







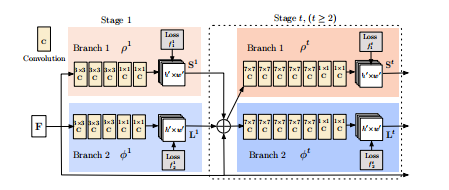
补:图3:两分支多细胞神经网络体系CNN结构,第一个分支的每个阶段预测置信图 st,第二个分支的每个阶段预测 pafs lt,两个分支的预测,连同图像特征,将连接为下一个阶段。如上述所说,本文采用two-branch multi-stage CNN作为最终CNN框架;如上图,上半部分为关联场预测网络,下半部分为关键点预测网络,并采用多级(stage)级联方法 ,每级之后,将图像和两个支流融合到一起供下一级使用在训练过程中,每级都会进行loss监督(中间监督)

2、图上展示了我们的方法的总体流程。该系统将大小为w×h的彩色图像作为输入(图2a),并将图像中每个人的二维解剖关键点位置作为输出(图2e)。首先,前馈网络同时预测一组二维人体部位置信度图S(图2b)和一组二维向量场L(图2c),后者对人体部位之间的关联度进行编码。集合S = (S1, S2,…其中,SJ∈Rw×h, J∈{1…J}。集合L = (L1,L2,…,LC)有C个向量场,每个limb1一个,其中LC∈Rw×h×2,C∈{1…C}, Lc中的每个图像位置编码一个二维向量(如图1所示),最后通过贪婪推理(图2D)解析置信图和亲和域,输出图像中所有人的二维关键点。
Method
2.1、Simultaneous Detection and Association
我们的架构,如图3所示,同时预测检测置信图和编码部分到部分关联的亲和域。 网络被分成两个部分: 顶部的分支,用米黄色显示,用来预测信任度(所谓置信度,也叫可靠度,它是指特定个体对待特定命题真实性相信的程度,也就是概率是对个人信念合理性的量度。置信水平是指总体参数值落在样本统计值某一区内的概率;而置信区间是指在某一置信水平下,样本统计值与总体参数值间误差范围。置信区间越大,置信水平越高。),底部的分支,用蓝色显示,用来预测亲和度。。每个分支都是一个迭代预测体系结构,遵循Wei等人[31]改进了连续阶段的预测,t∈{1…,T},每个阶段都有中间监督。
图像首先由卷积网络(由VGG-19的前10层初始化并微调)进行分析,生成一组输入到每个分支的第一级的特征映射F。在第一阶段,该网络产生一组检测置信映射S 1=ρ1(F)和一组部分部件关联场l1=φ1(F),其中ρ1和φ1是在第1阶段进行推断的CNNs。在随后的每个阶段中,将前一阶段中来自两个分支的预测与原始图像特征F连接起来,并用于生成精确的预测
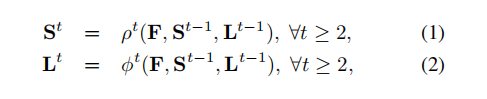

图4 右腕(第一排)和右前臂(第二排)跨级的置信度图。尽管早期左右身体部位和四肢之间存在混淆,但在后期通过全局推断,估计值会越来越精确,如突出显示的区域所示。
图4示出了跨阶段的置信映射和亲和域的细化。为了指导网络迭代预测第一分支和第二分支的身体部位的置信度图,我们在每个阶段的末尾分别应用两个损失函数,每个分支一个。我们在估计的预测和标定真值图和场之间使用L2损失。在这里,我们对损失函数进行空间加权,以解决一些数据集不能完全标记所有人的实际问题。具体来说,t阶段两个分支的损失函数为:


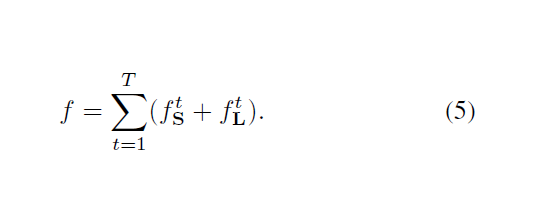
这里的Sj是groundtrth的置信图,Lc是垂直groundtrth的部分亲和域,W是二值mask,W§=0表示当前点P缺失用来避免在训练中惩罚真实的正面预测。 每个阶段的中间监视通过周期性地补充梯度来解决梯度消失的问题。 总体目标是公式(5)
















 3438
3438











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











