







Pytorch优化器#1
机器学习中的五个步骤:数据 ——> 模型 ——> 损失函数 ——> 优化器 ——> 迭代训练
通过前向传播得到损失函数,模型再反向传播得到参数的梯度,接下来就是优化器根据这个梯度去更新参数,使得模型的损失不断降低。
1 优化器的概念
pytorch的优化器:管理并更新模型中可学习参数的值,使得模型输出更接近真实标签。
在更新参数时一般使用梯度下降的方式去更新。梯度是一个向量,方向是导数取得最大值的方向,也就是增长最快的方向,而梯度下降则是沿着梯度的负方向去变化,这样函数的下降也是最快的,所以采用梯度下降的方式来更新权值。
2 优化器的属性和方法
基本属性:
defaults:优化器超参数,存储学习率、momentum的值、衰减系数等;
state:参数的缓存,如momentum的缓存(使用前几次梯度进行平均)
param_groups:管理的参数组,这是个列表,每一个元素是一个字典,字典中key的值是真正的参数;
_step_count:记录更新的参数,学习率调整中使用,比如迭代100次之后更新学习率,这里记录100.
基本方法:
zero_grad():清空管理参数的梯度,pytorch中的参数的梯度在计算过程中是不自动清零的,所以需要这个方法将参数的梯度清零;
step:执行一步更新
add_param_group():添加参数组,优化器可以管理很多参数,可以对这些参数分组,对不同组的参数设置不同的超参数;
state_dict():获取优化器当前状态的字典;
load_state_dict():加载状态信息字典;
这两个方法用于模型断点的一个续训练,在模型训练时一般在设定epoch之后要保存当前的状态信息。
3 属性设置
学习率 (learning rate),控制模型的学习进度 ,即 stride (步长) 。作为监督学习以及深度学习中重要的超参,其决定着目标函数能否收敛到局部最小值以及何时收敛到最小值。合适的学习率能够使目标函数在合适的时间内收敛到局部最小值。

学习率设置
在训练过程中,一般根据训练轮数设置动态变化的学习率。
刚开始训练时:学习率以 0.01 ~ 0.001 为宜。
一定轮数过后:逐渐减缓。
接近训练结束:学习速率的衰减应该在100倍以上。
学习率减缓机制
轮数减缓(step decay):每N轮学习率减半
指数减缓(exponential decay):学习率按训练轮数增长指数插值递减
分数减缓(1/t decay):lrt=lr0/(1+kt) ,k 控制减缓幅度,t 为训练轮数
动量(Momentum):结合当前的梯度与上一次更新的信息,用于当前更新。加Momentum的梯度下降,其基本思想是计算梯度的指数加权平均,并利用该梯度更新权重。
普通的梯度下降:

Momentum梯度下降:
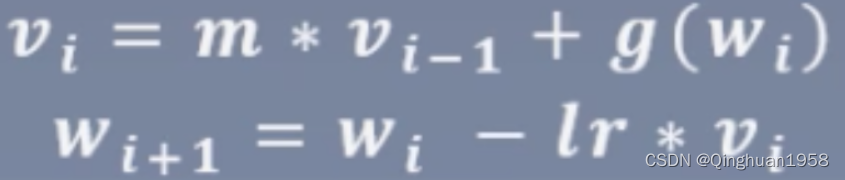
其中w i+1表示第i+1次更新的参数,lr学习率,vi更新量,m是momentum系数对应指数加权平均就是β,g (wi)是wi 的梯度。假设对第100次更新,根据上式公式推导如下:
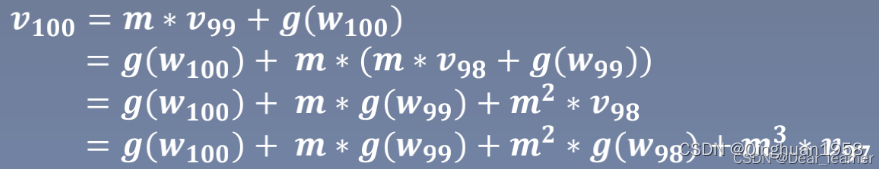
所以当前梯度的更新量会考虑到当前梯度, 上一时刻的梯度,前一时刻的梯度,这样一直往前,越往后的权重越小。
4 优化器
pytorch中的优化器可以大体分为两类:
基于SGD及其优化;
Per-parameter adaptive learning rate methods(逐参数自适应学习率方法),如AdaGrad、RMSProp、Adam等。
1、SGD(随机梯度下降)
梯度更新规则:
在SGD中,每次迭代只用一个训练数据
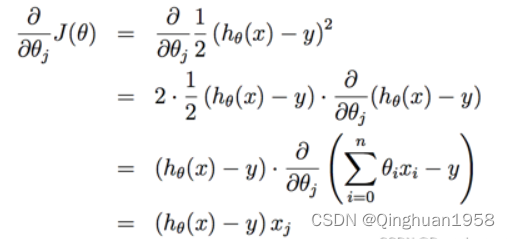
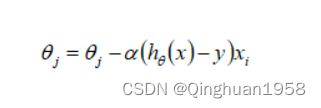
缺点:
1、如果样本中噪音比较多,使得SGD并不是每次迭代向着整体最优化的方向进行;
2、SGD因为更新比较频繁,会造成 cost function 有严重的震荡;
3、可能会收敛到局部最优,但由于震荡会跳过最优。
2、BGD(Batch Gradient Descent)
梯度更新规则:BGD采用整个训练集的数据来计算 cost function 对参数的梯度
假设线性模型:
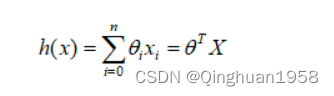
cost function:
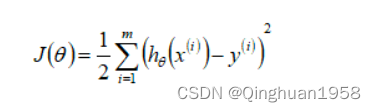
参数更新:
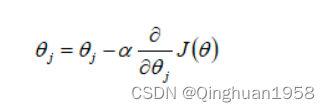
缺点:
由于在一次更新中,是对整个数据集计算梯度,所以训练速度慢,如果训练集很大,需要消耗大量的内存,且全量梯度下降不能进行在线模型参数更新。
3、MBGD(Mini-Batch Gradient Descent)
梯度更新规则:
MBGD 每次利用一小批样本,即n个样本进行计算,这样可以降低参数更新时的方差,收敛更稳定,另一方面可以利用矩阵操作来进行更有效的梯度计算。
参数更新方法为:
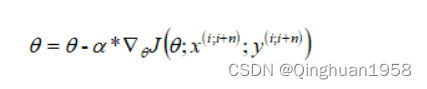
缺点:
1、MBGD 不能保证很好的收敛性,learning rate 如果选择太小,收敛速度慢,选择太大,会使得 cost function 在极小值附近震荡(一种解决措施是先设置大一点的learning rate,当达到某个阈值时,就减少learning rate,不过这个阈值要提前设定);
2、对所有的参数更新时应用同样的learning rate,如果数据是稀疏的,更希望对频率出现低的特征进行大一点的更新。
4、Adagrad(自适应梯度/Adaptive Gradient)
AdaGrad在训练过程中动态调整学习率,对不同参数根据累计梯度平方和更新不同学习率。
参数更新公式:

优点:每个变量都有适应自己的学习率
缺点:由于学习率的不断衰减在迭代过程早期衰减过快可能直接导致后期收敛动力不足,使得AdaGrad无法获得满意的结果。
5、RMSProp(Root Mean Square Propagation)
RMSProp通过指数加权移动平均(累计局部梯度信息)替代累计平方梯度和来优化AdaGrad,使得远离当前点的梯度贡献小。
迭代更新公式:

优点:在Adagrad基础上添加衰减因子,在学习率更新过程中权衡过去与当前的梯度信息,减轻了因梯度不断累计导致学习率大幅降低的影响,防止学习过早结束。
缺点:引入了超参数β,增加模型复杂性。同时依赖全局学习率η。
6、Adam(自适应矩阵/Adaptive Momentum Estimation)
Adam融合了RMSProp及Momentum的思想,做到了学习率自适应和动量加速收敛的效果。
参数更新公式为:

其中第三和第四项是s和m的偏差修正值,使得过去的梯度权值和为1,防止值过小。超参数一般设置为β=0.999, γ=0.9, ε=10^-8。
7、Adamax
Adam的改进版,对Adam增加了一个学习率上限的概念,是Adam的一种基于无穷范数的变种。
优点:对学习率的上限提供了一个更简单的范围
8、Nadam
Adam的改进版,类似于带有Nesterov动量项的Adam,Nadam对学习率有了更强的约束,同时对梯度的更新也有更直接的影响。一般而言,在想使用带动量的RMSprop,或者Adam的地方,大多可以使用Nadam取得更好的效果。
https://blog.csdn.net/Dear_learner/article/details/123219459?spm=1001.2014.3001.5502














 3279
3279











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









