的个数
DS_A.txt (m lines):图的邻接矩阵,每一行的结构为(row, col),即一条边。
DS_graph_indicator.txt (n lines):表明结点属于哪一个图的文件。
DS_graph_labels.txt (N lines):图的labels。
DS_node_labels.txt (n lines):结点的labels。
DS_edge_labels.txt (m lines):边labels。
DS_edge_attributes.txt (m lines):边特征。
DS_node_attributes.txt (n lines):结点的特征。
DS_graph_attributes.txt (N lines):图的特征,可以理解为全局变量。
QM9的文件结构如下:
QM9_nano.npz:该文件需要用numpy读取,其中包含三个字段:
'ID' 分子的id,如:qm9:000001;
'Atom' 分子的原子构成,为一个由原子序数的列表构成,如[6,1,1,1,1]表示该分子由一个碳(C)原子和4个氢(H)原子构成.;
'Distance' 分子中原子的距离矩阵,以上面[6,1,1,1,1]分子为例,它的距离矩阵即为一个5x5的矩阵,其中行列的顺序和上述列表一致,即矩阵的第N行/列对应的是列表的第N个原子信息.
'U0' 分子的能量属性(温度为0K时),也是我们需要预测的值(分类的种类为13)
Tox21文件夹中包含13个文件,其中12个文件夹就是化合物的分类
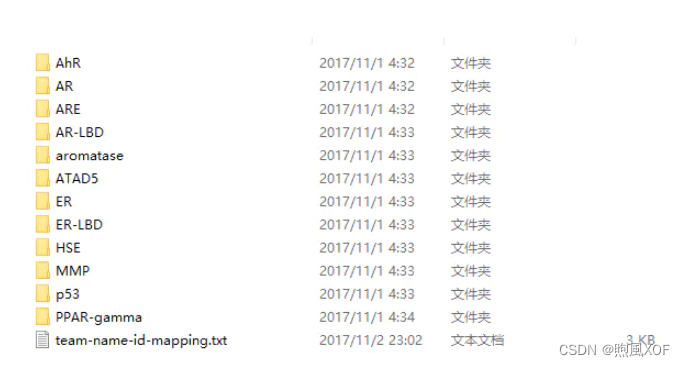
图4:Tox21数据集的文件组成
下载地址
Cora:https://s3.us-east-2.amazonaws.com/dgl.ai/dataset/cora_raw.zip
Pubmed:https://s3.us-east-2.amazonaws.com/dgl.ai/dataset/pubmed.zip
Citeseer:https://s3.us-east-2.amazonaws.com/dgl.ai/dataset/citeseer.zip
BlogCatalog:http://socialcomputing.asu.edu/datasets/BlogCatalog
Reddit:https://github.com/linanqiu/reddit-dataset
Epinions:http://www.trustlet.org/downloaded_epinions.html
PPI:http://snap.stanford.edu/graphsage/ppi.zip
NCI-1:https://ls11-www.cs.uni-dortmund.de/people/morris/graphkerneldatasets/NCI1.zip
NCI-109:https://ls11-www.cs.uni-dortmund.de/people/morris/graphkerneldatasets/NCI109.zip
MUTAG:https://ls11-www.cs.uni-dortmund.de/people/morris/graphkerneldatasets/MUTAG.zip
QM9:https://github.com/geekinglcq/QM9nano4USTC
Tox21:https://tripod.nih.gov/tox21/challenge/data.jsp

















 6347
6347

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









