









目录
收起
为什么要研究KV cache?
KV cache的作用
基于KV cache的加速策略
Window--窗口
Sparse--稀疏化
Quantization--量化
Allocator--显存分配
Share--KV cache共享
总结
参考资料
为什么要研究KV cache?
设输入序列的长度为 s ,输出序列的长度为 n ,模型深度为l,维度为h,以 FP16 来保存KV cache,那么KV cache的峰值显存占用大小为 b(s+n)h∗l∗2∗2=4blh(s+n) 。这里第一个2表示K/V cache,第二个2表示 FP16 占2个bytes。
以 GPT3 (175B) 为例,对比 KV cache 与模型参数占用显存的大小。GPT3 模型weight占用显存大小为350GB (FP16),层数 l为96,维度h为12888。
| batch size | s+n | KV cache(GB) | KV cache/weight |
| 4 | 4096 | 75.5 | 0.22 |
| 16 | 4096 | 302 | 0.86 |
| 64 | 4096 | 1208 | 3.45 |
参考上图,随着 batch size 和 长度的增大,KV cache 占用的显存开销快速增大,甚至会超过模型本身。从LLM的趋势上而讲,主要有三个方面来说明kv cache优化的必要性:
1、总体趋势上LLM 的窗口长度在不断增大,因此就出现一组主要矛盾,即:对不断增长的 LLM 的窗口长度的需要与有限的 GPU 显存之间的矛盾。因此优化 KV cache 非常必要。
OpenAI API场景,API最烧钱的是输入而非输出,输入包括prefill prompt 和conversation,长度动辄数十K token。虽说每输入token比每输出token便宜,但能够降低kv重新计算的开销,无论是硬件资源门槛,还是模型推理降本,都有着极为积极的作用。
2、对于消费级显卡这种性价比较高的显卡而言,显存容量相对较小,KV cache从一定程度上降低了模型的batch size,因而KV cache优化在工程落地中更显重要。
| 框架 | 模型 | input/output | 机器配置 | tokens/s | 最佳batch_size | gpu/cpu负载 |
| TGI | llama2 70B | 128/512 | 4090*8,32c | 291 | 13 | cpu25%,gpu95% |
| TGI | llama2 70B | 128/512 | A800,32c | 1122 | 43 | cpu25%,gpu95% |
从上表能够看出,类似4090等消费级显卡,其主要的瓶颈时batch_size,而影响batch_size的主要因素就是显存容量,而KV cache在推理过程中占用大量的显存。如果能通过KV cache降低显存占用,从一定程度上就能提升消费级显卡的性价比,带来非常高的商业收益。
3、sora/sd3等文生视频或者文生图的模型,纷纷放弃u-net架构,转而支持DIF(diffusion transformer)架构。对此类AIGC模型而言, KV cache同样能起到类似LLM上的加速效果。
根据资料,Sora类训练任务的特点是模型本体不大(10B以下),但是由于视频复杂性带来的序列长度特别长(接近1000kpatches的长度),可以对模型推理进行简易测算:
- 按照batch size = 1 进行测算,kv cache和模型权重对显卡占比能达到10:1(例如4090的24G显存,2G分给模型,22G分给kv cache)左右,这个场景的显存分配占比与LLM差异性还是非常的大。
- 按照batch size = 4 进行测算,kv cache和模型权重对显卡占比能达到40:1(batch size越大,kv cache的显存越大)
由此可见,KV cache会成为视频生成领域的一个重要瓶颈,但不排除有替代kv cache的加速方案。
KV cache的作用
解释kv cache之前,先看一组对话:
paki:What is the apples?
llama:Apples are a boring fruit.
假设上述对话中,paki是自然人并输入prompt(What is the apples?),llama是模型并返回result(Apples are a boring fruit)。如果对上述对话的模型推理流程进行分析,实际上需要将推理步骤分成两个阶段,即prefill和decode。
prefill阶段:输入为Q,即‘What is the apples?’,返回了第一个token,即‘Apples’,同时初始化了kv cache。
decode阶段:输入为单个词或者说q,通过自回归的方式,生成‘Apples are a boring fruit’这个句子。需要注意的是,decode计算的过程中,q的长度为1,即当前词,返回下一个词,例如通过‘Apples’生成‘are’,同时更新kv cache。
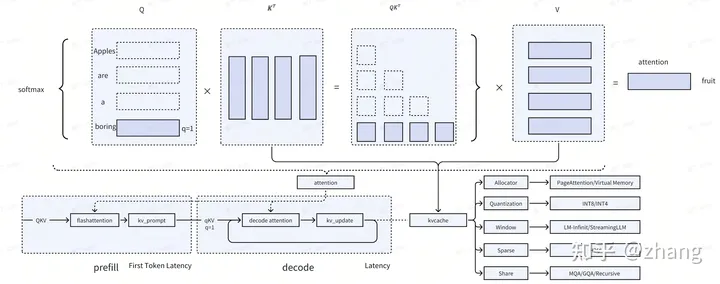
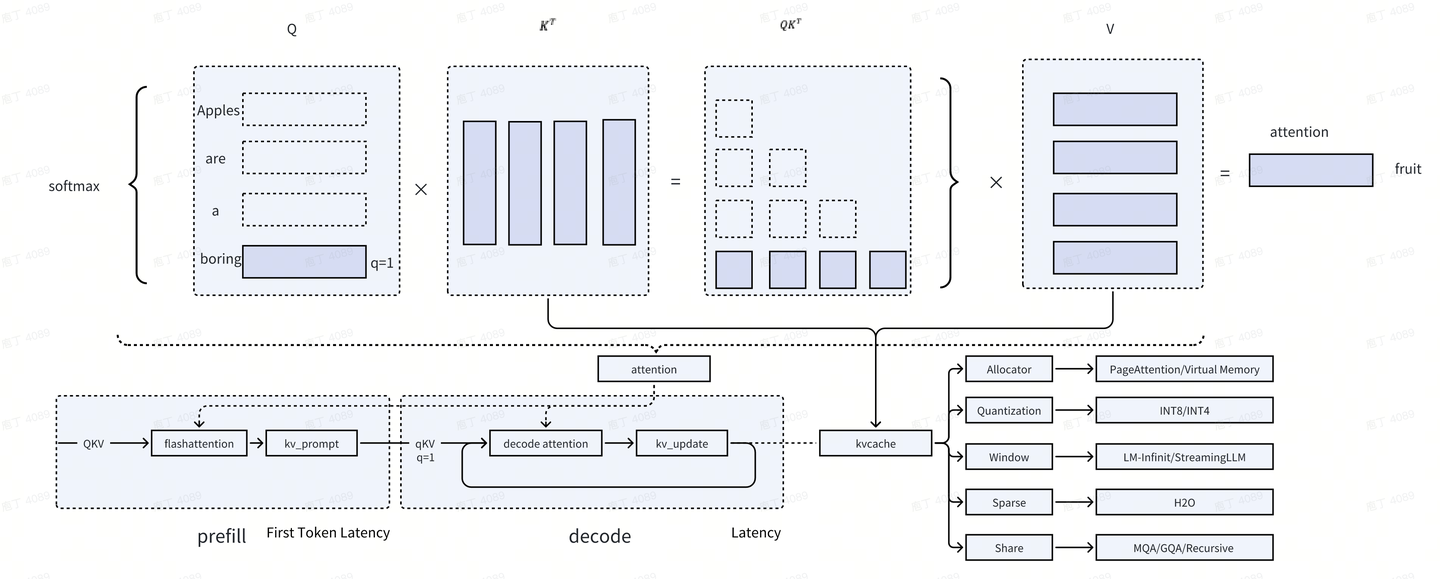
如上图所示,kv cache是attention计算中的全量kv 缓存,主要作用在decode阶段,目的是将输入Q优化成输入q。
我们举例说明,假设通过decode阶段通过自回归生成‘Apples are a boring fruit’这句话,当生成到‘fruit’这个词的时候,如果没有KV cache,输入为Q(‘Apples are a boring’),进行attention计算。反之,如果有了kv cache之后,输入只需要q(‘boring’这个词),即可完成attention计算。
为什么会这样,主要跟下一个token的生成给当前token的q和全量KV有关,具体attention的计算公式不再粘贴。
从这里也能看出,为什么 KV cache那么吃显存,其实主要因为随着seq长度变长和batch size增大,KV cache需要存储历史全量KV,从而跟着增大。
那就有这么一个思路,KV cacha本质上是attention计算中的一部分,如果对其进行压缩或者优化,是不是能起到推理的加速效果?
答案是肯定的,下面介绍一下主要的优化方法。
基于KV cache的加速策略
从整体上来讲,KV cache主要分成5个方向的优化,即Sparse、Quantization、Allocator、Window、share,我们逐个对5个方向的最新技术,做一些探讨。
Window--窗口
多轮对话场景的 LLMs 有两个难点:1. 解码阶段缓存 KV 需要耗费大量的内存;2. 流行的 LLMs 不能拓展到训练长度之外。
基于window方向的技术,解决上述问题主要有StreamingLLM[8]和LM-Infinite[14]两种方案,我们基于StreamingLLM进行介绍。
首先,自回归LLMs的一个有趣现象:无论它们与语言建模任务的相关性如何,初始tokens都被分配了惊人的大量注意力得分,并将tokens称为“attention sinks”,参考下图:
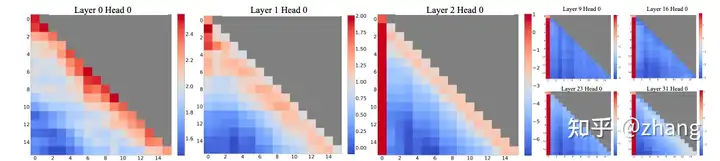
Visualization of the average attention logits in Llama-2-7B over 256 sentences, each with a length of 16.
根据attention sinks特性,我们参考之前多轮对话场景的解决方法,给出StreamingLLM的解决方案,即只保留attention sink tokens的KV(只需4个初始tokens)以及滑动窗口的KV,以锚定注意力计算并稳定模型性能的方法。
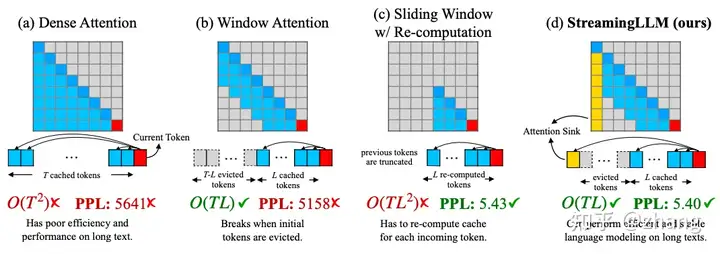
Illustration of StreamingLLM vs. existing methods. The language model, pre-trained on texts of length L, predicts the Tth token (T ≫ L).
上图的四个模块,分别对应下面的描述:
(a) 密集注意力(Dense Attention)具有 $$O(T^2$$ 的时间复杂度和不断增加的缓存大小。当文本长度超过预训练文本长度时,其性能会下降。
(b) 窗口注意力(Window Attention)缓存最近的 $$$$ 个tokens的$KV$。虽然在推理中效率高,但一旦开始tokens的键和值被删除,性能就会急剧下降。 这种方法相当于只在最近的tokens的KV状态上维护一个固定大小的滑动窗口,太过简单粗暴,没有实用价值。
(c) 带重计算的滑动窗口(Sliding Window with Re-computation)为每个新token重建来自 $L$个最近tokens的$KV$状态。虽然它在长文本上表现良好,但由于在上下文重计算中的二次注意力,其的$O(TL^2 ) $ 复杂度使其相当缓慢,使得这种方法不适用于实际的流式应用。
(d) StreamingLLM 保留了用于稳定注意力计算的attention sink(几个初始tokens),并结合了最近的tokens。它高效并且在扩展文本上提供稳定的性能。
粘贴一段StreamingLLM的代码,说明StreamingLLM的运行机制
def streaming_inference(model, tokenizer, prompts, kv_cache=None, max_gen_len=1000):
past_key_values = None
for idx, prompt in enumerate(prompts):
prompt = "USER: " + prompt + "\n\nASSISTANT: "
print("\n" + prompt, end="")
input_ids = tokenizer(prompt, return_tensors="pt").input_ids
input_ids = input_ids.to(model.device)
seq_len = input_ids.shape[1]
if kv_cache is not None:
space_needed = seq_len + max_gen_len
#通过每个prompt进行kv cache清理,并不是decode过程中进行kv cache清理。
past_key_values = kv_cache.evict_for_space(past_key_values, space_needed)
#通过prefill和decode进行模型推理
past_key_values = greedy_generate(
model, tokenizer, input_ids, past_key_values, max_gen_len=max_gen_len
)
通过上述代码逻辑,我们可以得到一个结论:StreamingLLM通过添加attention sinks和最近的tokens,可以将LLMs应用于远远超出预训练窗口大小的文本,甚至可能是无限长度的文本,但同时具有较强的场景局限性。
Sparse--稀疏化
通过对StreamingLLM的分析,其实可以发现基于window的方法,可以看作是一种相对粗糙的方法,那有没有更优的方法?答案就是Sparse,通过稀疏对KV cache压缩是一种相对模型性能更高的方法。
目前基于Sparse对kv cache压缩的方法在学术上有较多的进展,但在主流的推理框架上,例如TGI/vLLM等框架,尚未得到有效支持。主要介绍H2O、SubGen、LESS三个项目,来对KV cache稀疏化方案做个总体介绍。
H2O
简要介绍:基于attention的观察,即在计算attention分数时,一小部分token贡献了大部分价值。我们将这些token称为重击者(H2 )。通过全面的调查,我们发现H2的出现是自然的,并且与文本中标记的频繁共现密切相关,( ii )删除它们会导致性能显着下降。基于这些见解,我们提出了 Heavy Hitter Oracle (H 2 O),这是一种 KV 缓存驱逐策略(贪婪算法),可动态保持最近token和 H2 token的平衡。我们使用 OPT、LLaMA 和 GPT-NeoX 在各种任务中验证了算法的准确性。我们采用20%重量级的 H2O实施方案,在 OPT-6.7B 和 OPT- 上,与三个领先的推理系统 DeepSpeed Zero-Inference、Hugging Face Accelerate 和 FlexGen 相比,吞吐量提高了高达29 倍、 29 倍和3 倍。
H2O对比StreamingLLM而言,从一种的window方法演进成一种基于H2和最新token的驱逐策略,模型性能更加优秀,具体参考如下数据:
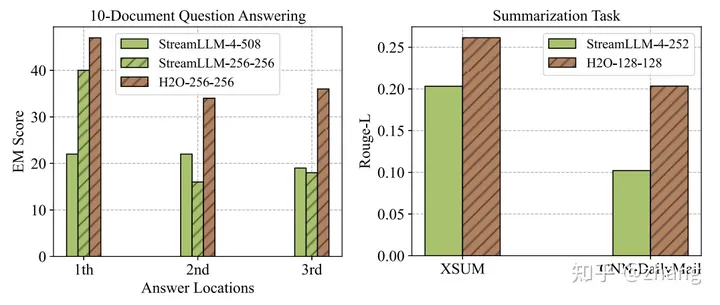
Comparison results of StreamLLM [52] and our H2O on generization tasks. The number in each method represents the KV Cache budget of the start/heavy-hitter tokens and the local tokens, respectively. For example, H2O-256-256 means maintaining 256 Heavy-Hitters and 256 local tokens.
通过H2O的KV cache逐出策略,能够实现20%缓存接近于全量KV cache的效果,这对KV cache的意义比较有意义,能极大的提升推理并发并同时降低延迟,参考下表:
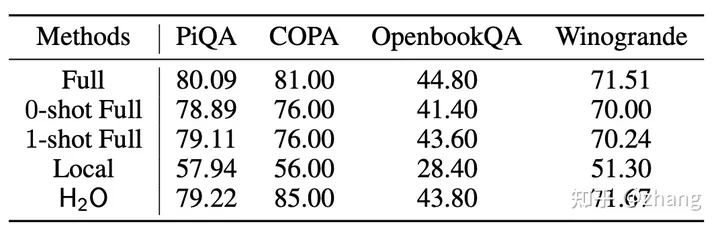
Quantatively comparison between H2O with Full methods of different number of shots
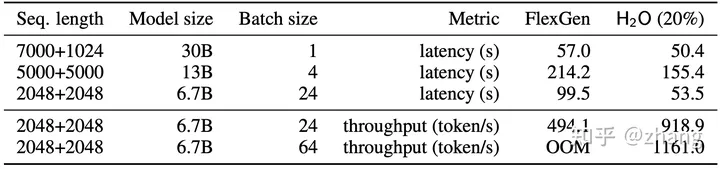
Generation throughput and latency on an A100 GPU. In the sequence length row, we use “7000 + 1024” to denote a prompt length of 7000 and a generation length of 1024. “OOM” means out-of-memory
综合来看,H2O是一种相对高效的KV cache压缩框架,值得进行深入研究。
SubGen
SubGen是一种为 KV cache开发的高效压缩技术。经验证据表明,attention模块中的关键嵌入存在显著的聚类趋势。基于这一关键见解,设计了一种具有亚线性复杂度的新颖缓存方法,对关键标记采用在线聚类并对值进行在线ℓ (2)采样。
如下图所示,使用 MT Bench 数据集从 Llama-2-7B收集key和value嵌入,同时模型生成 1024 个标记的序列。然后,使用 t-SNE [ 24 ] 跨各个层和头可视化嵌入,通过贪婪 k 中心算法 识别聚类中心点,根据观察结果表明,与所有随机选择的层和头的value嵌入相比,key嵌入(第一行)表现出更高程度的可聚类性。
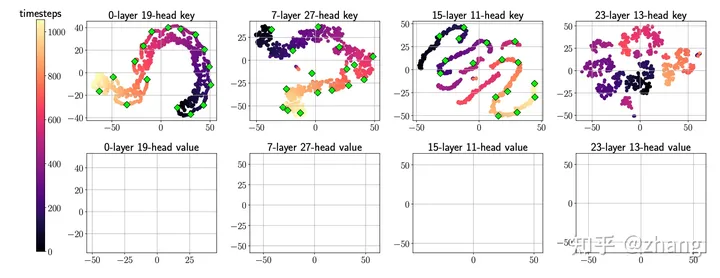
A t-SNE plot of cached keys (first row) and values (second row) embeddings over 1024 timesteps from Llama2-7B using MT Bench dataset
如下表所示,基于聚类的方法在所有序列长度上始终优于其他算法。例如,仅利用一半长度为 9k token 的缓存 KV 嵌入,就实现了 44% 的准确率,而 H2O 和 Sink 的准确率都低了 10%。这一发现表明,与注意力分数和位置信息相比,维护嵌入信息对于维持LLM的表现具有更大的意义。

Results on accuracy of line retrieval from LongEval [13] dataset with context length 5k-9k. Under the sublinear budgets on cache size, the proposed algorithm based on k-center algorithm outperforms other methods over all sequence lengths.
同时,根据SubGen的实验数据,可以观测到随着seq的长度变长,基于稀疏的Sink、H2O、SUBGEN等方法,都呈现出效果逐渐下降的趋势,这主要因为对于稀疏缓存策略,随着序列长度的增加,会保存一小部分 KV 对,因此会省略更多信息。
LESS
LESS(Low-rank Embedding Sidekick with Sparse policy)来学习原始注意力输出和稀疏策略近似的注意力输出之间的残差,通过将稀疏策略丢弃的信息累积到恒定大小的低等级缓存或状态中来实现此目的,从而允许查询仍然访问信息以恢复注意力图中先前省略的区域。
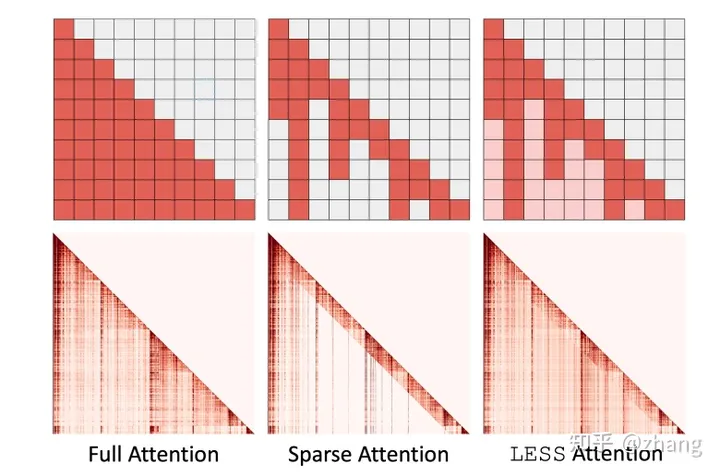
Toy (top row) and Llama 2 7B (bottom row) example decoder attention maps with H2O as the underlying sparse policy, Sparse attention policies zero out many positive attention probabilities. Our method, LESS, ensures all previous tokens will have some contribution to the attention
LESS这种方法所具有的优点:
- 性能改进:LESS 将稀疏 KV 策略与低秩状态综合起来,以弥补这些稀疏算法表现出弱点的各种任务的性能差距。事实上,LESS 比简单地将内存用于存储更多 KV 更能提高性能。
- 恒定的低等级缓存大小:LESS 中的低等级缓存占用相对于序列长度恒定的内存。
- 廉价的集成:对LLM架构的更改很小,并且不会扰乱原始权重。对 LLM 的唯一修改是在每个注意力层添加微小的多层感知(MLP)。例如,将 LESS 与 Llama 2 13B 结合使用,添加的参数总数不到 2%。
参考下图,Baseline+ (H2O参考)和 LESS (1% H (2 )O) 对于较短的序列似乎表现相似,但对于较长的序列则不同,LESS接近Full的水准。究其原因,低秩状态从一定程度上能解决部分重要attention被忽略的问题。
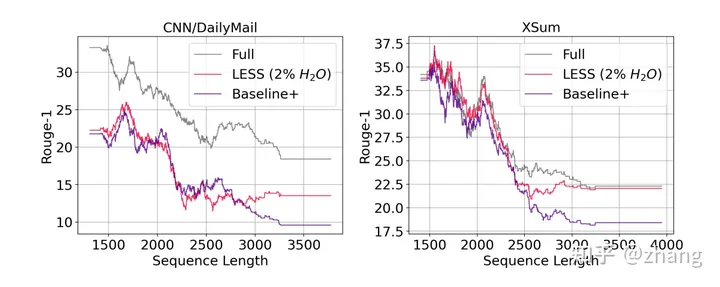
Relationship between Rouge-1 score and prompt length for Llama 2 7B with different cachemethods on CNN/DailyMail (left) and XSum (right).
Quantization--量化
当前主流推理框架都在逐步支持 KV cache 量化,例如exllama支持8位kv量化,LMDeploy支持到4位的kv量化。我们提一下刚出的WKVQuan,即一种低于4位的PTQ 框架。
WKVQuant,是一个专门为量化权重和 LLM 的键/值 (KV) 缓存而设计的 PTQ 框架。具体来说,我们结合了仅过去的量化来改进注意力的计算。此外,我们引入了二维量化策略来处理 KV 缓存的分布,以及用于参数优化的跨块重建正则化。实验表明WKVQuant实现了几乎与权重激活量化相当的内存节省,同时也接近仅权重量化的性能。
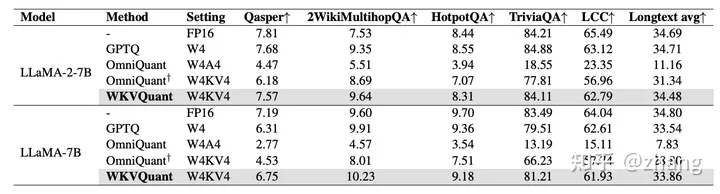
Longtext scores. Results of LLaMA-2-13B and LLaMA-13B can be found in A.5.
上图表明,WKVQuant的Weight-KV缓存方法具有卓越的量化准确性。
Allocator--显存分配
KV cache的内存分配策略,从一定程度上会影响模型推理的性能。
Page Attention 采用的是另外一种显存管理方式。允许生成过程中不断为用户追加显存。类似于操作系统中的页式存储或者内存分页。当一个请求来到之后,系统会为这个请求分配一小块显存,这一小块显存通常只够生成 8 个字符,当请求生成了 8 个字符之后,系统会追加一块显存,可以把结果再写到这块显存里面,同时系统会维护一个显存块和显存块之间的链表,从而使得算子可以正常地进行输出。当生成的长度不断变长时,会不断地给用户追加显存块的分配,并且可以动态维护显存块分配的列表,使系统不会存在大量浪费的资源,不需要为这个请求保留太多的显存空间。
除了Page Attention之外,PPL.LLM的Virtual Memory 和S3[7]均提出了一种预测器机制,即为每一个请求预测一个它所需的生成长度。每个请求进来之后,都会直接为其分配一个连续的空间,这个连续空间的长度是预测出来的。但理论上看可能难以实现,尤其到了线上推理阶段,不太可能清楚地知道每个请求究竟要生成多长的内容。因此我们推荐训练一个模型去做这件事情。因为即使我们采用了 Page Attention 这样的模式,依然会遇到问题。PageAttention 在运行的过程中,具体到一个特定的时间点,比如当前系统上已经有了四个请求,系统里面还剩余 6 块显存没有被分配。这时我们无法知道是否会有新的请求进来,能否为其继续提供服务,因为当前的四个请求还没有结束,可能未来还要继续为它们追加新的显存块。所以即使是 Page Attention 机制,还是需要预测每一个用户实际的生成长度。这样才知道在具体的一个时间点上能不能接受一个新的用户的输入。

Average batch size and number of iterations for different models
如上图所示,S3 生成类似的理想情况下的序列数量比 ORCA (一种高吞吐量的 Transformer 服务系统)多 1.13 倍至 6.49 倍。
Share--KV cache共享
MQA/GQA同属于基于attention变体的KV cache共享方法,相当于不同的注意力头或者同一组的注意力头共享一个K和V的集合,因为只单独保留了一份查询参数。因此K和V的矩阵仅有一份,这大幅度减少了显存占用,使其更高效。除了共享attention这种思路之外,还有其它的共享思路,我们当中重点说一下FlashInfer和Hydragen。
FlashInfer(Cascade Inference)提出Recursive Attention的方法,也就是采用multi-query attention计算共享部分的doc kv,采用single-query attention计算分开部分的kv1和kv2。简单来说,我们有三个子任务,分别计算Attn([q1, q2], doc kv),Attn(q1, kv1),和Attn(q2, kv2)。最后,采取类似于FlashDecoding的方式将中间结果进行合并。
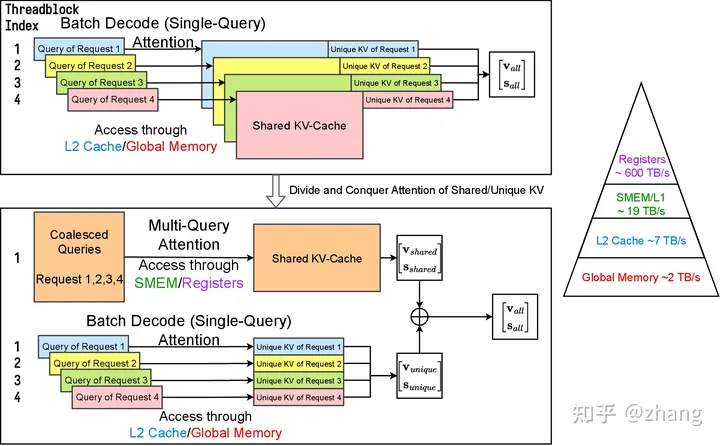
Workflow of Cascade Inference
Hydragen 分别计算对共享前缀和唯一后缀的注意力。这种分解通过跨序列批量查询来实现高效的前缀注意力,减少冗余内存读取并支持使用硬件友好的矩阵乘法。与竞争基线相比,我们的方法可以将端到端 LLM 吞吐量提高高达 32 倍,并且加速随着批量大小和共享前缀长度而增长。Hydragen 还支持使用非常长的共享上下文:在批量大小较高的情况下,将前缀长度从 1K 令牌增加到 16K 令牌会使 Hydragen 吞吐量降低不到 15%,而基线吞吐量则下降超过 90%。
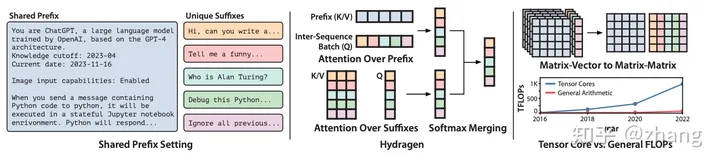
Hydragen workflow
Hydragen对应的结构描述:
- 左:LLM 推理场景示例,其中聊天机器人模型处理许多共享大共享前缀(系统提示)。
- 中:Hydragen 的概述,其中整体注意力被分解为共享前缀上的注意力(批量批次中的所有查询)并注意其余后缀(独立于序列,如通常所做的那样)。
- 右上:Hydragen 的注意力分解允许用更少的矩阵-矩阵乘积替换许多矩阵向量乘积。
- 右下:使用矩阵-矩阵乘积尤其重要,因为 GPU 将其总 FLOP 中越来越大的比例分配给张量核心专门用于矩阵乘法。
总结
KV cache对应的优化方法,总结成下表:
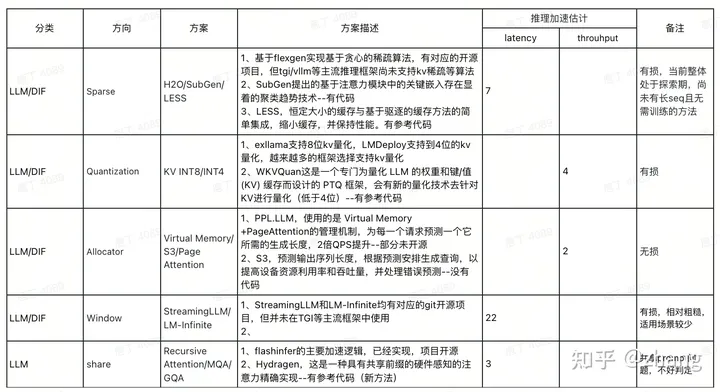
由上表可以看出,KV cache是个值得投入精力去研究的一个重要方向,算法上有着许多未知的方法可以去探索,工程上相对滞后,至少在主流推理框架上对部分方向的优化策略相对保守,这就给了足够多的机会。
参考资料
[1]LLM.int8(): 8-bit Matrix Multiplication for Transformers at Scale
[2]LLM-FP4: 4-Bit Floating-Point Quantized Transformers
[3]GPTQ: Accurate Post-Training Quantization for Generative Pre-trained Transformers
[4]https://k.sina.com.cn/article_2674405451_9f68304b019014oo6.html
[5]Fast Distributed Inference Serving for Large Language Models
[6]H2O: Heavy-Hitter Oracle for Efficient Generative Inference of Large Language Models
[7]S3: Increasing GPU Utilization during GenerativeInference for Higher Throughput
[8]EFFICIENT STREAMING LANGUAGE MODELS WITH ATTENTION SINKS
[9]https://flashinfer.ai/2024/02/02/cascade-inference.html
[10]Flash-Decoding for long-context inference
[11]https://github.com/openppl-public/ppl.llm.kernel.cuda/blame/master/src/ppl/kernel/llm/cuda/pmx/multi_head_cache_attention.cu
[12]FlashDecoding++: Faster Large Language Model Inference on GPUs
[13]FlashAttention-2: Faster Attention with Better Parallelism and Work Partitioning
[14]LM-Infinite: Simple On-the-Fly Length Generalization for Large Language Models
[15]WKVQuant: Quantizing Weight and Key/Value Cache for Large Language Models Gains More
[16]Get More with LESS: Synthesizing Recurrence with KV Cache Compression for Efficient LLM Inference
[17]SubGen: Token Generation in Sublinear Time and Memory
[18]Hydragen: High-Throughput LLM Inference with Shared Prefixes
[19]LoMA: Lossless Compressed Memory Attention
[20]CacheGen: Fast Context Loading for Language Model Applications
[21]Orca: A distributed serving system for Transformer-Based generative models
编辑于 2024-03-25 20:01・IP 属地日本

















 2万+
2万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









