









 本文提出了一种名为FlexGen的框架,通过在有限GPU资源下聚合内存和计算,实现对大语言模型(LLM)的高吞吐量推理。通过解决线性规划问题,优化存储和访问策略,并使用4位压缩,FlexGen在单16GBGPU上实现了显著高于现有卸载系统的吞吐量,首次达到每秒1个标记的生成速度。
本文提出了一种名为FlexGen的框架,通过在有限GPU资源下聚合内存和计算,实现对大语言模型(LLM)的高吞吐量推理。通过解决线性规划问题,优化存储和访问策略,并使用4位压缩,FlexGen在单16GBGPU上实现了显著高于现有卸载系统的吞吐量,首次达到每秒1个标记的生成速度。
摘要
大型语言模型(LLM)推断所需的高计算和内存要求只有通过多个高端加速器才能实现。受到对批处理处理的延迟不敏感任务的新需求的推动,本文开始研究如何使用有限资源(如单个普通GPU)进行高吞吐量的LLM推断。**我们提出了FlexGen,一个用于在有限GPU内存上运行LLM的高吞吐量生成引擎。FlexGen可以通过聚合来自GPU、CPU和磁盘的内存和计算,在各种硬件资源约束下进行灵活配置。**通过解决线性规划问题,它搜索有效的存储和访问张量的模式。FlexGen还使用可忽略精度损失将权重和注意力缓存压缩为4位。这些技术使FlexGen具有更大的批处理大小选择空间,从而显著提高了最大吞吐量。结果是,在单个16GB GPU上运行OPT-175B时,与最先进的卸载系统相比,FlexGen的吞吐量显著更高,首次达到每秒1个标记的生成吞吐量,有效批处理大小为144。在HELM基准测试中,FlexGen可以在21小时内使用16GB GPU对30B模型在7个代表性子场景进行基准测试。代码可在https://github.com/FMInference/FlexGen上获得。
资源有限的情况下提高吞吐量,必然会 增加延迟。
介绍
大型语言模型(LLMs)可能具有数十亿甚至数万亿的参数,这导致运行所需的计算和内存要求极高。例如,仅加载GPT-175B模型权重就需要325GB的GPU内存。要将这个模型适配到GPU上,至少需要五个A100(80GB)GPU和复杂的并行策略。因此,降低LLM推理的资源需求近年来引起了极大的关注。
本文关注的是一种称为吞吐量导向的生成推理设置,它们通常需要对大量标记(例如,公司语料库中的所有文档)进行批处理的LLM推理,并且对延迟的敏感性较低。因此,在这些工作负载中可以通过将延迟与吞吐量进行权衡来降低资源需求。
降低LLM推断资源需求的先前努力可以分为三个方向:
- (1)模型压缩以减少总内存占用
- (2)通过去中心化分摊成本的协同推理
- (3)利用来自CPU和磁盘的内存进行卸载
前两个方向的研究通常假设模型适合GPU内存,并因此难以使用单个普通GPU运行175B规模的模型。另一方面,第三类基于卸载的最先进系统由于低效的I/O调度和张量放置而无法在单个GPU上实现可接受的吞吐量。例如,在某些情况下,这些系统可能受到小批处理大小的限制(例如,对于OPT-175B,批处理大小仅为一或两个)。
我们的重点是设计高吞吐量推理的高效卸载策略,在单个GPU上实现。为了在具有有限GPU内存的情况下运行LLM,我们可以将其卸载到辅助存储中,并通过部分加载的方式进行逐部分计算。在典型的计算机上,存在三个层次的存储层次结构。
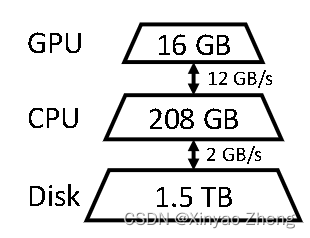
在吞吐量导向的场景中,我们可以通过使用较大的批处理大小来牺牲延迟,并且在大批量输入和计算中将昂贵的I/O操作分摊到不同的存储层次中。图1显示了三个推理系统在单个NVIDIA T4(16 GB)GPU上进行卸载的延迟和吞吐量之间的权衡。请注意,在资源有限的情况下,延迟和吞吐量方面的性能明显低于资源充足的情况。
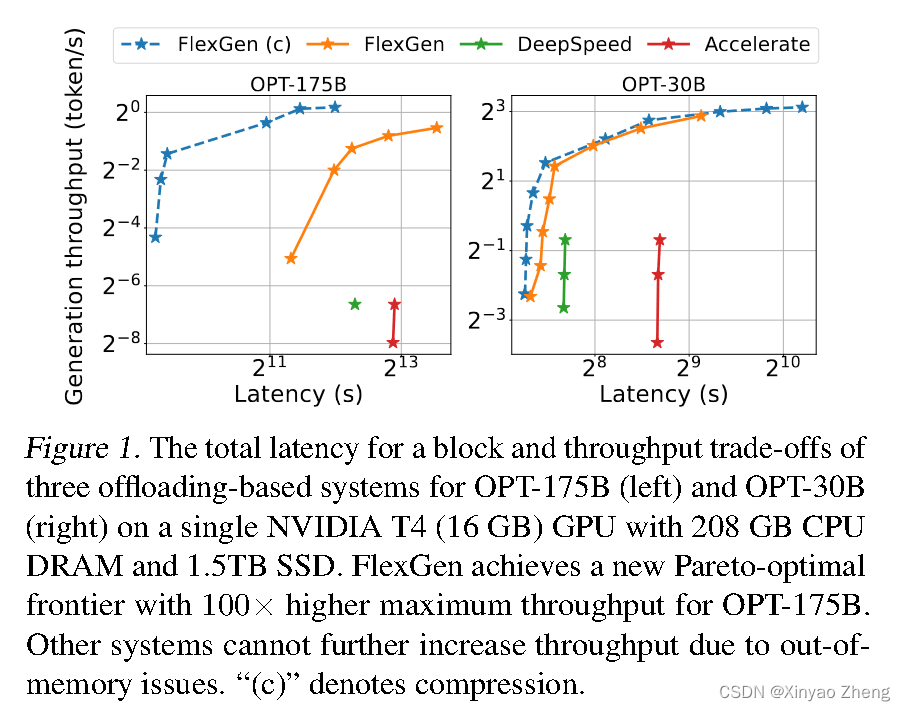
即使我们可以牺牲延迟,但实现具有有限GPU内存的高吞吐量生成推理仍然具有挑战性。
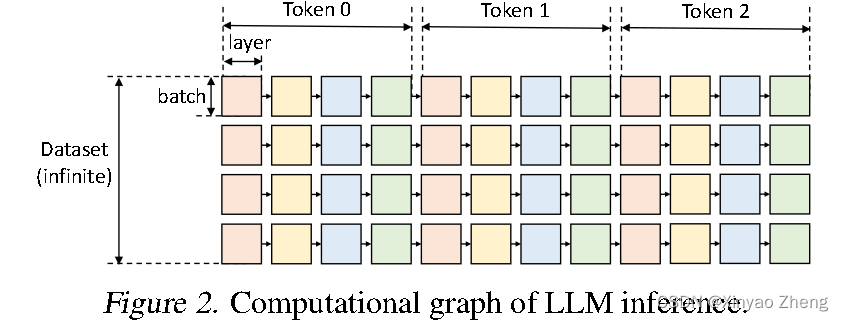
- 第一个挑战是设计高效的卸载策略。在生成推理过程中,存在三种类型的张量:权重、激活和键值(KV)缓存。该策略应指定要卸载的张量、在三级存储层次结构中的卸载位置以及在推理过程中何时进行卸载。批次、标记和层次的计算结构形成了一个复杂的依赖图,其中有多种进行计算的方式。这些选择共同形成了一个复杂的设计空间。现有的基于卸载的推理系统继承了训练中的策略,结果证明这些策略对于推理来说是一些次优点,执行过多的I/O操作并且吞吐量远低于理论硬件限制。
- 第二个挑战是开发有效的压缩策略。当将压缩与卸载结合用于高吞吐量推理时,权重和KV缓存的I/O成本和内存减少变得更加重要,从而推动了替代的压缩方案的发展。
为了解决这些挑战,我们提出了FlexGen,这是一个用于高吞吐量LLM推理的卸载框架。FlexGen汇集了来自GPU、CPU和磁盘的内存,并有效地调度I/O操作,同时考虑可能的压缩方法和分布式管道并行性。
- (贡献1)我们通过考虑计算调度、张量放置和计算委派,形式化定义了可能的卸载策略的搜索空间。我们开发了基于线性规划的搜索算法,在搜索空间内优化吞吐量。该算法可以根据不同的硬件规格进行配置,并且可以轻松扩展以满足延迟和吞吐量约束,从而帮助平滑地探索权衡空间。与现有策略相比,我们的解决方案统一了权重、激活和KV缓存的放置,使得批处理大小的上限大大增加,这是实现高吞吐量的关键。
- (贡献2)我们展示了将类似OPT-175B的LLM的权重和KV缓存压缩到4位的可能性,而无需重新训练或校准,并且准确度损失可以忽略不计。这是通过细粒度的分组量化实现的,适用于在卸载过程中减少I/O成本和内存使用。
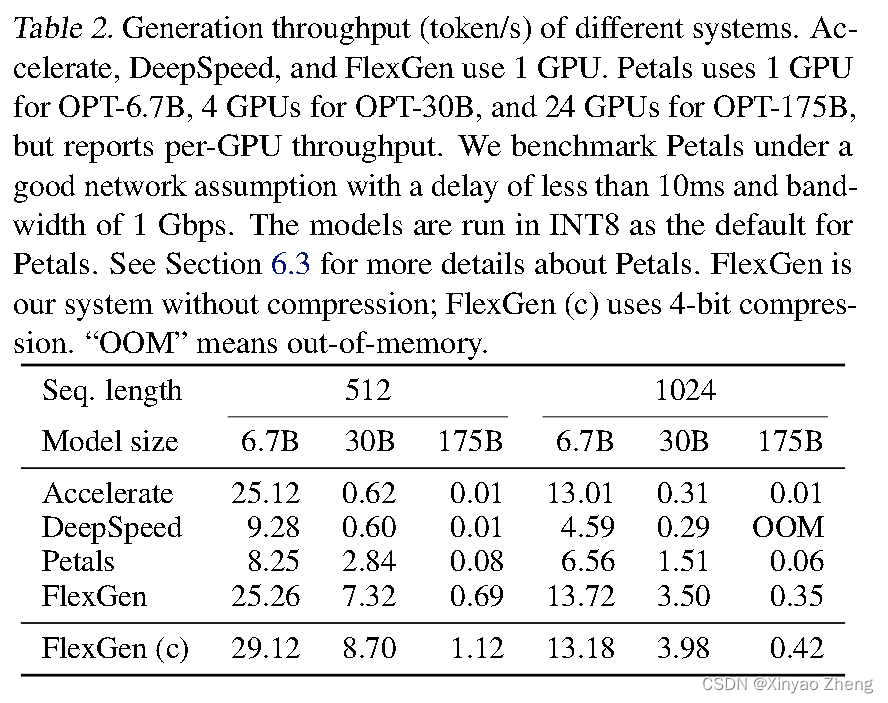
- (贡献3)我们通过在NVIDIA T4(16GB)GPU上运行OPT-175B来展示FlexGen的效率。与DeepSpeed Zero-Inference和Hugging Face Accelerate这两个最先进的基于卸载的推理系统相比,FlexGen通常允许更大数个数量级的批处理大小。因此,FlexGen可以实现更高的吞吐量。在单个T4 GPU上,配备208 GB的CPU DRAM和1.5 TB的SSD,输入序列长度为512,输出序列长度为32。
- 在相同的5000秒延迟下,FlexGen(有效批处理大小为64,总共2048个标记)的吞吐量比DeepSpeed Zero-Inference(批处理大小为1,总共32个标记)高出40倍以上,而Hugging Face Accelerate无法完成单个批处理。
- 通过允许较高的12000秒延迟,FlexGen相比基准系统的最大吞吐量提高了69倍,因为它可以将有效批处理大小增加到256(总共生成8192个标记),而DeepSpeed Zero-Inference和Hugging Face Accelerate由于内存不足问题无法使用超过2的批处理大小。
- 如果允许4位压缩,FlexGen可以在延迟为4000秒时通过将所有权重保留在CPU上并摆脱磁盘卸载,以有效批处理大小144(总共生成4608个标记)达到100倍的最大吞吐量。
2 相关工作
随着最近LLM的进展,LLM推理已成为重要的工作负载,激发了系统方面和算法方面的积极研究。近年来,出现了专门用于LLM推理的系统,例如FasterTransformer(NVIDIA,2022)、Orca(Yu等,2022)、LightSeq(Wang等,2021)、PaLM推理(Pope等,2022)、TurboTransformers(Fang等,2021)、DeepSpeed推理(Aminabadi等,2022)和Hugging Face Accelerate(HuggingFace,2022)。不幸的是,大多数这些系统都专注于面向低延迟的场景,使用高端加速器,限制了它们在易于访问的硬件上进行面向吞吐量的推理的部署。
为了在这种普通硬件上实现LLM推理,卸载是一种必不可少的技术。据我们所知,目前只有DeepSpeed Zero-Inference和Hugging Face Accelerate支持卸载。这些推理系统通常继承了训练系统的卸载技术,但忽略了生成式推理的特殊计算属性。它们无法充分利用面向吞吐量的LLM推理计算的结构,错过了高效调度I/O流量的巨大机会。
另一种实现在易于访问的硬件上进行LLM推理的尝试是Petals(Borzunov等,2022)提出的协作计算。还有许多算法导向的工作,通过放宽LLM推理中的某些计算方面来加速计算或减少内存占用。LLM推理已经采用了稀疏化和量化技术。在FlexGen中,我们将权重和KV缓存都压缩到4位,并展示了如何将压缩与卸载结合起来进行进一步改进。在更广泛的领域中,内存优化和卸载已经在训练和线性代数方面进行了研究。
3 背景:大模型推理
b表示批处理大小,用s表示输入序列长度,用n表示输出序列长度,用h1表示Transformer的隐藏维度,用h2表示第二个MLP层的隐藏维度,用l表示Transformer的总层数。
内存分析
LLM推理的内存占用主要来自模型权重和KV缓存。考虑使用FP16格式的OPT-175B模型,存储参数所需的总字节数可以粗略地计算为l(8h12+4h1h2)l(8h_1^2+4h_1h_2)l(8h12+4h1h2)。存储KV缓存所需的总字节数在峰值时为4blh1(s+n)4blh_1(s+n)4blh1(s+n)。
在实际设置中,使用足够数量的GPU,OPT-175B模型(l = 96,h1 = 12288,h2 = 49152)需要325 GB的内存。对于批处理大小b = 512,输入序列长度s = 512,输出序列长度n = 32,存储KV缓存所需的总内存为1.2 TB,这是模型权重的3.8倍,使得KV缓存成为大批量高吞吐推理的新瓶颈。FlexGen中,对于OPT-175B,我们将有效批处理大小扩大到256,以实现0.69个标记/秒的吞吐量。
吞吐量和延迟
考虑有效批处理大小b,输入序列长度s和输出序列长度n,延迟t定义为处理提示并生成所有bn个标记所花费的总秒数。生成吞吐量定义为bn/tbn/tbn/t。
6 评估

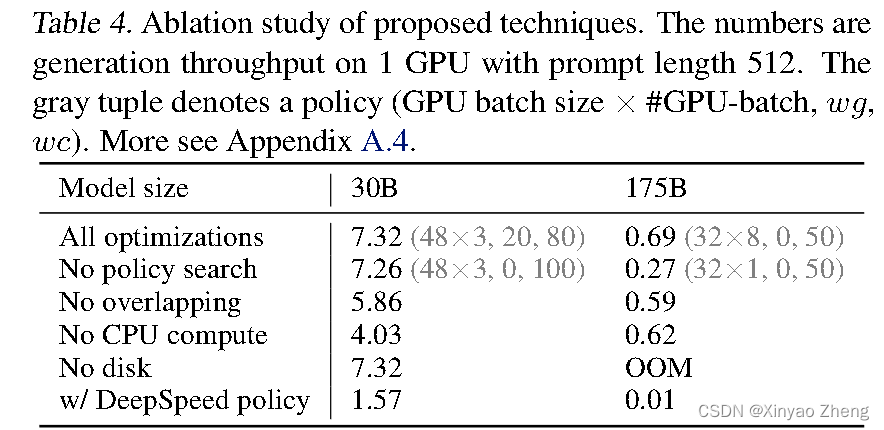
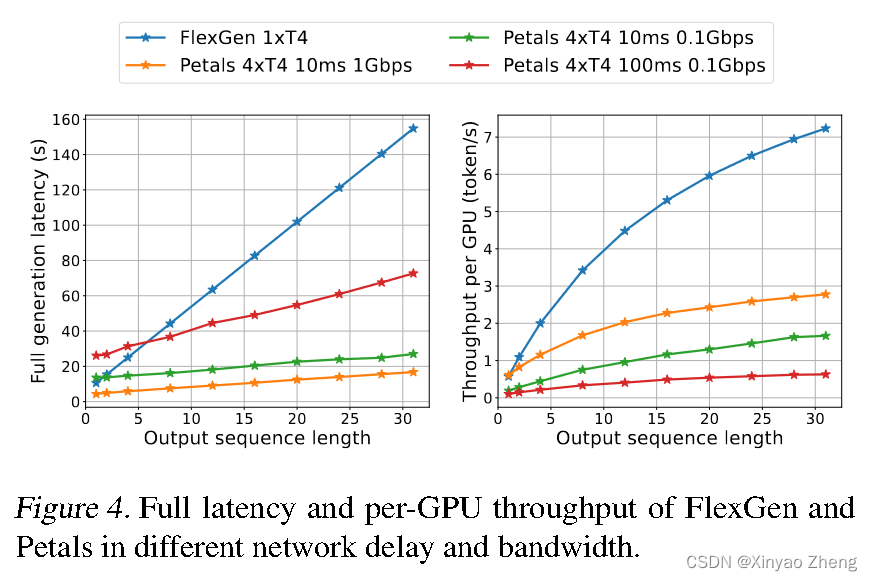

















 5167
5167

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









