







环境准备:
CentOs 7
VM ware
jdk1.8.0_231
安装包:
flink-1.10.1-bin-scala_2.11.tgz
kafka_2.11-0.11.0.2.tgz
zookeeper-3.4.5-cdh5.3.6.tar.gz
1. Flink Standalone Cluster安装
1)Flink下载地址
http://archive.apache.org/dist/flink/flink-1.10.1/
2)在虚拟机中进行解压安装
[root@zyh001 software]# tar -zxvf flink-1.10.1-bin-scala_2.12.tgz -C /zyh/
3)修改配置文件

[root@zyh001 conf]# vi flink-conf.yaml
[root@zyh001 conf]# vi masters
[root@zyh001 conf]# vi slaves



4)在bin目录下启动Flink
[root@zyh001 bin]# ./start-cluster.sh
5)查看启动节点,检查是否启动成功
[root@zyh001 bin]# jps
出现以上节点即启动成功

6)进入Flink的Web UI界面
输入网址:http://IP地址:8081/

7)测试Flink自带WordCount案例
[root@zyh001 flink-1.10.1]# cd examples/streaming/
[root@zyh001 bin]# vi input.txt
在bin目录下创建一个input.txt文件并输入单词
执行任务
[root@zyh001 bin]# ./flink run …/examples/streaming/WordCount.jar --input /zyh/flink-1.10.1/bin/input.txt --output /zyh/flink-1.10.1/bin/output.txt
查看结果:
[root@zyh001 bin]# cat output.txt




2. Zookeeper伪分布式安装
1)下载并解压安装zookeeper-3.4.5-cdh5.3.6
解压到指定目录
[root@zyh001 software]# tar -zxvf zookeeper-3.4.5-cdh5.3.6.tar.gz -C /zyh/
2)修改配置文件
①切换到zookeeper/conf目录下,复制模板配置文件
[root@zyh001 conf]# cp zoo_sample.cfg zoo1.cfg
②编辑zoo1.cfg配置文件
③复制zoo1.cfg配置文件并修改
[root@zyh001 conf]# cp zoo1.cfg zoo2.cfg
④复制zoo1.cfg配置文件并修改
[root@zyh001 conf]# cp zoo1.cfg zoo3.cfg



3)创建Zookeeper 保存数据的文件夹
在zookeeper目录下直接创建
[root@zyh001 zookeeper-3.4.5-cdh5.3.6]# mkdir-p tmp/zk1
[root@zyh001 zookeeper-3.4.5-cdh5.3.6]# mkdir-p tmp/zk2
[root@zyh001 zookeeper-3.4.5-cdh5.3.6]# mkdir-p tmp/zk3

4)创建节点标识
在zookeeper/tmp目录下
[root@zyh001 tmp]# echo 1 > zk1/myid
[root@zyh001 tmp]# echo 2 > zk1/myid
[root@zyh001 tmp]# echo 3 > zk1/myid
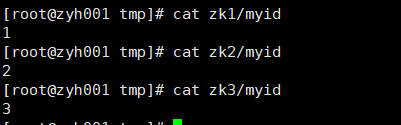
查看是否写入成功
[root@zyh001 tmp]# cat zk1/myid
[root@zyh001 tmp]# cat zk2/myid
[root@zyh001 tmp]# cat zk3/myid
5)启动zookeeper
启动
[root@zyh001 zookeeper-3.4.5-cdh5.3.6]# bin/zkServer.sh start conf/zoo1.cfg
[root@zyh001 zookeeper-3.4.5-cdh5.3.6]# bin/zkServer.sh start conf/zoo2.cfg
[root@zyh001 zookeeper-3.4.5-cdh5.3.6]# bin/zkServer.sh start conf/zoo3.cfg
(停止命令)
[root@zyh001 zookeeper-3.4.5-cdh5.3.6]# bin/zkServer.sh stop conf/zoo1.cfg
[root@zyh001 zookeeper-3.4.5-cdh5.3.6]# bin/zkServer.sh stop conf/zoo2.cfg
[root@zyh001 zookeeper-3.4.5-cdh5.3.6]# bin/zkServer.sh stop conf/zoo3.cfg
6)进行连接
连接其他zookeeper客户端
[root@zyh001 zookeeper-3.4.5-cdh5.3.6]# bin/zkCli.sh -server 172.16.31.118:2181
[root@zyh001 zookeeper-3.4.5-cdh5.3.6]# bin/zkCli.sh -server 172.16.31.118:2182
[root@zyh001 zookeeper-3.4.5-cdh5.3.6]# bin/zkCli.sh -server 172.16.31.118:2183
7)查看启动状态
[root@zyh001 zookeeper-3.4.5-cdh5.3.6]# bin/zkServer.sh status conf/zoo1.cfg
[root@zyh001 zookeeper-3.4.5-cdh5.3.6]# bin/zkServer.sh status conf/zoo2.cfg
[root@zyh001 zookeeper-3.4.5-cdh5.3.6]# bin/zkServer.sh status conf/zoo3.cfg

8)完成伪分布式搭建
3. Kafka单实例安装
kafka需要zookeeper集群
1)下载并解压安装kafka_2.11-0.11.0.2
[root@zyh001 software]# tar -zxvf kafka_2.11-0.11.0.2.tgz -C /zyh/
2)修改配置文件
在Kafka/config目录下
[root@zyh001 config]# vi server.properties
listeners=PLAINTEXT://hostname:9092
advertised.listeners=PLAINTEXT://hostname:9092

3)启动Kafka
启动Kafka前需要先启动zookeeper
debug方式启动kakfa:
[root@zyh001 kafka_2.11-0.11.0.2]# bin/kafka-server-start.sh config/server.properties
守护进程的方式启动kafka:
[root@zyh001 kafka_2.11-0.11.0.2]# bin/kafka-server-start.sh -daemon config/server.properties
查看端口
[root@zyh001 kafka_2.11-0.11.0.2]# netstat -tnlp | grep java
停止:
[root@zyh001 kafka_2.11-0.11.0.2]# bin/kafka-server-stop.sh
kafka会在zookeeper里保存集群信息
在开启的zookeeper窗口查看:
[zk: 172.16.31.118:2181(CONNECTED) 0] ls /



4.测试Flink从Kafka中读取数据
1)Idea依赖配置
<dependencies>
<dependency>
<groupId>org.apache.flink</groupId>
<artifactId>flink-scala_2.12</artifactId>
<version>1.10.1</version>
</dependency>
<!-- https://mvnrepository.com/artifact/org.apache.flink/flink-streaming-scala -->
<dependency>
<groupId>org.apache.flink</groupId>
<artifactId>flink-streaming-scala_2.12</artifactId>
<version>1.10.1</version>
</dependency>
<!-- 调用Kafka和zookeeper依赖-->
<dependency>
<groupId>org.apache.flink</groupId>
<artifactId>flink-connector-kafka-0.11_2.12</artifactId>
<version>1.10.1</version>
</dependency>
</dependencies>
<build>
<plugins>
<!-- 该插件用于将Scala代码编译成class文件 -->
<plugin>
<groupId>net.alchim31.maven</groupId>
<artifactId>scala-maven-plugin</artifactId>
<version>4.4.0</version>
<executions>
<execution>
<!-- 声明绑定到maven的compile阶段 -->
<goals>
<goal>compile</goal>
</goals>
</execution>
</executions>
</plugin>
<plugin>
<groupId>org.apache.maven.plugins</groupId>
<artifactId>maven-assembly-plugin</artifactId>
<version>3.3.0</version>
<configuration>
<descriptorRefs>
<descriptorRef>jar-with-dependencies</descriptorRef>
</descriptorRefs>
</configuration>
<executions>
<execution>
<id>make-assembly</id>
<phase>package</phase>
<goals>
<goal>single</goal>
</goals>
</execution>
</executions>
</plugin>
</plugins>
</build>
2)测试代码在这里插入代码片
import java.util.Properties
import org.apache.flink.api.common.serialization.SimpleStringSchema
import org.apache.flink.streaming.api.scala._
import org.apache.flink.streaming.connectors.kafka.FlinkKafkaConsumer011
object sourceTest {
def main(args: Array[String]): Unit = {
//创建执行环境
val env = StreamExecutionEnvironment.getExecutionEnvironment
//从kafka中读取数据
val properties = new Properties()
properties.setProperty("bootstrap.servers","IP地址:9092")
properties.setProperty("group.id","consumer-group")
properties.setProperty("key.deserializer",
"org.apache.kafka.common.serialization.StringDeserializer")
properties.setProperty("value.deserializer",
"org.apache.kafka.common.serialization.StringDeserializer")
properties.setProperty("auto.offset.reset","latest")
val stream3: DataStream[String] = env.addSource(new FlinkKafkaConsumer011[String]("sensor",
new SimpleStringSchema(), properties))
//进行扁平化,统计词汇
val result: DataStream[(String, Int)] = stream3.flatMap(_.split(" "))
.filter(_.nonEmpty)
.map((_, 1))
.keyBy(0) //分组
.sum(1)
result.print()
env.execute("source test")
}
3)启动Flink
[root@zyh001 bin]# ./start-cluster.sh
4)启动伪分布式Zookeeper
[root@zyh001 zookeeper-3.4.5-cdh5.3.6]# bin/zkServer.sh start conf/zoo1.cfg
[root@zyh001 zookeeper-3.4.5-cdh5.3.6]# bin/zkServer.sh start conf/zoo2.cfg
[root@zyh001 zookeeper-3.4.5-cdh5.3.6]# bin/zkServer.sh start conf/zoo3.cfg
5)启动单例模式Kafka
开启服务(daemon)
[root@zyh001 kafka_2.11-0.11.0.2]# bin/kafka-server-start.sh -daemon config/server.properties
做测试,创建生产者
[root@zyh001 kafka_2.11-0.11.0.2]# bin/kafka-console-producer.sh --broker-list zyh001:9092 --topic sensor
6)在idea中启动程序
7)在kafka中输入数据

8)idea中接收到数据















 267
267











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









