







集成学习
集成学习(ensemble learning)通过构建并结合多个学习器来完成学习任务,有时也被称为多分类器系统(multi-classifier svstem).一般结构:先产生一组“个体学习器”(individual learner),再用某种策略将它们结合起来.个体学习器通常由一个现有的学习算法从训练数据产生.例如决策树算法、BP神经网络算法等。
“同质”(homogeneous)集成:集成中只包含同种类型的个体学习器,例如“决策树集成”中全是决策树,“神经网络集成”中全是神经网络.同质集成中的个体学习器亦称“基学习器”,相应的学习算法称为“基学习算法”(base learning algorithm).
“异质”(heterogenous)集成:集成中包含不同类型的个体学习器,例如同时包含决策树和神经网络,个体学习器,常称为“组件学习器”.
学习器的选择:集成学习通过将多个学习器进行结合,常可获得比单一学习器显著优越的泛化性能.这对“弱学习器”尤为明显,因此集成学习的很多理论研究都是针对弱学习器进行的.但需注意的是,虽然从理论上来说使用弱学习器集成足以获得好的性能,但在实践中出于种种考虑,往往会使用比较强的学习器.
要获得好的集成,个体学习器应“好而不同”,即个体学习器要有一定的“准确性”,即学习器不能太坏,并且要有“多样性”.即学习器间具有差异.个体学习器的“准确性”和“多样性”本身就存在冲突.一般的,准确性很高之后,要增加多样性就需牺牲准确性.事实上,如何产生并结合“好而不同”的个体学习器,是集成学习研究的核心.
分类:根据个体学习器的生成方式,目前的集成学习方法大致可分为两大类,即
a)个体学习器间存在强依赖关系、必须串行生成的序列化方法,代表是Boosting
b)个体学习器间不存在强依赖关系、可同时生成的并行化方法;前者的,代表是Bagging 和Random Forest.
Boosting
Boosting中不同的分类器是通过串行训练而获得的,每个新分类器都根据已训练出的分类器的性能来进行训练。先从初始训练集训练出一个基学习器,再根据基学习器的表现对样本分布进行调整,使得先前的基学习器做错的训练样本在后续收到更多的关注,然后基于调整后的样本分布来训练下一个基学习器;如此重复进行,直至基学习器数目达到实现指定的值T,或整个集成结果达到退出条件,然后将这些学习器进行加权结合。
Boosting方法拥有多个版本,其中最流行的版本AdaBoost。
AdaBoost
Adaboost 算法采用调整样本权重的方式来对样本分布进行调整,即提高前一轮个体学习器错误分类的样本的权重,而降低那些正确分类的样本的权重,这样就能使得错误分类的样本可以受到更多的关注,从而在下一轮中可以正确分类,使得分类问题被一系列的弱分类器“分而治之”。
对于组合方式,为每一个分类器设定权重,采用加权多数表决的方法,具体地,加大分类误差率小的若分类器的权值,减小分类误差率大的若分类器的权值,从而调整他们在表决中的作用
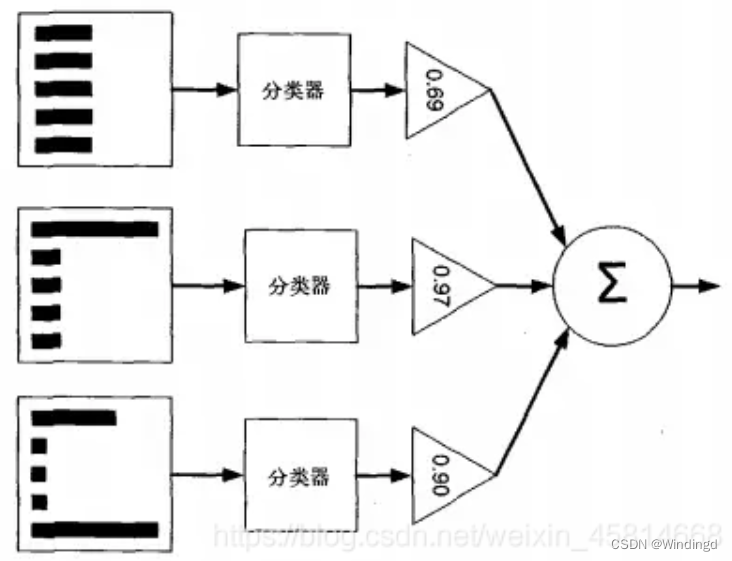
算法流程:
1)初始化训练数据的权值分布
D
1
=
(
ω
11
,
ω
12
,
…
,
ω
1
N
)
,
ω
1
i
=
1
N
D_1=(\omega_{11},\omega_{12},\dots,\omega_{1N}),\omega_{1i}=\frac{1}{N}
D1=(ω11,ω12,…,ω1N),ω1i=N1
2) 对每一轮的训练
m
=
1
,
…
,
M
m=1,\dots,M
m=1,…,M分类器:
a)使用具有权值分布
D
m
D_m
Dm的训练集得到基分类器
G
m
(
x
)
G_m(x)
Gm(x)
b)计算
G
m
(
x
)
G_m(x)
Gm(x)在该训练集上得问分类误差率,基于分类误差率得到权重系数
c)基于
G
m
(
x
)
G_m(x)
Gm(x)的分类结果更新训练集的权重为
D
m
+
1
D_{m+1}
Dm+1
3) 得到最终的分类器
G
(
X
)
=
s
i
g
n
(
∑
m
=
1
M
α
m
G
m
(
x
)
)
G(X)=sign(\mathop{\sum}\limits_{m=1}^M\alpha_mG_m(x))
G(X)=sign(m=1∑MαmGm(x))
Boosting Tree
提升树是以分类树或回归树为基本分类器的提升方法。提升树对不同问题有不同的提升树学习算法,其主要区别在于使用的损失函数不同。主要有用平方误差损失函数的回归问题,用指数损失函数的分类问题,以及一般损失函数的一般决策问题。对于二分类问题,提升树算法只需将AdaBoost算法的基本分类器限定为二分类决策树即可,此时的提升树算法是AdaBoost算法的特例情况。
Bagging与随机森林
Bagging
bagging 是一种个体学习器之间不存在强依赖关系、可同时生成的并行式集成学习方法 。
自助采样法(放回重采样法):即给定包含
m
m
m个样本的数据集,先随机从样本中取出一个样本放入采样集中,再把该样本返回初始数据集,使得下次采样时该样本仍可以被选中,这样,经过
m
m
m次随机采样操作,就可以得到包含
m
m
m个样本的采样集,初始数据集中有的样本多次出现,有的则未出现。
a)采样出T个含有m个训练集的采样集,
b)基于每个采样集训练出T个基学习器,
c)再将这些基学习器进行结合,即可得到集成学习器。
d)在对输出进行预测时,Bagging通常对分类进行简单投票法
优点:
a) 训练一个 Bagging集成与直接使用基分类器算法训练一个学习器的复杂度同阶,说明 Bagging是一个高效的集成学习算法。
b)与标准的AdaBoost算法只适用于二分类问题不同,Bagging能不经过修改用于多分类、回归等任务。
c) 由于每个基学习器只使用63.2%的数据,所以剩下36.8%的数据可以用来做验证集来对泛化性能进行“包外估计”。
随机森林
随机森林是bagging的扩展体。RF在以决策树为基学习器构建Bagging集成的基础上,进一步在决策树的训练过程中引入了随机属性选择。
结合策略
平均法
对于数值型的输出,
h
i
(
x
)
∈
R
h_i(x) \in R
hi(x)∈R,最常采用平均法。
简单平均:
H
(
x
)
=
1
T
∑
i
=
1
T
h
i
(
x
)
H(x)=\frac{1}{T}\mathop{\sum}\limits_{i=1}^Th_i(x)
H(x)=T1i=1∑Thi(x)
加权平均:
H
(
x
)
=
∑
i
=
1
T
ω
i
h
i
(
x
)
H(x)=\mathop{\sum}\limits_{i=1}^T\omega_ih_i(x)
H(x)=i=1∑Tωihi(x),
ω
i
≥
0
,
∑
i
=
1
T
ω
i
=
1
\omega_i \geq 0,\mathop{\sum}\limits_{i=1}^T \omega_i=1
ωi≥0,i=1∑Tωi=1
其中,当规模比较的的集成,加权平均容易导致过拟合,在个体学习器性能相差较大时宜使用加权平均法,而在个体学习器性能相近时宜使用简单平均法。
投票法
对于分类,常采用投票法:
绝对多数投票法(majority voting):即如某标记的投票过半数,则预计为该标记;否则拒绝预测
相对多数投票法(plurality voting):预测为得票最多的标记,若同时出现多个票数最多,则任选其一
加权投票法(weighted voting):
H
(
x
)
=
c
argmax
j
∑
i
=
1
T
ω
i
h
i
j
(
x
)
H(x)=c_{\mathop{\text{argmax}}\limits_j\sum_{i=1}^T\omega_ih_i^j(x)}
H(x)=cjargmax∑i=1Tωihij(x)
学习法
当数据很多时,一种更为强大的结合策略是使用“学习法”,即通过另一个学习器来结合。其中典型代表为Stacking
Stacking
在stacking中把个体学习器称为初级学习器,用于结合的学习器称为次学习器或者元学习器。
主要思想:先从初始数据集训练出初级学习器,然后“生成”一个新的数据集用于训练次级学习器 。生成的该新数据中,初级学习器的输出被当做样例输入特征,而初始样本的标记仍被当做样例标记,即
M
M
M个初级学习器,原始数据集中样本
(
x
;
y
)
(x;y)
(x;y),则新数据中的样本
{
h
1
(
x
)
,
h
2
(
x
)
,
…
,
h
M
(
x
)
,
y
}
\{h_1(x),h_2(x),\dots,h_M(x),y\}
{h1(x),h2(x),…,hM(x),y}

一般在使用Stacking时,采用交叉验证或留一法的方式,用训练初级学习器未使用的样本来产生次级学习器的训练样本
有研究表明,将初级学习器的输出类概率最为次级学习器的输入属性,用多响应线性回归(Multi-reponse Linear Regression,简称MLR)作为次级学习器算法效果更好,在MLR中使用不同的属性集更佳。















 1379
1379











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









