






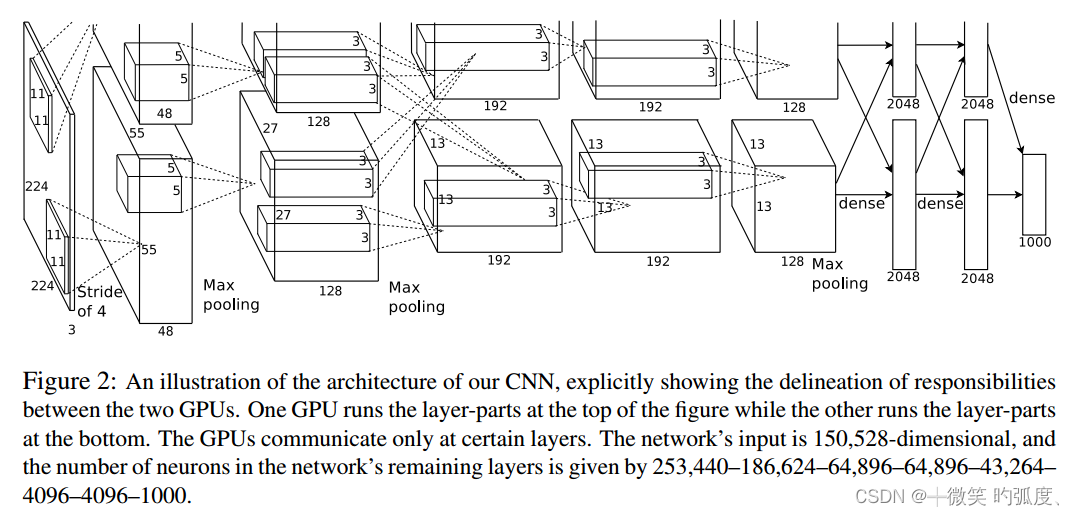
 该网络之所以上下两层是因为采用了两个GPU进行训练,上下层分别代表两个GPU的训练过程,使用两个GPU同时进行训练可以大大提高训练速度。为了容易理解,下面我们只看其中一层网络。
该网络之所以上下两层是因为采用了两个GPU进行训练,上下层分别代表两个GPU的训练过程,使用两个GPU同时进行训练可以大大提高训练速度。为了容易理解,下面我们只看其中一层网络。
Cov1
输入为224×224×3的图像,卷积核的数量为96,论文中两片GPU分别计算48个卷积核; 卷积核的大小为 11 × 11 × 3 ;stride = 4, stride表示的是步长, padding = [1,2], 表示;
卷积后的图形大小是怎样的呢?
wide = (224 + 2 * padding - kernel_size) / stride + 1 = 55
height = (224 + 2 * padding - kernel_size) / stride + 1 = 55
channel=48
Maxpool1
输入55×55×48的图像;kenel_size=3×3×48;stride=2
池化后的图形大小
wide = (55 + 2 * padding - kernel_size) / stride + 1 = (55+2×0-3)/2+1=27
height = (55 + 2 * padding - kernel_size) / stride + 1 = (55+2×0-3)/2+1=27
channel=128
以此类推出,最后一个全连接层输出的结果为1000个种类
**
注:输入图像通道数等于卷积核的通道数,输出图像的通道数等于卷积核的数量
2.AlexNet优势何在?
01卷积池化并行化
输入图像像素为224×224
把同一层的卷积池化拆成两块,每一块在一个GPU上跑
第一层用的11×11的大卷积对原始图做卷积,
第一层96通道分为两组,每48个放到一个GPU上面,每一个卷积核对上一层输入做卷积核是独立。
02激活函数
激活函数是relu,比饱和函数训练速度更快。
Relu函数公式:f(x)=max(0,x)
函数图像
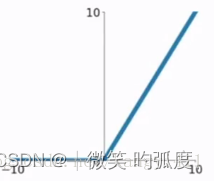
函数特点:自变量小于0时,函数值为0,自变量大于等于0时,函数值为自变量的值。
03防止过拟合
避免过拟合采用数据增强与dropout防止过拟合
04GPU加速
采用GPU实现,并行化进行模型训练。














 377
377











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









