







1. 神经网络的基础机制
1.1 前向 forward 预测
1.1.1 加权和
神经网络只做一件事情:属性提取
属性向量:x: [0.8, 0.7, 0.1, 0.2, 1](1是固定的偏移)
权重向量:w: [0.5, 0.1, 0.2, 0.2, 0.3]
输入层------>隐含层:向量内积
每个隐含层节点对应不同的
w
w
w,权值存在在线上,隐含层节点对应加权和
输出层节点对应前面一层的加权和
输出层有 c=3 个结点,表示类别,谁的输出值大,就判断为哪类
1.1.2 激活函数
改变加权和后的值
改变线性,否则多层与一层等价
1.2 固定网络结构
隐含层 层数与每层节点数是人为设置
不同的数据由对应合适的网络结构
1.3 后向 backpropagation 调整权重
权值初始化为随机值
梯度下降:问责机制(出错误每条线都有责任,责任大小和权重有关,从后往前调整权重)
类别为 0, 输出的标准答案是 [1, 0, 0],但实际输出是 [0.3, 0.5, 0.6], 错误就是 [0.7, -0.5, -0.6]
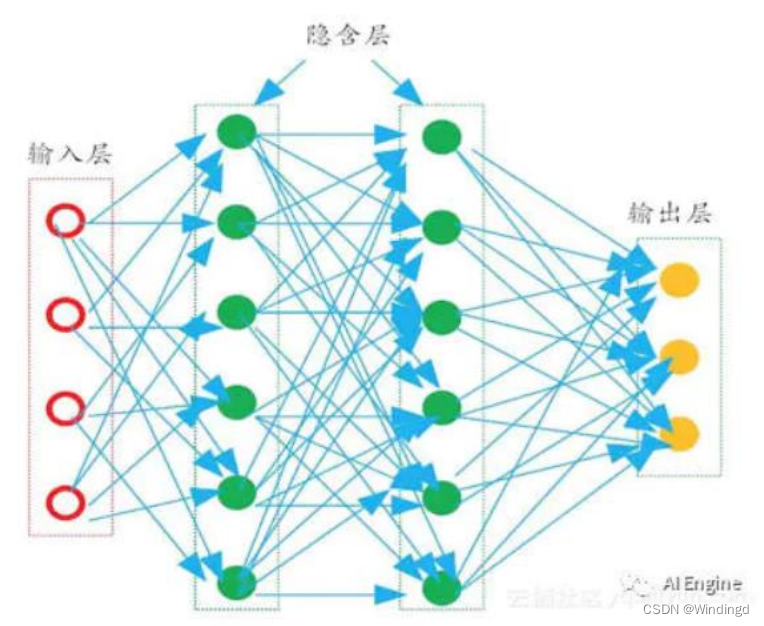
1.神经网络的基本思想
神经网络的主要工作是建立模型和确定权值,一般有前向型和反馈型两种网络结构。通常神经网络的学习和训练需要一组输入数据和输出数据对,选择网络模型和传递、训练函数后,神经网络计算得到输出结果,根据实际输出和期望输出之间的误差进行权值的修正,在网络进行判断的时候就只有输入数据而没有预期的输出结果。神经网络一个相当重要的能力是其网络能通过它的神经元权值和阈值的不断调整从环境中进行学习,直到网络的输出误差达到预期的结果,就认为网络训练结束。
每一层神经元仅仅与下一层的神经元全连接。而在同一层,神经元彼此不连接,而且跨层的神经元,彼此间也不相连。这种被简化的神经网络结构,被称之为“多层前馈神经网络。在多层前馈神经网络中,输入层神经元主要用于接收外加的输入信息,在隐含层和输出层中,都有内置的激活函数,可对输入信号进行加工处理,最终的结果,由输出层“呈现”出来。简单来说,神经网络的学习过程,就是通过根据训练数据,来调整神经元之间的连接权值(connection weight)以及每个功能神经元的输出阈值。
网络的理解
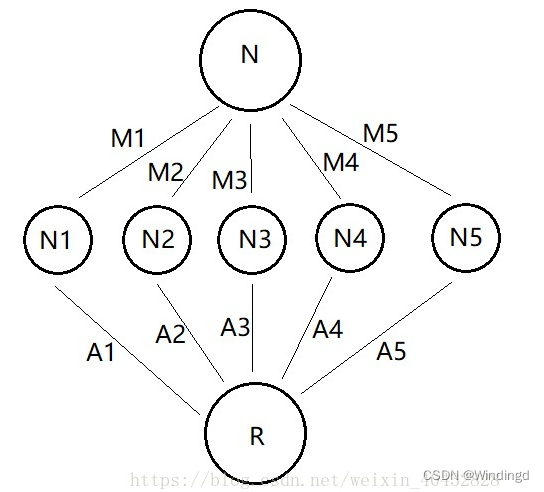
N 作为输入层(投资)
M1到M5则可以理解为输入层到隐藏层的权重(投资比例)
N1到N5则整体作为隐藏层(每个公司获得的资金)
A1到A5为隐藏层到输出层的权重(汇报率)
R作为输出层(收益)
所有的网络都可以理解为由这三层和各层之间的权重组成的网络,只是隐藏层的层数和节点数会多很多
输入层:实际的网络中可能有很多个输入节点
隐藏层:用于模拟一个计算的过程,上图中,隐藏层只有一层,节点数为 5 个。实际上可能有多层多个节点
输出层:结果,上图中,R 就是输出层的唯一一个节点,实际上可能有很多个输出节点。
权重:连接每层信息之间的参数,上图中通过乘积的方式来体现。
BP的原理
Bp 网络的运行流程就是根据已有的 x 与 y 来不停的迭代反推出参数 θ 的过程,这一过程结合了最小二乘法与梯度下降等特殊的计算技巧
正向传播
让信息从输入层进入网络,依次经过每一层的计算,得到最终输出层结果的过程
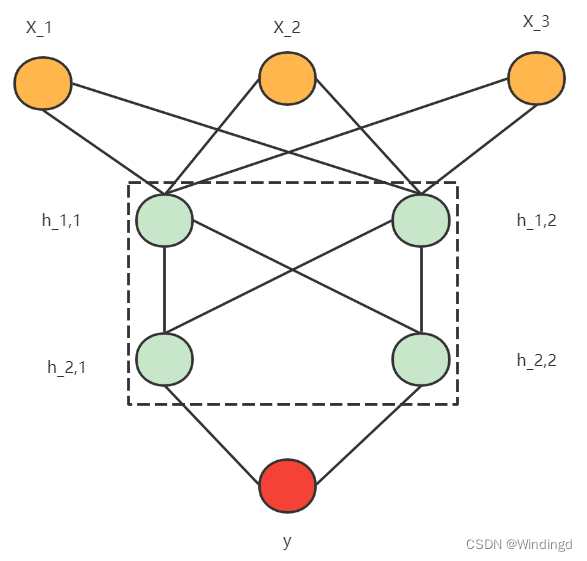
每条连线代表一个权重
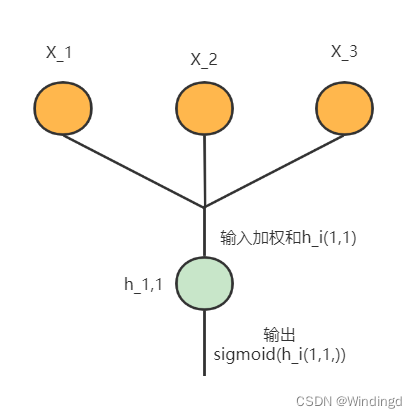
隐藏层中的节点可以看做有输入有输出的节点
输入为加权和;输出为激活函数处理后的值

激活函数
最早的网络是没有这个过程,统统使用线性的连接来搭建网络,但是线性函数没有上界,经常会造成一个节点处的数字变得很大很大,难以计算,也就无法得到一个可以用的网络。因此后来对节点上的数据进行了一个操作,利用sigmoid()函数来处理,使数据被限定在一定范围内。此外sigmoid函数的图像是一个非线性的曲线,因此,能够更好的逼近非线性的关系,因为绝大多数情况下,实际的关系是非线性的
常用对的激活函数有:sigmoid、Relu、tanh
反向传播
反向传播的信息是误差,也就是 输出层(output )的结果 与 输入信息 x 对应的真实结果 之间的差距
损失函数
损失loos:真实结果与计算结果的误差,记作损失函数,还有其他损失函数均方差损失、交叉熵损失等
l
o
o
s
=
∣
y
o
u
t
−
y
∣
loos=|y_{out}-y|
loos=∣yout−y∣
一个网络的计算结果
y
o
u
t
y_{out}
yout与 真是结果
y
y
y之间的损失总是很小,那么就可以说明这个网络非常的逼近真实的关系。所以不断地通过调整权重
u
,
w
,
v
u,w,v
u,w,v参数来使网络计算的结果$ y_{out}$ 尽可能的接近真实结果
y
y
y
过程理解为,根据 损失loss ,来反向计算出每个参数,再将原来的参数分别加上自己对应的梯度
u
=
u
+
α
⋅
d
u
w
=
w
+
α
⋅
d
w
v
=
v
+
α
⋅
d
v
u=u+\alpha \cdot du\\ w=w+\alpha \cdot dw\\ v=v+\alpha \cdot dv
u=u+α⋅duw=w+α⋅dwv=v+α⋅dv
学习率
α
是
一
个
小
于
1
的
实
数
,
它
的
大
小
会
影
响
网
络
学
习
的
速
率
以
及
准
确
度
\alpha是一个小于1的实数,它的大小会影响网络学习的速率以及准确度
α是一个小于1的实数,它的大小会影响网络学习的速率以及准确度
梯度下降法:调整
u
,
w
,
v
u,w,v
u,w,v使得损失函数不断变小
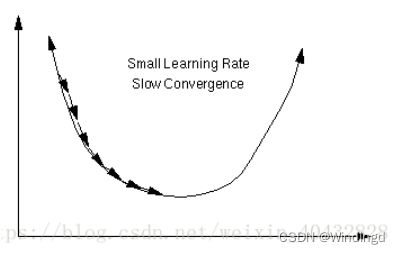
如图所示,损失函数存在最小值,通过求导的数值(梯度)不断的沿着梯度方向逼近最小值。
总结
神经网络越复杂,其计算过程也越繁琐,参数越多,越容易出现过拟合的情况(过拟合即网络过度学习了数据的特征,将噪声也同时考虑到了网络中,造成网络只在训练集上表现良好,而无法泛化到其他数据上),因此要根据数据的实际情况来设计网络的层数,节点数,激励函数类型 以及 学习率














 1311
1311











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









