







0. 什么是可变形卷积
可变形卷积: Deformable Convolutional Networks
原文下载链接地址
原文摘要:卷积神经网络(CNNs)由于其构建模块中存在固定的几何结构,因此固有地局限于模型几何转换。在本工作中,我们引入了两个新的模块来增强cnn的转换建模能力,即可变形卷积和可变形感兴趣区域池。两者都是基于用额外的偏移量来增加模块中的空间采样位置,并学习来自目标任务的偏移量,而无需额外的监督。新的模块可以很容易地取代现有cnn中的普通对应模块,并且可以很容易地通过标准的反向传播进行端到端训练,从而产生可变形的卷积网络。大量的实验验证了我们的方法的性能。我们首次证明,在深度cnn中学习密集的空间转换对于复杂的视觉任务是有效的。
下图中
- (a)是传统的标准卷积核,尺寸为3x3(图中绿色的点);
- (b)就是我们今天要谈论的可变形卷积,通过在图(a)的基础上给每个卷积核的参数添加一个方向向量(图b中的浅绿色箭头),使的我们的卷积核可以变为任意形状;
- (c)和(d)是可变形卷积的特殊形式。
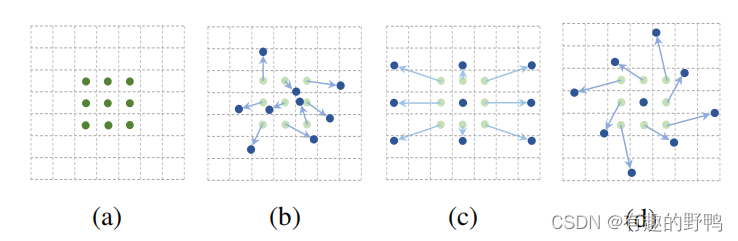
可变形卷积是指卷积核在每一个元素上额外增加了一个参数方向参数,这样卷积核就能在训练过程中扩展到很大的范围。
1.为什么要用可变形卷积
CNNs对大型,未知形状变换的建模存在固有的缺陷,这种缺陷来源于CNNs模块固有的几何结构:
- 卷积单元对输入特征图的固定位置进行采样;
- 池化层以固定的比例进行池化;
即使是ROI pooling也是将ROI分割到固定的bin中去。这些特性是有影响的,例如,在同一层Conv中,所有的激活单元的感受野是一样的,但由于不同位置可能对应着不同尺度或变形的物体,因此对尺度或者感受野大小进行自适应是进行精确定位所需要的。为了解决或者减轻这个问题,本文提出了两种新的模块,可变形卷积(deformable conv)和可变形感兴趣区域池化(deformable ROI Pooling),来提高对形变的建模能力。这两个模块都是基于一个平行网络学习offset(偏移),使得卷积核在input feature map的采样点发生偏移,集中于我们感兴趣的区域或者目标。通过研究发现,标准卷积中的规则格点采样是导致网络难以适应几何形变的“罪魁祸首”,为了削弱这个限制,对卷积核中每个采样点的位置都增加了一个偏移变量,可以实现在当前位置附近随意采样而不局限于之前的规则格点。
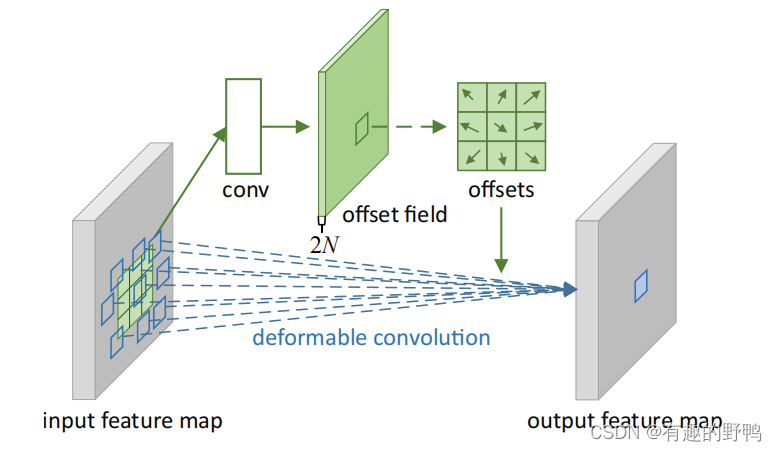
2.偏移量的计算
假设输入的特征图为WxH,将要进行的可变性卷积为kernelsize=3x3,stride=1,dialated=1,那么首先会用一个具有与当前可变性卷积层相同的空间分辨率和扩张率的卷积(这里也要k=3x3,s=1,dial,才能保证偏移个数一致)进行学习offset。conv会输出一个WxHx2N的offset filed(N是可变性卷积的3x3=9个点,2N是每个点有x和y两个方向向量)。之后,可变形卷积核会根据偏移量进行卷积。
2.可变形卷积的代码
class DCNv2(nn.Module):
def __init__(self, in_channels, out_channels, kernel_size, stride=1,
padding=1, dilation=1, groups=1, deformable_groups=1):
super(DCNv2, self).__init__()
self.in_channels = in_channels
self.out_channels = out_channels
self.kernel_size = (kernel_size, kernel_size)
self.stride = (stride, stride)
self.padding = (padding, padding)
self.dilation = (dilation, dilation)
self.groups = groups
self.deformable_groups = deformable_groups
self.weight = nn.Parameter(
torch.empty(out_channels, in_channels, *self.kernel_size)
)
self.bias = nn.Parameter(torch.empty(out_channels))
out_channels_offset_mask = (self.deformable_groups * 3 *
self.kernel_size[0] * self.kernel_size[1])
self.conv_offset_mask = nn.Conv2d(
self.in_channels,
out_channels_offset_mask,
kernel_size=self.kernel_size,
stride=self.stride,
padding=self.padding,
bias=True,
)
self.reset_parameters()
def forward(self, x):
offset_mask = self.conv_offset_mask(x)
o1, o2, mask = torch.chunk(offset_mask, 3, dim=1)
offset = torch.cat((o1, o2), dim=1)
mask = torch.sigmoid(mask)
x = torch.ops.torchvision.deform_conv2d(
x,
self.weight,
offset,
mask,
self.bias,
self.stride[0], self.stride[1],
self.padding[0], self.padding[1],
self.dilation[0], self.dilation[1],
self.groups,
self.deformable_groups,
True
)
return x
def reset_parameters(self):
n = self.in_channels
for k in self.kernel_size:
n *= k
std = 1. / math.sqrt(n)
self.weight.data.uniform_(-std, std)
self.bias.data.zero_()
self.conv_offset_mask.weight.data.zero_()
self.conv_offset_mask.bias.data.zero_()
class Bottleneck_DCN(nn.Module):
# Standard bottleneck with DCN
def __init__(self, c1, c2, shortcut=True, g=1, k=(3, 3), e=0.5): # ch_in, ch_out, shortcut, groups, kernels, expand
super().__init__()
c_ = int(c2 * e) # hidden channels
if k[0] == 3:
self.cv1 = DCNv2(c1, c_, k[0], 1)
else:
self.cv1 = Conv(c1, c_, k[0], 1)
if k[1] == 3:
self.cv2 = DCNv2(c_, c2, k[1], 1, groups=g)
else:
self.cv2 = Conv(c_, c2, k[1], 1, g=g)
self.add = shortcut and c1 == c2
def forward(self, x):
return x + self.cv2(self.cv1(x)) if self.add else self.cv2(self.cv1(x))
class C2f_DCN(nn.Module):
# CSP Bottleneck with 2 convolutions
def __init__(self, c1, c2, n=1, shortcut=False, g=1, e=0.5): # ch_in, ch_out, number, shortcut, groups, expansion
super().__init__()
self.c = int(c2 * e) # hidden channels
self.cv1 = Conv(c1, 2 * self.c, 1, 1)
self.cv2 = Conv((2 + n) * self.c, c2, 1) # optional act=FReLU(c2)
self.m = nn.ModuleList(Bottleneck_DCN(self.c, self.c, shortcut, g, k=(3, 3), e=1.0) for _ in range(n))
def forward(self, x):
y = list(self.cv1(x).split((self.c, self.c), 1))
y.extend(m(y[-1]) for m in self.m)
return self.cv2(torch.cat(y, 1))















 5788
5788











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











