







论文标题
Partially view-aligned representation learning with noise-robust contrastive loss
论文作者、链接
作者:Yang, Mouxing and Li, Yunfan and Huang, Zhenyu and Liu, Zitao and Hu, Peng and Peng, Xi
链接:CVPR 2021 Open Access Repository
代码:https://github.com/XLearning-SCU/2021-CVPR-MvCLN
Introduction逻辑(论文动机&现有工作存在的问题)
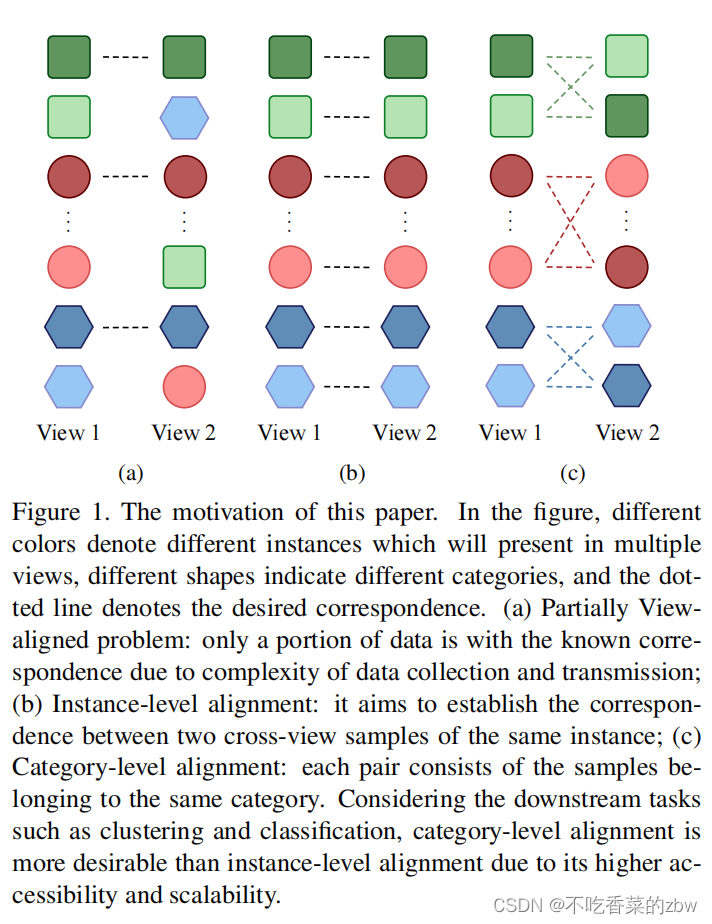
多视图表征学习Multi-view Representation Learning (MvRL),目的是从多视图数据中学习到恒定的特征表示——现有的方法往往有两个依赖:数据视图的一致性和完备性,少了其中一个条件,多视图表征学习就失效了——但是现实情况下这两个条件往往在数据收集和传输时导致不成立——于是,问题转化为了部分数据丢失问题Partially Data-missing Problem (PDP)和部分视图对齐问题Partially View-aligned Problem (PVP)
本文笔尝试在没有标签的情况下解决PVP问题——理想情况下,数据是对齐的——简单解法是直接使用匈牙利算法 (Hungarian algorithm)对视图进行预处理,构建两个视图的相关视图——匈牙利算法存在的缺点:(1)不能应用在多视图的行空间(2)没有利用到数据之间的相关性——部分对齐视图聚类(Partially View-aligned Clustering ,PVC)提出了一种可微神经模块的匈牙利算法,从而可以实现数据对齐和表示学习在一个阶段的方式——但是这两种算法目标都是实例级的对齐,这可能导致多视图聚类和分类过拟合——层级对齐比实例级对齐的需求更高——对于交叉视图的实例,对齐正确的概率有1/N或者1/K(实例级和类别级),即,类别级对齐的概率更高(K<<N)
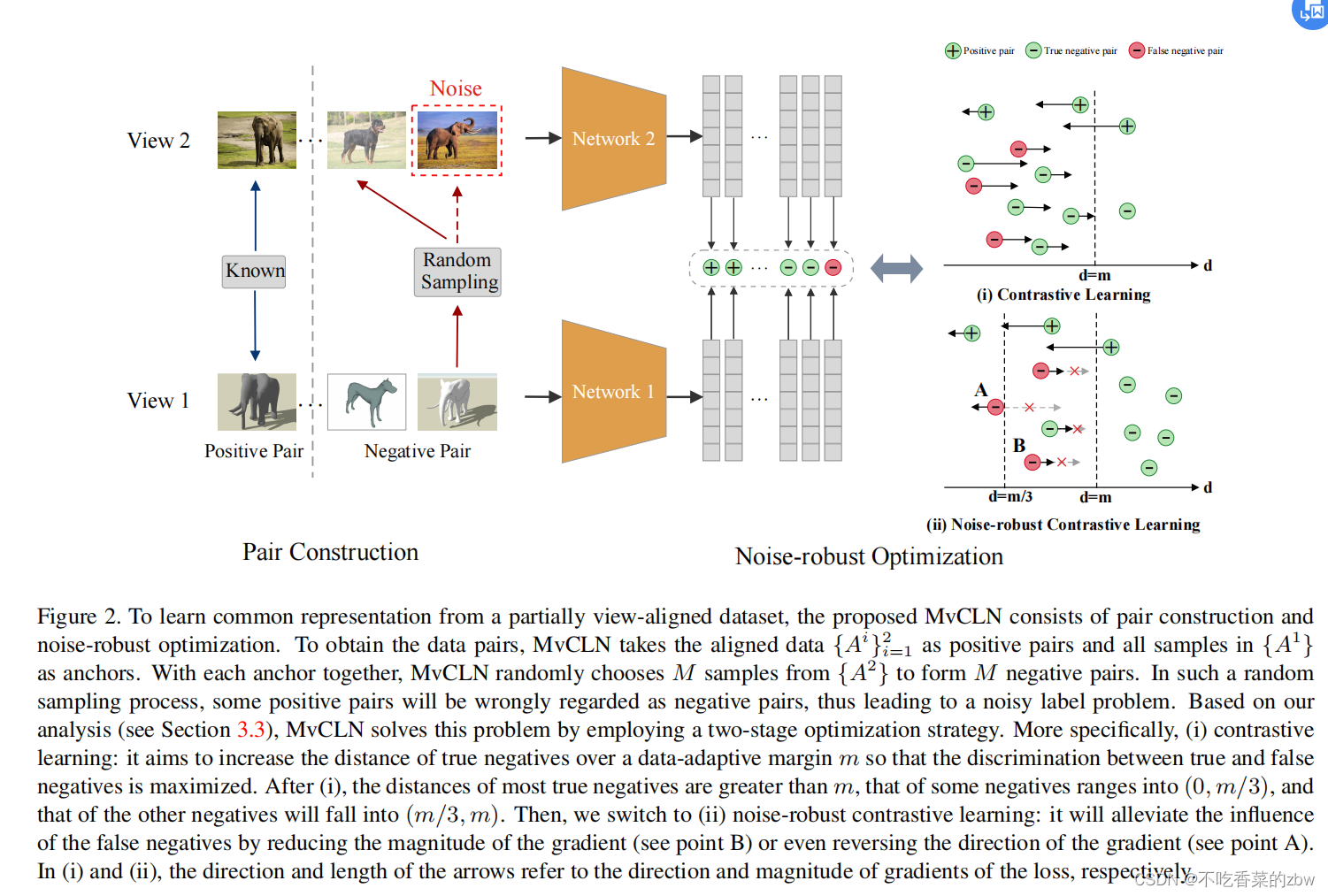
基于上面的观察,本文解决PVP问题通过:类别级的对齐而不是实例级的对齐,如图1(c)所示。提出了Multi-view Contrastive Learning with Noise-robust loss (MvCLN)算法,基本思想是将视图对齐问题重新解释为一种识别任务,即,以双视图数据为例,对于一个视图中的每个样本,MvCLN旨在从另一个视图中识别属于同一类别的对应对象——样本对的构建:将对齐的数据视为正对,使用随机抽样构造负对(NP)——为了减轻甚至消除假阴性的样本对,设计了抗噪音的对比损失(noise-robust contrastive loss)
论文核心创新点
(1)提出了聚类似的一对多映射任务,提出了通过层级对齐而不是实例对齐来解决PVP问题。
(2)将对齐问题重新解释为视图辨别问题,通过一个对比学习模型来解决这个问题。
(3)通过建立视图之间的相关性来设计对比损失,提出了抗噪音的对比损失。传统的带噪声标签被定义为对分类等监督任务的不正确标注。相反,这项工作提出的观点对应可能是错误的,这与传统的定义有显著的不同。
相关工作
多视图特征学习
对比学习
含噪音的标签学习
论文方法
Problem Formulation问题公式化
取为一个部分视图对齐的数据集,即
,其中
代表视图的数量,对齐和非对齐的视图分别记作
和
。目标是利用对齐视图
来对齐非对齐视图
,并同时对整个数据集学习一个共同的特征表达。
取举例,当
和
属于同一个类时,该数据集是对齐的,即:
![]()
其中,代表
所属的类别。于是,类别级的对齐问题,就变成了解决一个识别问题,即使得
和
满足上述公式。
为了完成识别任务,类别级的对比学习的目标变成增大正样本对的相似性,同时减小负样本对的相似性。但是,对比学习不能直接用于识别任务。一方面,已经包含了正样本对,于是剩下的问题是如何构造构造负样本对。另一方面,在没有标签数据的帮助下,不可避免的会得到一些含有噪音的负样本对。因此,本文提出使用随机采样的方法生成负样本对。具体来说,从
随机选择两个样本
和
,当
的时候,作为负样本对。直觉上来说,构建样本对的时候有
的概率是含噪音的样本对,当类别数是不均匀的时候。因此,目标是使对比学习对噪声标签(即假阴性)具有鲁棒性。
Noise-robust Contrastive Loss 噪音鲁棒对比损失
为了减轻假阴性的影响,提出如下损失函数:

其中是数据对的数量,
代表正/负样本对。
对于正样本交叉视图和
,目标是最小化它们俩之间的距离,即
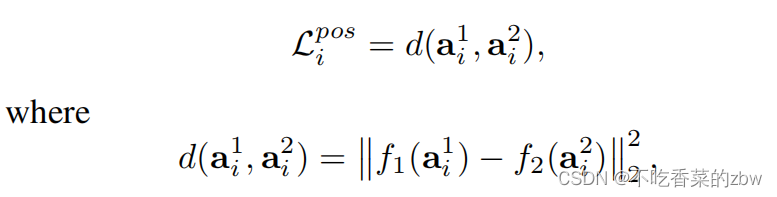
代表两个参数化的神经网络,将两个视图映射到潜在空间
为避免琐碎解,又加入了以下这一项:
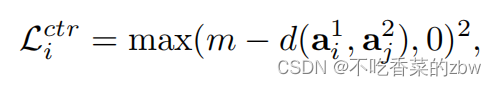
其中,是一个阈值,使得负样本直之间的距离比较大,
是负样本对。由于上述损失没有明确包含对噪声标签的鲁棒性,它会混淆真阴性和假阴性,从而导致性能下降。为了增加对假阴性的鲁棒性,提出以下损失:
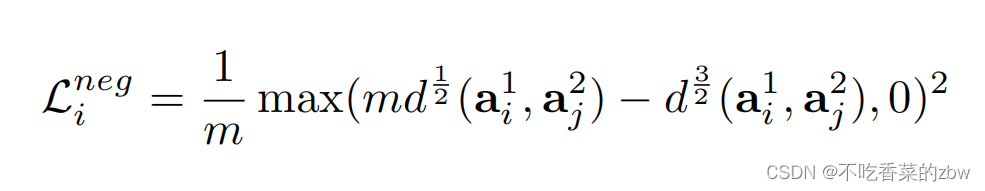
其中m是一个阈值,只在初始化阶段计算,通过以下公式:

其中分别是正样本和负样本的数量。公式6可以使得模型避免对假阴性样本对形成过拟合。
Analysis on the Proposed Loss对提出的损失函数的分析
计算的梯度
,即,负样本的距离变成0,只考虑
,即:

然后或者是
。性能分为两个区域,即,
和
。对关于负样本的上述损失,进行可视化如下:
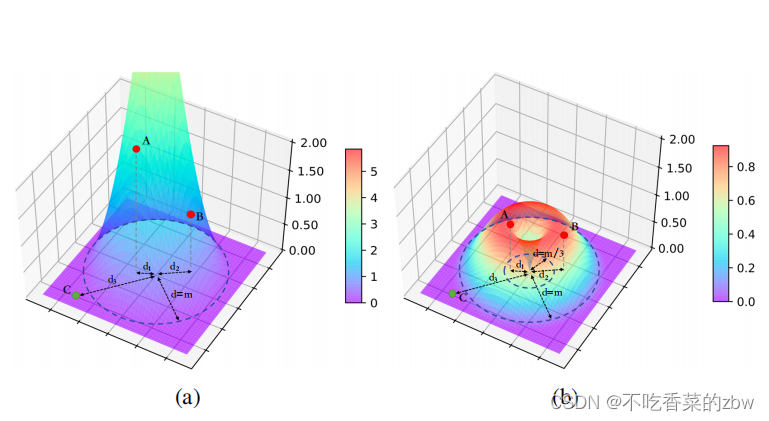
从图中可以观察到,比起简单版的损失,对噪音有鲁棒性的损失,不会单调地增加负对的距离,从而具有以下两个特点:
(1)反向优化():对于那些坐落在孔区域的负样本对,本文提出的损失函数的梯度会反向,因此负样本对的距离会减少。
(2)慢优化():对于落在
区域的样本,优化速度会比简单损失的速度要慢,因为梯度总是和负值相关的,并且公式中前者的梯度总是比后者的大,即:
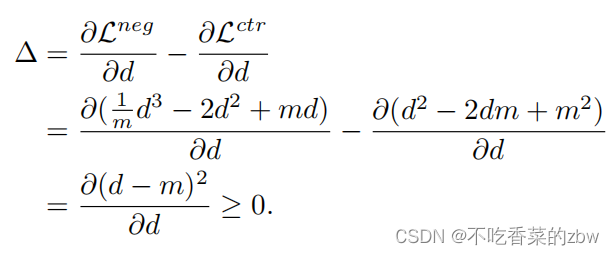
如果假阴性被约束为,第一个特征可以用来消除假阴性的影响。交替地,第二项可以通过将假阴性约束到
来减轻假阴性的影响。于是,问题就变成了如何将假阴性和真阴性样本对区分开来。
Bengio et al通过经验发现,神经网络容易首先适应简单的模式,这为我们提供了动机。具体来说,本文提出了一个TNP,可以被视为一种简单的模式,然后FNP是一种比较复杂的模式。因此,我们有理由推测,具有简单对比损失的神经网络比FNP更快地适应TNP,如下图

更具体地说,从图中可以看出,由于TNP拟合速度更快,在训练早期TNP和FNP vanilla之间存在差距。
基于上述观察,我们提出采用两阶段优化策略来区分FNP和TNP基于上述观察。即,第一阶段应用简单对比损失去优化模型,到一个所有负样本对的平均距离比要大。结果是,由于TNP的拟合速度快,大多数TNP和FNP会落入
和
的区域。随后,模型就到了第二阶段,对噪音鲁棒的对比损失进行优化,这个阶段中,大多数FNP会落在
或者是
,FNP的距离不会上升或者下降的太快,因此可以减轻甚至消除含噪音标签的影响。同时,它只对真正的负对产生微不足道的影响,因为到目前为止它们的大部分距离都大于
。
消融实验设计
提出的对噪音鲁棒的对比损失
正负样本对的比例
对齐比列的影响
两个阶段的交替时间
一句话总结
论文好句摘抄(个人向)
(1)However, both the vanilla Hungarian algorithm and PVC aim to achieve instance-level alignment which might be over-suffificient to multi-view clustering and classifification.
(2)Without loss of generality, we take v = 2 as a showcase















 722
722











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









