







论文地址:VERY DEEP CONVOLUTIONAL NETWORKS FOR LARGE-SCALE IMAGE RECOGNITION
论文学习
1. 摘要
- 这篇论文探讨了在大规模图像识别任务中,卷积神经网络(ConvNets)深度对其准确性的影响。作者的主要贡献是对不断增加深度的网络进行了全面评估,这些网络使用了非常小的(3x3)卷积滤波器。研究发现,通过将网络深度增加到16到19层,可以显著提高性能,超越了之前的艺术水平配置。(通过卷积神经网络的加深可以显著提高性能)
- 这些发现是作者在2014年ImageNet挑战中提交作品的基础,他们的团队在定位和分类跟踪中分别获得了第一和第二名。此外,作者还展示了他们的表示(网络学到的特征)在其他数据集上也能很好地泛化,并取得了最先进的结果。为了促进深度视觉表示在计算机视觉领域的进一步研究,作者公开了他们表现最好的两个ConvNet模型。(验证通过卷积神经网络结构上的加深可以提高性能这个猜想)
2. 引言
- 卷积网络的成功应用
- 引言部分首先强调了卷积网络(ConvNets)在大规模图像和视频识别领域的成功应用。特别提到了一些关键的研究,如Krizhevsky等人在2012年的工作,这些研究标志着深度学习在视觉识别任务中的重要突破。
- 公共图像库和高性能计算系统的作用
- 论文提到了大型公共图像库(如ImageNet)和高性能计算系统(如GPU或大规模分布式集群)在推动深度视觉识别架构发展中的作用。
- ImageNet挑战赛的影响
- 引言中还讨论了ImageNet大规模视觉识别挑战(ILSVRC)对于几代大规模图像分类系统的影响,从高维浅层特征编码到深度卷积网络。
- 卷积网络架构的改进尝试
- 论文回顾了在Krizhevsky等人的原始架构基础上,为了提高准确性而进行的各种改进尝试,包括调整卷积层的接收窗口大小和步幅,以及在整个图像和多个尺度上密集训练和测试网络。
- 深度在卷积网络设计中的重要性
- 引言部分特别强调了深度在卷积网络架构设计中的重要性。论文的主要目标是通过增加更多的卷积层来探索深度的极限,并使用非常小的(3x3)卷积滤波器。
- 研究动机和目标
- 论文的动机是验证通过增加网络深度是否能显著提高图像识别的性能。目标是开发出能够在ILSVRC分类和定位任务上取得最先进性能的深度卷积网络架构。
3. ConvNet配置
- 统一的ConvNet架构设计
- 论文中所有的ConvNet配置都遵循了一套统一的设计原则。这些原则受到了之前研究的启发,特别是Ciresan等人(2011年)和Krizhevsky等人(2012年)的工作。
- 架构细节
- 训练时,ConvNets的输入是固定大小的224x224 RGB图像。唯一的预处理步骤是从每个像素中减去在训练集上计算得到的平均RGB值。
- 图像通过一系列卷积层进行处理,这些层使用非常小的3x3的感受野。在某些配置中,还使用了1x1的卷积滤波器,作为输入通道的线性变换。
- 卷积层之后是一系列最大池化层,但并不是每个卷积层后都跟有池化层。
- 网络的最后是三个全连接层,前两个各有4096个通道,第三个用于1000类ILSVRC分类,因此有1000个通道。
- 深度和宽度的平衡
- 论文中的网络深度从11层(网络A)到19层(网络E)不等。卷积层的宽度(通道数)从第一层的64开始,每经过一个最大池化层就翻倍,直到达到512。
- 网络配置的变体
- 论文详细描述了几种不同的网络配置(标记为A到E),每种配置都在通用设计的基础上增加了更多的层。
- 这些配置的主要区别在于网络的深度,即卷积层和全连接层的数量。
- 配置与先前工作的比较
- 作者讨论了他们的ConvNet配置与之前在ILSVRC-2012和ILSVRC-2013比赛中表现最佳的模型之间的区别。
- 与先前模型相比,本文的网络使用了更小的感受野,并在整个网络中保持了较小的步幅和较多的卷积层。
4. 分类框架
- 训练细节
- 训练过程基本遵循了Krizhevsky等人(2012年)的方法,但在从多尺度训练图像中采样输入裁剪方面有所不同。
- 使用小批量梯度下降法进行优化,批量大小设为256,动量为0.9。
- 采用L2权重衰减(权重衰减系数设为5e-4)和前两个全连接层的dropout(dropout比率为0.5)进行正则化。
- 初始学习率设为1e-2,当验证集准确率不再提高时,学习率减少10倍,总共减少3次,学习过程在大约370K次迭代(74个epoch)后停止。
- 网络初始化
- 网络权重的初始化非常重要,因为不良的初始化可能导致深度网络中梯度的不稳定。
- 作者首先训练了较浅的网络A,然后使用它来初始化更深网络的部分层。
- 对于随机初始化的层,权重从均值为0、方差为1e-2的正态分布中采样,偏置项初始化为0。
- 训练图像的尺寸和增强
- 训练图像首先被等比例缩放,然后从中随机裁剪出224x224的图像作为网络输入。
- 进行了图像水平翻转和随机RGB颜色偏移的数据增强。
- 多尺度训练
- 论文考虑了两种设置训练尺度S的方法:固定S和多尺度训练,后者通过从一定范围内随机采样S来模拟不同大小的对象。
5. 分类实验
- 实验数据集
- 实验主要在ImageNet Large Scale Visual Recognition Challenge (ILSVRC) 2012数据集上进行,该数据集包含1000个类别,超过120万张训练图像、5万张验证图像和15万张测试图像。
- 单尺度评估
- 对不同深度的ConvNet模型在单一尺度上进行评估。测试图像的尺寸被固定,与训练时相同。
实验结果显示,随着网络深度的增加,分类错误率显著下降。特别是,更深的网络(如配置D和E)比浅层网络有更好的性能。
- 对不同深度的ConvNet模型在单一尺度上进行评估。测试图像的尺寸被固定,与训练时相同。
- 多尺度评估
- 在测试时考虑了多个尺度,以提高性能。这包括在不同尺寸的图像上运行模型,并将结果进行平均。
- 使用多尺度评估可以进一步提高分类准确率。
- 多裁剪评估
- 除了全图评估外,还使用了多裁剪方法来提高准确率。这种方法包括在图像的不同位置进行裁剪,并对结果进行平均。
- ConvNet融合
- 通过结合多个不同配置的ConvNet模型的输出来提高性能。这种融合方法利用了不同模型的互补性。
- 与最先进技术的比较
- 将实验结果与当时的最先进技术进行了比较。论文中的深度ConvNet模型在分类任务上达到了新的最佳性能。
- 实验结论
- 实验结果强调了网络深度对于提高大规模图像分类性能的重要性。更深的网络能够学习到更丰富和更具判别性的特征表示。
6. 结论
- 深度对性能的显著影响
- 论文的结论部分首先强调了在大规模图像分类中,网络深度对提高性能的显著影响。通过实验验证,作者展示了更深的网络结构(最多19层权重层)能够显著提高分类准确率。
- 传统ConvNet架构的有效性
- 作者指出,尽管他们的网络架构非常深,但仍然基于传统的ConvNet架构。这表明,通过增加深度而不是改变基本架构,就能实现显著的性能提升。
- 泛化能力
- 结论中还提到,这些深度网络不仅在ImageNet挑战中表现出色,而且在其他数据集上也展现了良好的泛化能力。这表明深度网络学到的特征具有广泛的适用性。
- 对未来研究的启示
- 论文的结论强调了深度在视觉表示中的重要性,并对未来的研究提供了方向,即探索更深的网络架构以及它们在各种视觉识别任务中的应用。
- 公开模型的贡献
- 作者提到,他们已经公开了最优表现的两个模型,以促进深度视觉表示在计算机视觉领域的进一步研究。
这篇论文《VERY DEEP CONVOLUTIONAL NETWORKS FOR LARGE-SCALE IMAGE RECOGNITION》的创新点以及主要贡献如下:
创新点:深度网络架构
- 引入非常深的网络架构: 论文的主要创新之一是提出了非常深的卷积网络架构,最多达到19层权重层,这在当时是一个显著的进步,因为之前的网络通常深度较浅。
- 使用小型卷积滤波器: 论文中的网络使用了小尺寸(3x3)的卷积滤波器,这与当时常用的较大滤波器不同。这种设计允许在增加深度的同时控制参数数量,提高了网络的学习能力和效率。
主要贡献:性能提升和影响
- 显著提高图像分类性能: 通过实验,论文证明了更深的网络架构在ImageNet数据集上能够显著提高图像分类的准确率,这推动了深度学习在图像识别领域的发展。
- 网络泛化能力的验证: 论文还展示了这些深度网络在其他数据集上的良好泛化能力,表明深度学习模型学到的特征具有广泛的适用性。
- 推动深度学习研究: 论文的发表促进了深度学习在计算机视觉领域的研究,特别是在探索更深网络架构的可能性和有效性方面。
VGG
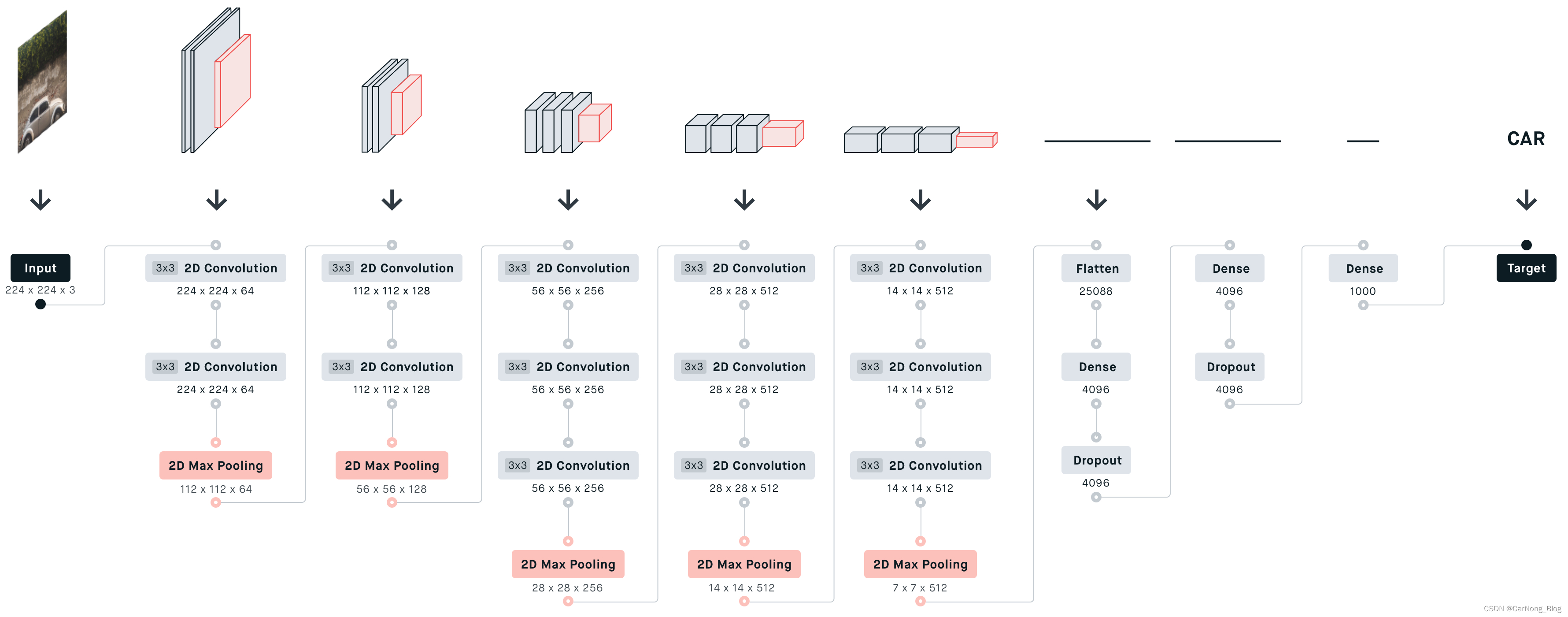
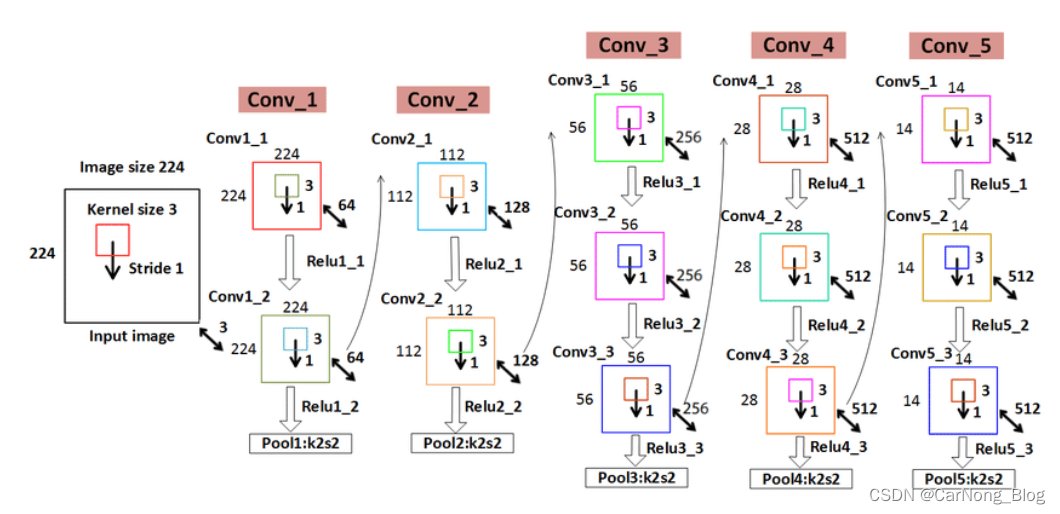
-
输入层:网络接收一个224 x 224 x 3的输入图像,这意味着图像宽度为224像素,高度为224像素,具有3个颜色通道(红色、绿色和蓝色)。
-
第一和第二个卷积块:输入图像首先经过两个3x3的卷积层,每个层的深度为64。每个卷积层后面都接一个ReLU激活函数。该块最后是一个2x2滤波器和步长为2的最大池化层,将尺寸减半到112 x 112 x 64。
-
第三和第四个卷积块:每个块由两个3x3的卷积层组成。第三个块的深度增加到128,第四块进一步增加到256。每个卷积层后面都接ReLU激活函数。每个块最后都有一个最大池化层,同样的规格,将尺寸缩小到56 x 56 x 128和28 x 28 x 256。
-
第五和第六个卷积块:这两个块各包含三个3x3的卷积层。第五块的深度保持为256,而第六块增加到512。如前所述,每个卷积层后面都接一个ReLU激活,每个块结束时有一个最大池化层,将尺寸进一步减小到14 x 14 x 512,然后是7 x 7 x 512。
-
全连接层:将最后一个池化层的输出扁平化后,网络过渡到三个全连接层。前两个全连接层各有4096个单元,应用了ReLU激活函数。此外,第一个全连接层后面接一个dropout层以防止过拟合。
-
输出层:最后一个全连接层有1000个单元,对应1000个类别,后面接一个softmax函数来得到类别的概率分布。
-
目标:网络产生一个分类输出,在提供的图片的上下文中,对应的类别为“汽车”。
代码实现
from typing import cast
import torch
from torch import nn
from torch.hub import load_state_dict_from_url
class VGG(nn.Module):
def __init__(
self,
features,
num_classes=1000,
init_weights=True,
dropout=0.5
):
"""
:param features: 特征提取层,也就是vgg块组成
:param num_classes: 输出类别数量 默认1000
:param init_weights: 是否参数初始化 默认是True
:param dropout: drop正则化概率 默认是0.5
"""
super().__init__()
self.features = features
self.avgpool = nn.AdaptiveAvgPool2d((7 * 7))
self.classifier = nn.Sequential(
nn.Linear(512 * 7 * 7, 4096),
nn.ReLU(True),
nn.Dropout(p=dropout),
nn.Linear(4096, 4096),
nn.ReLU(True),
nn.Dropout(p=dropout),
nn.Linear(4096, num_classes),
)
if init_weights:
for m in self.modules():
if isinstance(m, nn.Conv2d):
nn.init.kaiming_normal_(m.weight, mode="fan_out", nonlinearity="relu")
if m.bias is not None:
nn.init.constant_(m.bias, 0)
elif isinstance(m, nn.BatchNorm2d):
nn.init.constant_(m.weight, 1)
nn.init.constant_(m.bias, 0)
elif isinstance(m, nn.Linear):
nn.init.normal_(m.weight, 0, 0.01)
nn.init.constant_(m.bias, 0)
def forward(self,x ):
x = self.features(x)
x = self.avgpool(x)
x = torch.flatten(x, 1)
x = self.classifier(x)
return x
def make_layers(cfg, batch_norm=False):
layers = []
in_channels = 3
for v in cfg:
if v == 'M':
layers += [nn.MaxPool2d(kernel_size=2, stride=2)]
else:
v = cast(int, v)
conv2d = nn.Conv2d(in_channels=in_channels, out_channels= v, kernel_size=3, padding=1)
if batch_norm:
layers += [conv2d, nn.BatchNorm2d(num_features=v), nn.ReLU(inplace=True)]
else:
layers += [conv2d, nn.ReLU(inplace=True)]
in_channels = v
return nn.Sequential(*layers)
cfgs = {
"A": [64, "M", 128, "M", 256, 256, "M", 512, 512, "M", 512, 512, "M"],
"B": [64, 64, "M", 128, 128, "M", 256, 256, "M", 512, 512, "M", 512, 512, "M"],
"D": [64, 64, "M", 128, 128, "M", 256, 256, 256, "M", 512, 512, 512, "M", 512, 512, 512, "M"],
"E": [64, 64, "M", 128, 128, "M", 256, 256, 256, 256, "M", 512, 512, 512, 512, "M", 512, 512, 512, 512, "M"],
}
model_config = {
"VGG-11": {
"cfg" : "A",
"model_url" : {
"normal" : "https://download.pytorch.org/models/vgg11-8a719046.pth",
"bn" : "https://download.pytorch.org/models/vgg11_bn-6002323d.pth"
}
},
"VGG-13": {
"cfg" : "B",
"model_url" : {
"normal" : "https://download.pytorch.org/models/vgg13-19584684.pth",
"bn" : "https://download.pytorch.org/models/vgg13_bn-abd245e5.pth"
}
},
"VGG-16": {
"cfg" : "D",
"model_url" : {
"normal" : "https://download.pytorch.org/models/vgg16-397923af.pth",
"bn" : "https://download.pytorch.org/models/vgg16_bn-6c64b313.pth"
}
},
"VGG-19": {
"cfg" : "E",
"model_url" : {
"normal" : "https://download.pytorch.org/models/vgg19-dcbb9e9d.pth",
"bn" : "https://download.pytorch.org/models/vgg19_bn-c79401a0.pth"
}
},
}
def vgg(model_name, num_classes=1000, pretrained=True, batch_norm=True):
config = model_config[model_name]
model = VGG(features=make_layers(cfg=cfgs[config['cfg']], batch_norm=batch_norm))
if pretrained:
if batch_norm:
state_dict = load_state_dict_from_url(
url = config["model_url"]["bn"],
model_dir="./pretrained_model",
progress=True
)
else:
state_dict = load_state_dict_from_url(
url=config["model_url"]["normal"],
model_dir="./pretrained_model",
progress=True
)
model.load_state_dict(state_dict=state_dict, strict=False)
if num_classes != 1000:
model.classifier[-1] = nn.Linear(in_features=4096, out_features=num_classes)
return model
以上内容旨在记录自己的学习过程以及复习,如有错误,欢迎批评指正,谢谢阅读。

















 2485
2485

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









