







 该论文深入探讨了自监督学习中出现的维度坍塌问题,即使在使用正负样本对的对比学习方法下,依然存在非完全坍塌的情况。作者通过理论分析和实验证据,揭示了两种导致坍塌的机制:(1)强数据增广引起权重坍塌,(2)潜在的正则化导致低秩解。此外,提出了DirectCLR算法,通过直接使用特征子向量避免坍塌。实验表明DirectCLR在保持表征质量的同时,成功防止了维度坍塌。
该论文深入探讨了自监督学习中出现的维度坍塌问题,即使在使用正负样本对的对比学习方法下,依然存在非完全坍塌的情况。作者通过理论分析和实验证据,揭示了两种导致坍塌的机制:(1)强数据增广引起权重坍塌,(2)潜在的正则化导致低秩解。此外,提出了DirectCLR算法,通过直接使用特征子向量避免坍塌。实验表明DirectCLR在保持表征质量的同时,成功防止了维度坍塌。
论文标题
Understanding dimensional collapse in contrastive self-supervised learning
论文作者、链接
作者:Jing, Li and Vincent, Pascal and LeCun, Yann and Tian, Yuandong
链接:https://arxiv.org/abs/2110.09348
Introduction逻辑(论文动机&现有工作存在的问题)
自监督学习:目标是在没有人工标注的情况下学习有用的特征表示——琐碎解:模型将所有的输入映射到一个恒定的向量中——常见的避免琐碎解(模型坍塌)的方法有:正\负样本对;利用梯度停止+额外的预测器;额外的聚类步骤;最小化两个分支的冗余——在一些情况下会出现,非完全崩溃:指在某一个特定的维度崩溃,这种情况也称之为维度崩溃——在利用正负样本对的模型中,在推远负样本的过程中会避免维度崩塌,并且可以利用到所有的维度(然而事实是仍然存在维度崩塌的问题)
本文介绍了两种导致崩塌的机制:(1)沿着特征方向,当数据增广引起的方差大于数据分布引起的方差时,权值崩溃(2)即使数据增广的协方差在所有维度上都比数据方差小,但由于权重矩阵在不同层的相互作用,即隐式正则化,权重仍然会崩溃。
论文核心创新点
证明了自监督学习总是收到维度崩塌的影响,即所有嵌入向量都落入一个低维子空间,而不是整个可用嵌入空间
证明了这两个机制导致维度崩塌:(1)沿着特征维度的强增广(2)潜在正则化驱使模型生成低级解
提出了DiretCLR
相关工作
自监督学习
潜在正则化
论文方法
特征崩塌
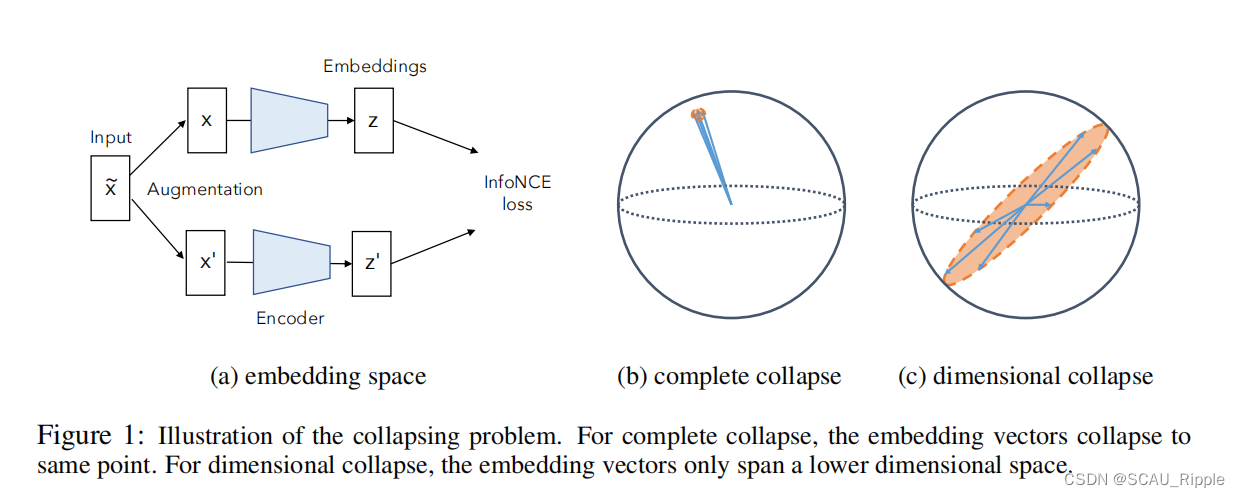
如图1(a)所示,自监督学习通过最小化嵌入向量之间的距离学习有用的特征。这可能导致如图1(b)所示的崩塌解。对比学习方法通过推远负样本对来避免完全崩塌解。本节将证明,这样的方法只能避免完全崩溃,但是维度崩溃仍然存在。
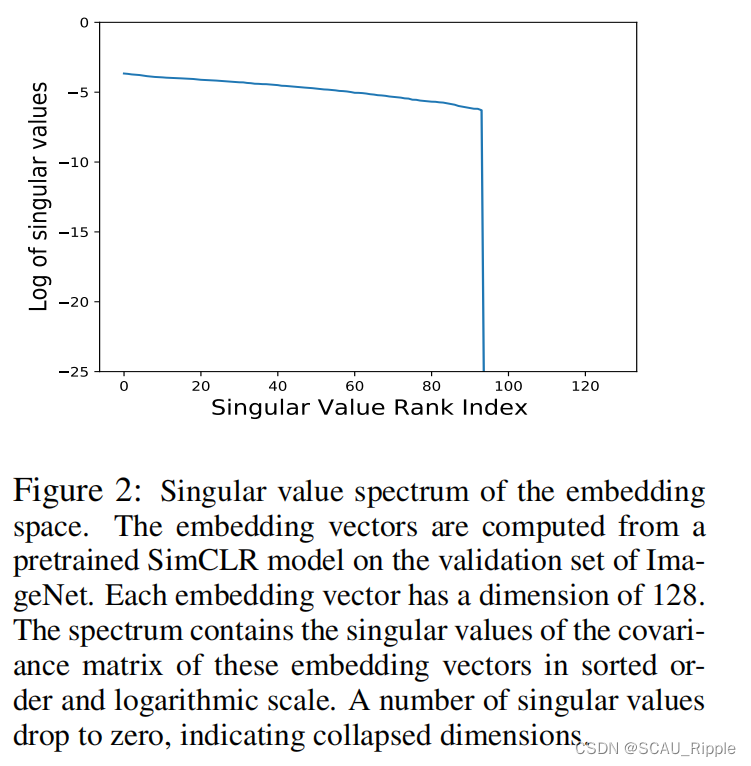
对带两层MLP投影器的SimCLR模型训练100轮,然后通过收集在验证集的嵌入向量来对维度进行评估。每个嵌入向量的的尺寸是。对嵌入层计算一个协方差矩阵
(这里有
,其中
是样本的总数)
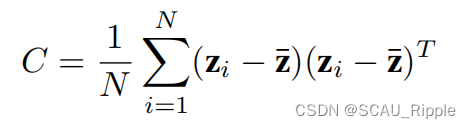
图2展示了该协方差矩阵的奇异值分解通过对数尺度
进行排序。我们观察到许多奇异值坍缩为零,从而表示坍缩维度。
强力增广导致的维度崩塌
线性模型
在这一节中,解释了一种对比学习的场景,即折叠嵌入维度,其中增广的信息超过输入信息。聚焦于一个简单的线性网络,将输入向量记为,然后增广手法是对其增加一些噪音,网络的权值矩阵是
。因此,嵌入向量为
,然后使用InfoNCE作为对比损失,即:
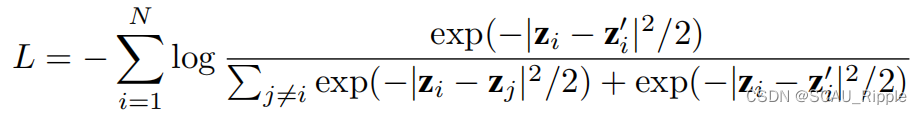
其中和
是两个分支的嵌入向量,
表示负样本。 对
和
进行正则化,使其成为一个统一的向量,可以用内积
来代替负距离
。用不带动量或者是权值减小的随机梯度下降来训练模型。
梯度传播的动力
我们通过梯度流来研究动力,即以无穷小的学习率梯度下降。
引理1:在一个线性对比自监督学习模型中,权重矩阵可以由以下解出:
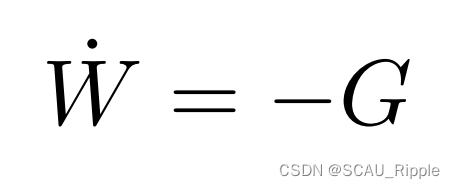
其中,![]() ,并且
,并且是在嵌入向量
上的梯度(
同理)。
这很容易用链式法则证明。对于InfoNCE损失,每个分支的嵌入向量的梯度可以写成如下:
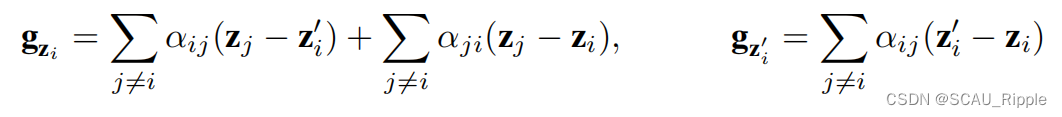
其中,是
和
之间的经过softmax之后的相似性,有如下定义:
因此,。又因为有
![]() 于是有:
于是有:
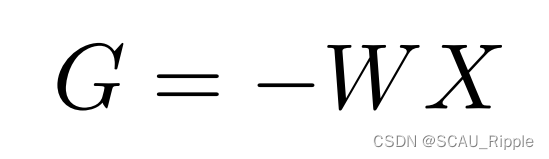
其中
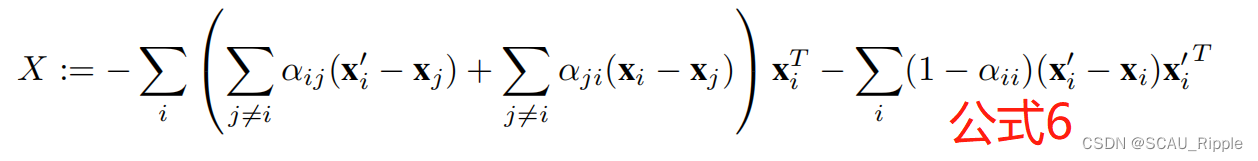
引理2:
是两个PSD矩阵的差值(PSD矩阵应该是半正定矩阵,作者好像没讲,我搜索了之后感觉是这样):
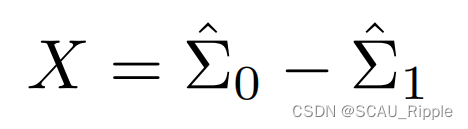
其中,(这两条公式的证明在附录中)
![]() 是加权数据分布协方差矩阵
是加权数据分布协方差矩阵
![]() 是加权增广分布协方差矩阵
是加权增广分布协方差矩阵
因此增广的幅度决定了X是否是正定矩阵。引理2还将权重的时间导数建模为:a product of
and a symmetric and/or PSD matrices(这句话我实在不知道怎么翻译)。引理2适用于有多个负对比项的InfoNCE,当
随样本对
变化时仍然成立,在有batch-szie
下成立
在给定的性质的情况下,研究权矩阵
的动力
定理1:一个固定的矩阵和一个强增广,导致矩阵
有负的向量值,权值矩阵
会有部分奇异值消失。
推论1:(由强增广导致的维度崩塌)在使用强增广的情况下,嵌入空间的协方差矩阵会变成低秩的。
利用嵌入协方差矩阵的奇异值谱识别嵌入空间,。由于
奇异值消失,
也是低秩的,表示维数坍缩。
数值模拟验证了我们的理论。我们选择输入数据为:具有协方差矩阵的各向同性高斯数据,。选择将增广设置为具有协方差矩阵的加性高斯函数(additive Gaussian):
,块的大小为8x8。在图3中绘制了不同增幅幅度k的权值矩阵奇异值谱:

这证明了在线性网络的设定下,在嵌入空间中,强增广会导致维度崩塌。
对于复杂的非线性网络,强增广仍然会导致崩塌的情形,但是解释的角度不同。强增广取决于一定网络容量条件下的增广的更复杂性质(增广的高阶统计量,增广与数据分布的流形性)。
潜在归一化导致的维度崩塌
两层线性模型
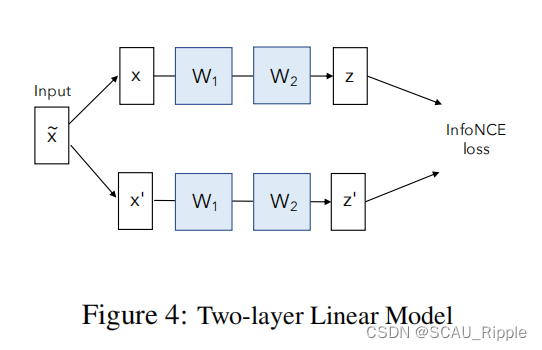
在强增广的条件下,在InfoNCE损失指导下的线性模型会出现维度崩塌。然而,这种情况下依赖于网络容量是有限的的情况,实际上可能不成立。另一方面,当没有强增广的时候,并且因此
矩阵仍然是PSD,一个线性模型也不会出现维度崩塌。然而实际情况下深度神经网络仍然会出现崩塌。下文将从另一个方面揭示:潜在归一化,导致过度参数化的线性模型倾向于找到一个低秩的解。
为了理解这个反直觉的情况,我们先设定一个最简单的过度参数化的设定,将网络设置成为一个2层的MLP并且没有偏置值。这两个MLP的权重矩阵记为和
。输入向量记为
然后其增广为添加了额外的噪音。于是每个分支输出的嵌入向量为:
,因此
,不对
进行归一化,最后使用InfoNCE作为损失函数。在没有动量或是权重减小的情况下使用随机梯度下降对模型进行训练。
梯度流动力
与引理1相似,推导了两个权矩阵W1和W2上的梯度流。
引理3:引理1中定义了由演化的两层线性对比自监督学习模型的权值矩阵:
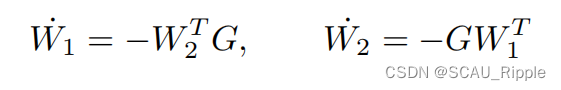
该式可以用链式法则证明。对于两层的情况,对于有一个具体的形式:
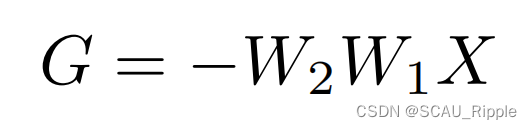
其中由上文中的公式6定义。根据推论2,我们得知,在小增广的情况下,
是一个正定矩阵。
权重对齐
至此我们又了两个矩阵和
,第一个问题是它们如何相互影响。在两个矩阵上都应用SVD分解,即
和
,以及
和
。对齐受到相邻的标准正交矩阵之间的影响,即:
。这可以通过对齐矩阵来表示,
,其中矩阵中的
实例,代表了 第
个的
的右边的奇异值向量
和 第
的
的左边的奇异值向量
的对齐。
定理2:(权重矩阵对齐)对于所有的,有
,
是一个正定矩阵,并且
具有不同的奇异值,那么对齐矩阵有
同时,通过实验证明了在InfoNCE损失的指导下,对齐矩阵的绝对值收敛到一个单位矩阵,见图5。

现实情况下很多假设是不成立的,比如权值矩阵中存在退化奇异值,不能做到完美对齐。事实上,给定退化的奇异值,奇异分解不再是唯一的。在实验过程中,人为的将权重矩阵初始化为没有退化奇异值的矩阵。在实际情况下,权重矩阵是随机初始化的,将会观察到权重矩阵收敛到一个分块对角矩阵,其中每一个块代表一组退化的奇异值。
考虑到奇异向量对应于相同奇异值对齐,我们现在可以研究每个权矩阵和
的奇异值的动力
定理3:如果是对齐的(即
),那么它们的奇异值在InfoNCE损失的影响下演化为:
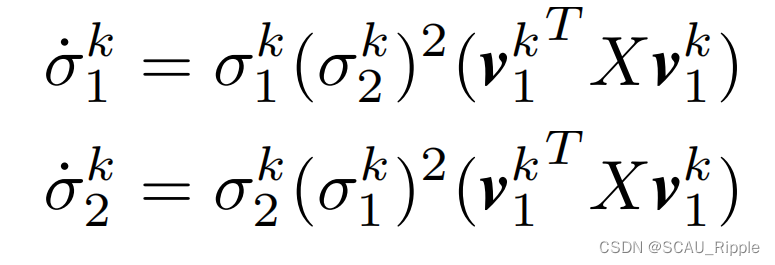
根据公式10,有。我们用解析法求解奇异值动力,
。这表示一对奇异值有与自身成比例的梯度。值得注意的是,
是一个正定矩阵,项
是恒为非负的。这解释了为什么我们观察到的最小组的奇异值很明显增长缓慢。由图6(a)的实验证明该点。
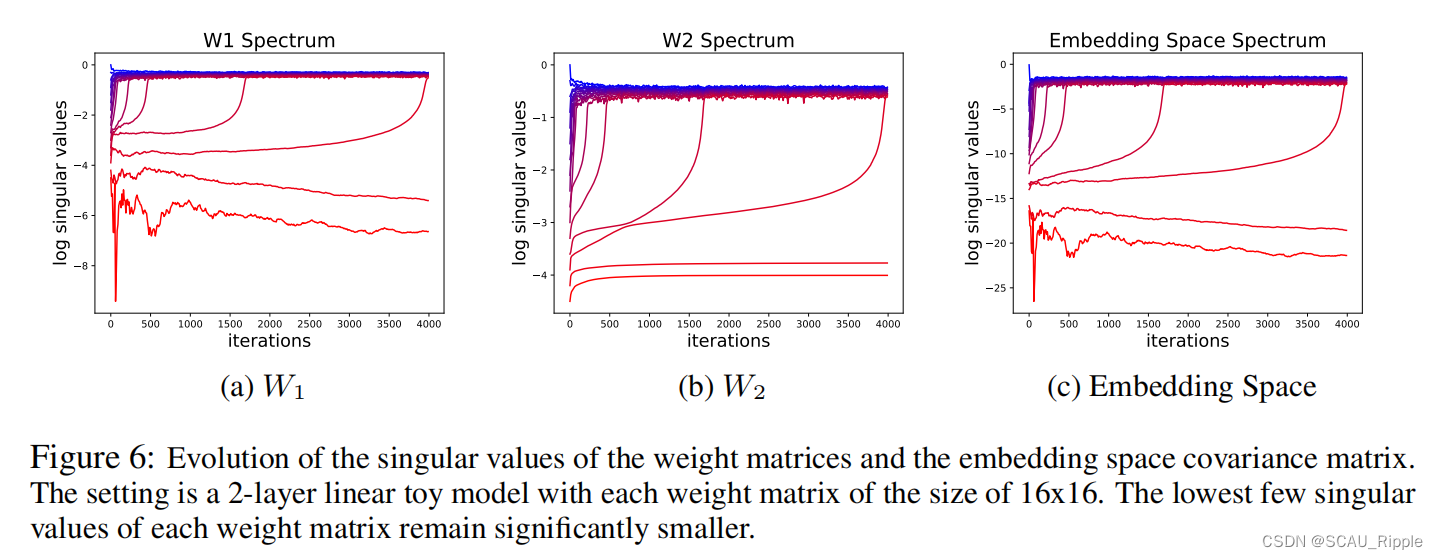
推论2:(由潜在归一化导致的维度崩塌)在有小增广和过度参数化的线性模型下,嵌入空间中的协方差矩阵会变成低秩的。
嵌入空间由基于嵌入向量的协方差矩阵的奇异值谱所确定,即。随着
演化为低秩的,
也变成低秩的,表现为维度崩塌。如图6(c)见实验。
DirectCLR
动机
通过上文的发现去设计一个新颖的算法。根据经验,添加一个投影器大大提高了学习表征的质量和下游任务性能(SimCLR)。检查表示层的光谱也可以发现使用/不使用投影器的差异,见图7(b)。
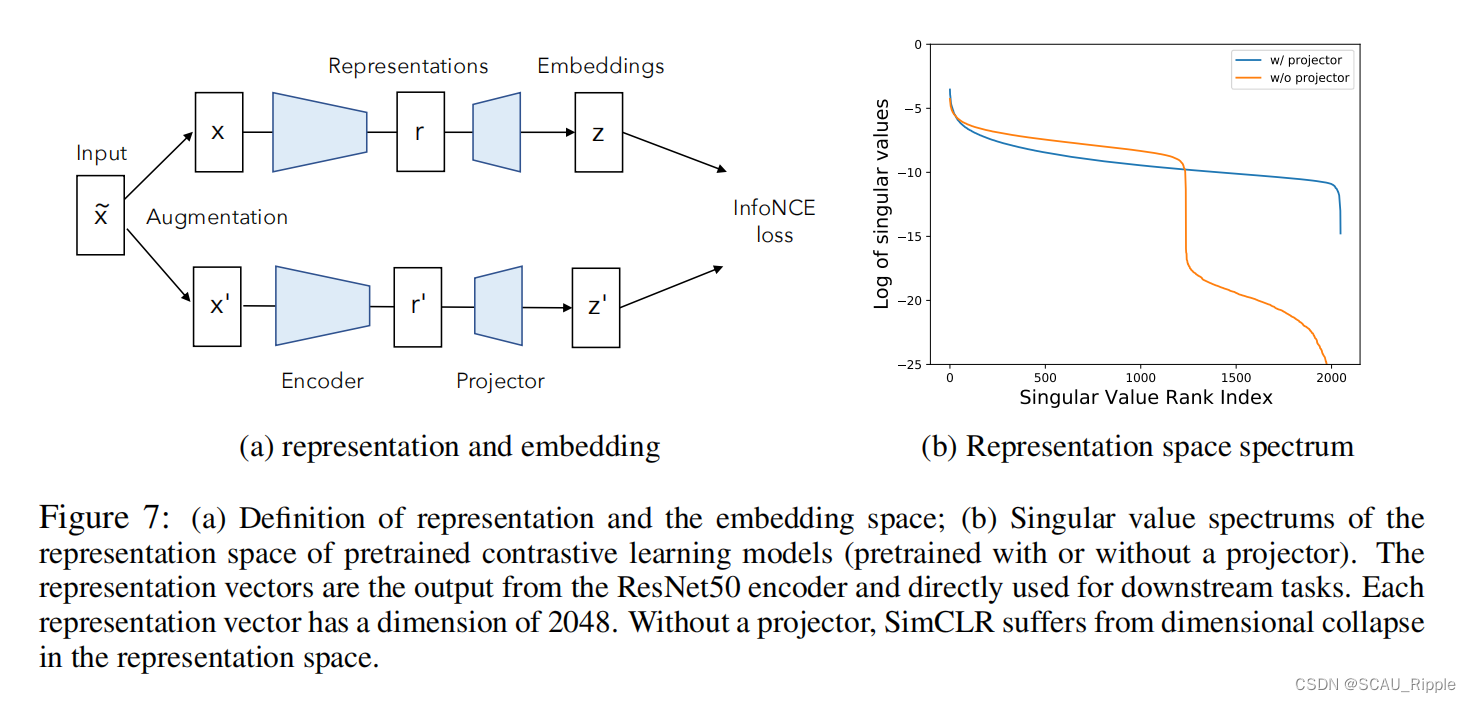
在没有投影器的时候,模型出现了维度崩塌。因此。投影器避免了在特征空间的崩塌。
投影器在对比学习中,起到了关键的避免维度崩塌的情况。
在对比学习模型中,我们提出以下关于线性投影仪的建议:
建议1:线性投影器的权重矩阵只需要是对角化的。
建议2:线性投影器的权重矩阵只需要是低秩的。
基于潜在归一化的理论,我们希望看见邻接层进行对齐,使整体动力仅由它们的奇异值
和
控制。正交矩阵
和
是多余的,他们会演化成
。
现在考虑SimCLR的线性投影器的通道维度。是编码器的最后一层的权重矩阵,
是投影器的权重矩阵。 对于投影器矩阵
,正交分量
可以省略。因为前一层的
已经被训练好了,其正交分量
总是满足
。因此,投影仪的最终表现仅由投影仪权值矩阵的奇异值(
)决定。于是有了建议1:权矩阵的正交分量不重要。我们可以把投影仪矩阵设为对角矩阵。并且,权重矩阵总是会收敛到低秩。奇异值对角矩阵自然也变成低秩的了,所以为什么不直接将其设置成低秩的呢?于是有了建议2。
主要想法
本文建议去移除对比学习中的投影器,通过直接将特征向量的子向量送到损失函数计算。将模型命名为DirectCLR,见图8。
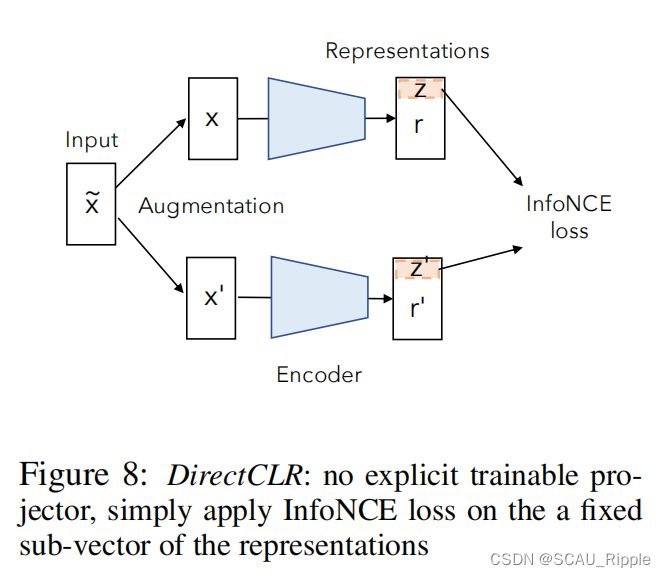
DirectCLR之间选择特征的一个子向量,其中
是超参。然后在正则化的子向量上应用InforNCE损失,即
。
在和SimCLR同等条件下的训练结果:

对潜在特征空间的光谱如图9所示。DirectCLR避免了维度崩塌,和带投影器的SimCLR的效果一样。
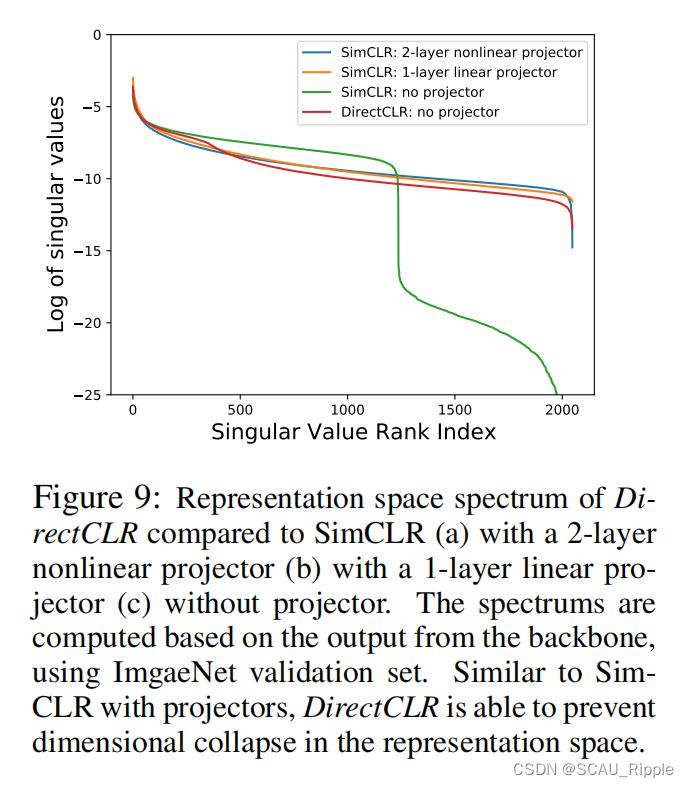
有人可能会怀疑,在DirectCLR的对比损失不应用梯度的其余部分的表示向量,那么为什么这些维度会包含有用的信息?
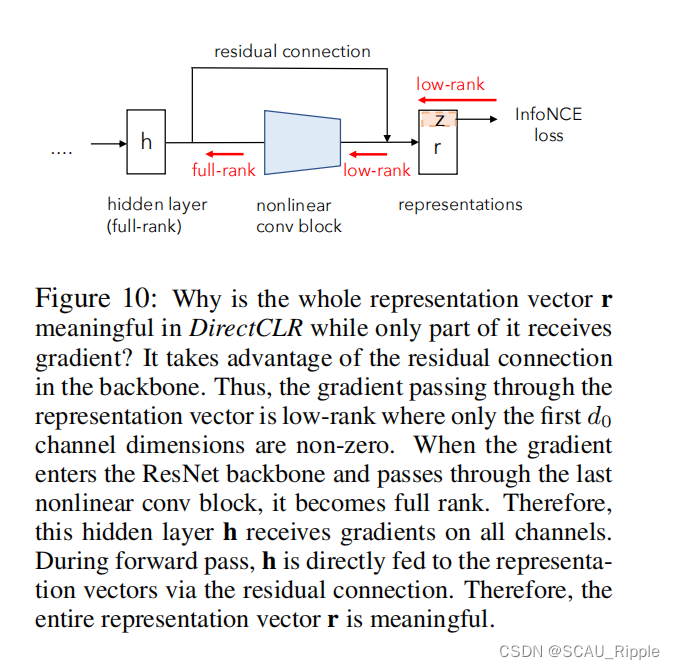
如图10所示,通过梯度反向传播回来的向量是低秩的,只有前个通道维度是非零的。当梯度进入主干网络后,穿过最后的非线性传播块,就变成了满秩的。因此,隐藏层
收到了所有通道的梯度。注意到
都是相同的维度,即2048。然后我们考虑前向传播,隐藏层
通过残差链接直接输入特征向量。因此,表示向量
的其余部分并不是微不足道的。
免责声明:DirectCLR能够取代线性投影器,并在理解线性投影仪的动力学方面验证两个命题。但我们的理论不能完全解释为什么非线性投影仪能够防止维度坍塌。DirectCLR仍然依赖于非线性投影器的机制来防止维度坍塌,这是由骨干的最后一块有效执行的,如上所述。
消融实验设计
对于投影器的消融
一句话总结
带来了一种不用投影器projector也能防止模型坍塌的新思路

















 990
990

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









