







1. 流分区 (非算子)
- 对于 Flink 而言,对于算子:
1. 可以先进行流分区,再使用算子;
2. 也可以直接使用算子(因为算子底层会根据该算子的并行度采取随机的方式进行流分区)
* 那么为什么还使用流分区?① 灵活进行流分区 ② 让人更加容易读懂代码- 每个算子都可以单独设置并行度,而并行度就是代表该算子的分区数,每个分区都会单独的调用该算子。
- 流分区并不是将一个流分成多个流,而是对流的分配-----数据流流进每个分区的数据量是多少?
- 流分区只是进行流分配,并不会改变元素
1.1 keyBy() 分区
- 作用:为每个元素打上标签,然后
① Flink底层会自动根据标签,将标签相同的分为一组
② Flink底层会自动根据标签的hash值,对下游算子的分区数 / 并行度 进行取模,知道将该元素放到哪一个分区中。因此:
- 这里的标签(key) 如果是 POJO 的话,必须要重写 hashCode()方法。
- 相同key的的数据一定会发送到同一个分区中,因为key相同其hash值一定相同;但是同一个分区中可能会有多个key的数据,这样主要是为了提高效率,但是一旦出现同一分区中存放不同组数据,就会进行“软分区”,将组数据隔开,因此并不会影响计算的正确性。
- 语法:
.keyBy(KeySelector接口的实现类对象) - 参数:通常采用匿名内部类的方式,例如
env .fromElements(1, 2, 3, 4, 5) // 过滤掉奇数元素 .keyBy(new KeySelector<Integer, String>() { @Override public String getKey(Integer value) throws Exception { return value % 2 == 0 ? "偶数" : "奇数"; } }) .print().setParallelism(2);注意:实现 KeySelector 接口时
- 接口后面的两个泛型,分别是 输入元素 和 标签 的类型
- 必须实现抽象方法
getKey(),并放回该元素的标签是什么
- 返回值类型:
KeyedStream
1.2 shuffle() 分区
-
作用:将每个元素随机的发往分区【发生数据倾斜时,可以使用】
-
语法:
.shuffle() -
参数:无
stream.shuffle().print("shuffle").setParallelism(4); -
返回值类型:
DataStream(最基本的数据流流类)
1.3 rebalance() 与 rescale() 分区
-
作用:轮询 / 平均 的将数据流元素分配到每个分区【0, 1, 2…0, 1, 2】
两者的区别:
.rebalance()轮询的时候可能跨TaskManager。而.rescale()不会,完全走的管道,不需要通过网络,所以效率更高。 -
语法:
.rebalance()或.rescale() -
参数:无
stream.rebalance().print("rebalance").setParallelism(4); -
返回值类型:
DataStream(最基本的数据流流类)
1.4 broadcast() 分区
-
作用:数据会在不同的分区都保留一份
-
语法:
.broadcast() -
参数:无
stream.rebalance().print("rebalance").setParallelism(4); -
返回值类型:
DataStream(最基本的数据流流类)
1.5 global() 分区
-
作用:将所有的输入流数据都发送到下游算子的第一个并行子任务中去。这就相当于强行让下游任务并行度变成了 1,所以使用这个操作需要非常谨慎,可能对程序造成很大的压力。
-
语法:
.global() -
参数:无
stream.global().print("rebalance").setParallelism(4); // 下游算子设置并行度会无意义 -
返回值类型:
DataStream(最基本的数据流流类)
1.6 自定义分区 (用到了再写)
2. 基本转换算子
2.1 map (一对一)
- 作用:对元素进行映射处理,不改变“形状”
- 语法:
.map(MapFunction接口的实现类对象) - 参数:通常采用匿名内部类的方式,例如
// 传入匿名类,实现 MapFunction stream.map(new MapFunction<Event, String>() { @Override public String map(Event e) throws Exception { return e.user; } });注意:实现 MapFunction 接口时
- 接口后面的两个泛型,分别是 输入元素 和 输出元素 的类型
- 必须实现抽象方法
map(),返回经过映射处理后的数据
- 返回值类型:
SingleOutputStreamOperator。他继承了最基本的数据流流类DataStream。
2.2 filter (一对一)
- 作用:过滤元素
- 语法:
.map(FilterFunction接口的实现类对象) - 参数:通常采用匿名内部类的方式,例如
env .fromElements(1, 2, 3, 4, 5) // 过滤掉奇数元素 .filter (new FilterFunction<Integer>() { @Override public boolean filter(Integer value) throws Exception { return value % == 0; } });注意:实现 FilterFunction接口时
- 接口后面的泛型,是 输入元素 的类型
- 必须实现抽象方法
filter()。返回true留下,返回false的被过滤掉
- 返回值类型:
SingleOutputStreamOperator。他继承了最基本的数据流流类DataStream。
2.3 flatMap (一对多)
- 作用:将每个元素都映射为同类型的多个元素(类似HSQL的explod()炸裂)
- 语法:
.map(FilterFunction接口的实现类对象) - 参数:通常采用匿名内部类的方式,例如
env .fromElements(1, 2, 3, 4, 5) // 过滤掉奇数元素 .flatMap(new FlatMapFunction<Integer, Integer>() { @Override public void flatMap(Integer value, Collector<Integer> out) throws Exception { out.collect(value); out.collect(value * value); } }); .print() // 输出:1, 1, 2, 4, 3, 9, 4, 16, 5, 25注意:实现 FlatMapFunction接口时
- 接口后面的两个泛型,分别是 输入元素 和 输出元素 的类型
- 必须实现抽象方法
flatMap(),并使用out.collect()进行元素收集,没有返回值
- 返回值类型:
SingleOutputStreamOperator。他继承了最基本的数据流流类DataStream。
3. 聚合算子
3.1 sum() 算子
-
作用:对指定的字段做叠加求和的操作
-
语法:
.sum(传参详细见下面) -
参数:

- 数据流的类型是 元组 ,则既能传入字段名,又能传入位置。(传入
"f0"、"f1"...或0, 1, ...)。例如:DataStreamSource<Tuple2<String, Integer>> stream = env.fromElements( Tuple2.of("a", 1), Tuple2.of("a", 3), Tuple2.of("b", 3), Tuple2.of("b", 4) ); // 根据元组的第二个字段求和 stream.keyBy(r -> r.f0).sum(1).print(); stream.keyBy(r -> r.f0).sum("f1").print(); - 数据流的类型是 POJO 类,则只能传入字段名,不能传入位置。例如
// Teacher类有字段:name、age、classid DataStreamSource<Teacher> stream = env.fromElements( new Teacher("Mary", 30, 1), new Teacher("Bob", 40, 2) ); // 求各个班级的老师年龄和 stream.keyBy(t -> t.classid).sum("age").print(); - 数据流的类型是 基本数据类型,则只能传入位置,因为没有字段名。例如
env .fromElements(1, 2, 3, 4, 5) // 分别求流中所有奇数之和和偶数之和 .keyBy(new KeySelector<Integer, String>() { @Override public String getKey(Integer value) throws Exception { return value % 2 == 0 ? "偶数" : "奇数"; } }) .sum(0) .print();
- 数据流的类型是 元组 ,则既能传入字段名,又能传入位置。(传入
-
返回值类型:
SingleOutputStreamOperator。
3.2 min() 算子 与 minBy() 算子
-
作用:都是对指定的字段求最小值。区别在于min()只计算指定字段的最小值,其他字段会保留最初第一个数据的值;而 minBy()则会返回包含字段最小值的整条数据。


-
语法:
.sum(和sum()算子一样) -
参数:
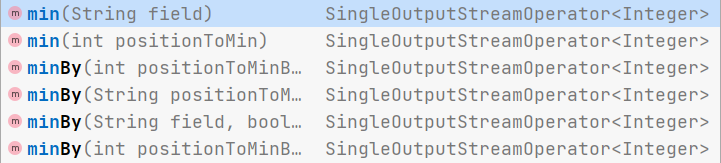
-
返回值类型:
SingleOutputStreamOperator。
3.3 max() 算子 与 maxBy() 算子
类比 min() 算子 与 minBy() 算子
3.4 reduce() 算子
-
作用:把每一个新输入的数据和当前已经归约出来的值,再做一个聚合计算。
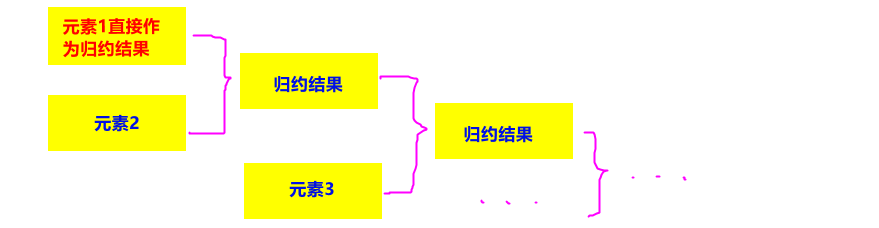
注意:
- 第一个元素不会进行规约,而是直接作为规约结果。
- 可以用该算子实现sum()算子的功能。
-
语法:
.reduce(ReduceFunction接口的实现类对象) -
参数:通常采用匿名内部类的方式,例如
.keyBy(r -> r.f0) // 使用用户名来进行分流 .reduce(new ReduceFunction<Tuple2<String, Long>>() { @Override public Tuple2<String, Long> reduce( Tuple2<String, Long> value1, // value1是前面已经规约后的结果 Tuple2<String, Long> value2) // value2是新元素 throws Exception { return Tuple2.of(value1.f0, value1.f1 + value2.f1); } })注意:实现 ReduceFunction 接口时
- 接口后面的泛型,是 输入元素 的类型
- 必须实现抽象方法
reduce(),返回与输入元素相同的数据类型,因为归约的是相同元素。
-
返回值类型:
SingleOutputStreamOperator。他继承了最基本的数据流流类DataStream。
4. 分流算子 (见后面博客)
split和select 分流算子 已被 高级部分 取代,见后面博客。
5. 合流算子
5.1 connect 算子
-
作用:把两个流合成一个流。
注意:
- 两个流元素类型可以不同。
- 只是机械的合并在一起, 内部仍然是分离的2个流。
- 如果多个流合并,则合并之后再合并
-
语法:
数据流1.connect (数据流2) -
参数:另外一个流
DataStreamSource<Integer> intStream = env.fromElements(1, 2, 3, 4, 5); DataStreamSource<String> stringStream = env.fromElements("a", "b", "c"); // 两个流合成一个流 ConnectedStreams<Integer, String> cs = intStream.connect(stringStream); // 使用合成后的流获取合成前的流 cs.getFirstInput().print("first"); cs.getSecondInput().print("second"); // 使用合成后的流实现需求 cs. // 第一个泛型是第一个流元素类型;第二个泛型是第二个流元素类型;第三个流是输出流元素类型 map(new CoMapFunction<Integer, String, String>() { @Override public String map1(Integer value) throws Exception { return value + "修改每个元素"; } @Override public String map2(String value) throws Exception { return value + "修改每个元素"; } }).print();注意:合流之后的流再使用算子,传入的参数是
Co...。比如这里的map(new CoMapFunction<Integer, String, String>() {...} -
返回值类型:
ConnectedStreams。他继承了最基本的数据流流类DataStream。
5.2 union 算子
-
作用:把两个或者两个以上的流合成一个流。
注意:
- 要求所有合并的流元素类型必须都相同。
- 只是真正合并在一起, 内部也是合并的。
-
语法:
数据流1.connect (数据流2, 数据流3, 数据流4...) -
参数:另外的所有流
DataStreamSource<Integer> stream1 = env.fromElements(1, 2, 3, 4, 5); DataStreamSource<Integer> stream2 = env.fromElements(10, 20, 30, 40, 50); DataStreamSource<Integer> stream3 = env.fromElements(100, 200, 300, 400, 500); // 把多个流union在一起成为一个流, 这些流中存储的数据类型必须一样: 水乳交融 stream1 .union(stream2) .union(stream3) .print(); -
返回值类型:最基本的数据流流类
DataStream。
— connect 与 union 算子区别
- connect 只能将两个流合并为一个流;而union可以合并多个流
- connect要求待合并的流可以不同;而union是必须相同。
6. 处理算子
6.1 process 算子
- 作用:能够获取上下文,是一个万能算子,很多算子都能用此算子实现。
- 语法:
.process (ProcessFunction接口的实现类对象 或者 KeyedProcessFunction接口的实现类对象)两者的区别在与:
- ProcessFunction接口的实现类对象:用于对流分区前使用
- KeyedProcessFunction接口的实现类对象:用于对流分区后使用
- 参数:通常采用匿名内部类的方式,例如
// 传入匿名类,实现 processElement stream.process(new ProcessFunction<WaterSensor, Tuple2<String, Integer>>() { @Override public void processElement(WaterSensor value, // 待处理的元素 Context ctx, // 上下文 Collector<Tuple2<String, Integer>> out // 输出收集器 ) throws Exception { out.collect(new Tuple2<>(value.getId(), value.getVc())); } });注意:实现 ProcessFunction 接口时
- 接口后面的两个泛型,分别是 输入元素 和 输出元素 的类型
- 都必须实现抽象方法
processElement(),返回处理后的数据
// 传入匿名类,实现 processElement env .fromCollection(waterSensors) .keyBy(WaterSensor::getId) .process(new KeyedProcessFunction<String, WaterSensor, Tuple2<String, Integer>>() { @Override public void processElement(WaterSensor value, Context ctx, Collector<Tuple2<String, Integer>> out) throws Exception { out.collect(new Tuple2<>("key是:" + ctx.getCurrentKey(), value.getVc())); } }) .print();注意:实现 KeyedProcessFunction 接口时
- 接口后面的3个泛型,第一个是标签的类型,第二个是 输入元素 的类型,第三个是 输出元素 的类型
- 都必须实现抽象方法
processElement(),返回处理后的数据
- 返回值类型:
SingleOutputStreamOperator。他继承了最基本的数据流流类DataStream。 - 重点:无论传入这两个接口谁的实现类,其执行的是否正确与该算子的并行度 / 分区数 息息相关。
- 比如:ProcessFunction接口的实现类对象
- 问题:
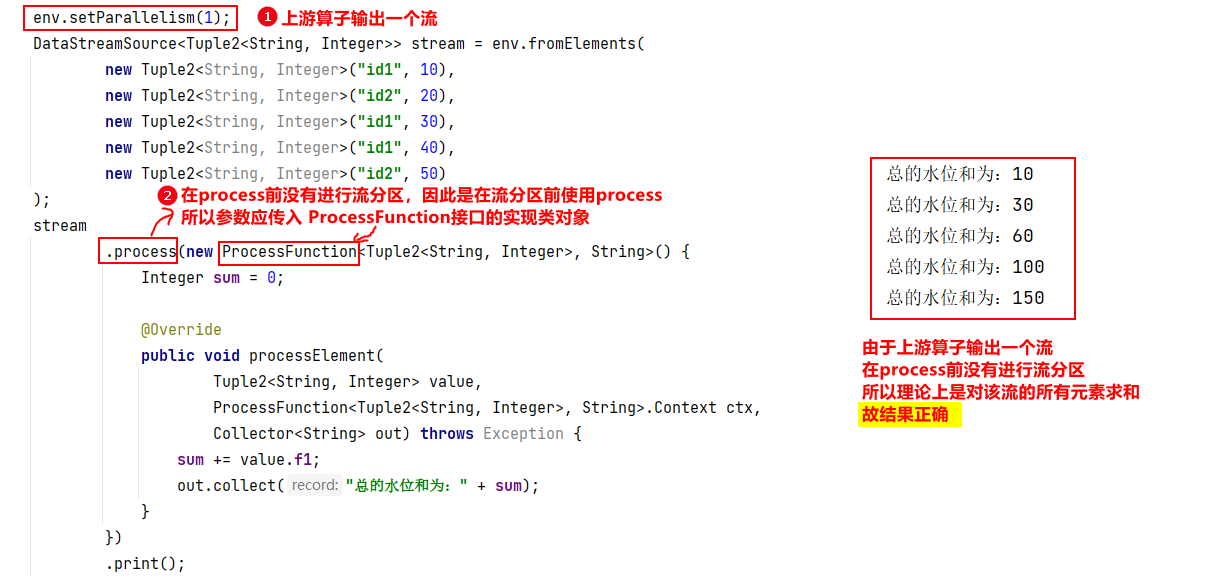

- 解决方法:保证算子的并行度和上游算子的输出流个数相同。
- 问题:
- 比如:KeyedProcessFunction接口的实现类对象
- 问题
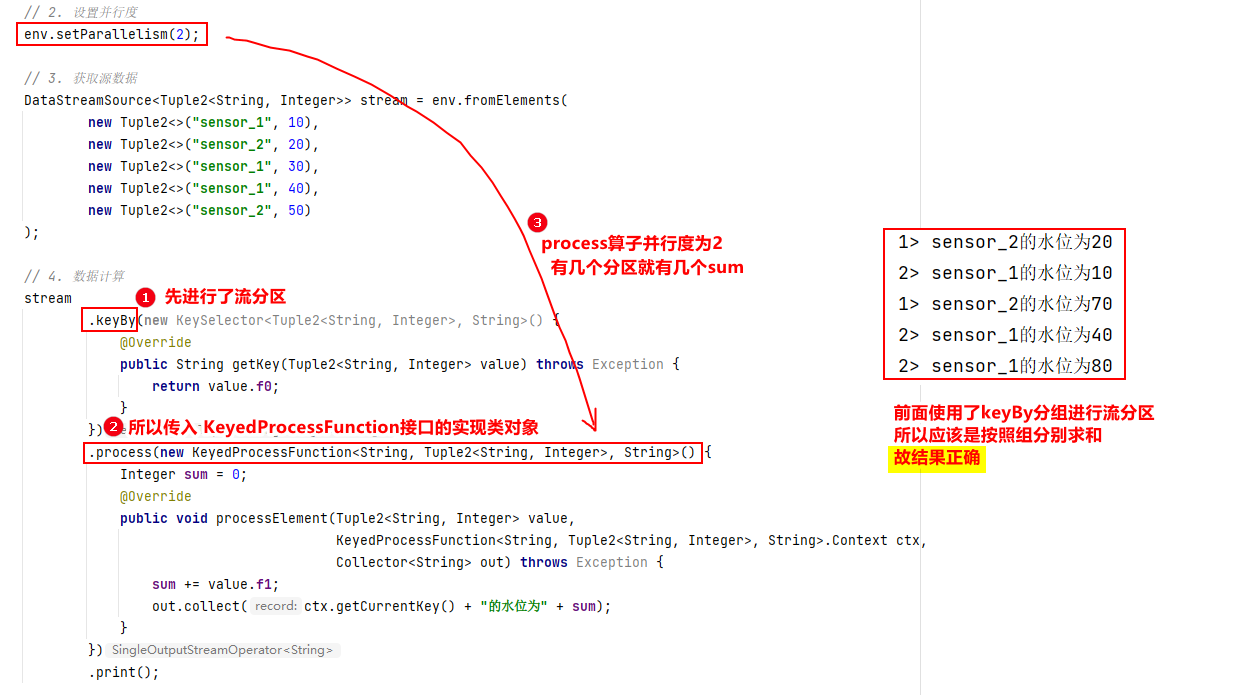

- 解决方法:使用字典map
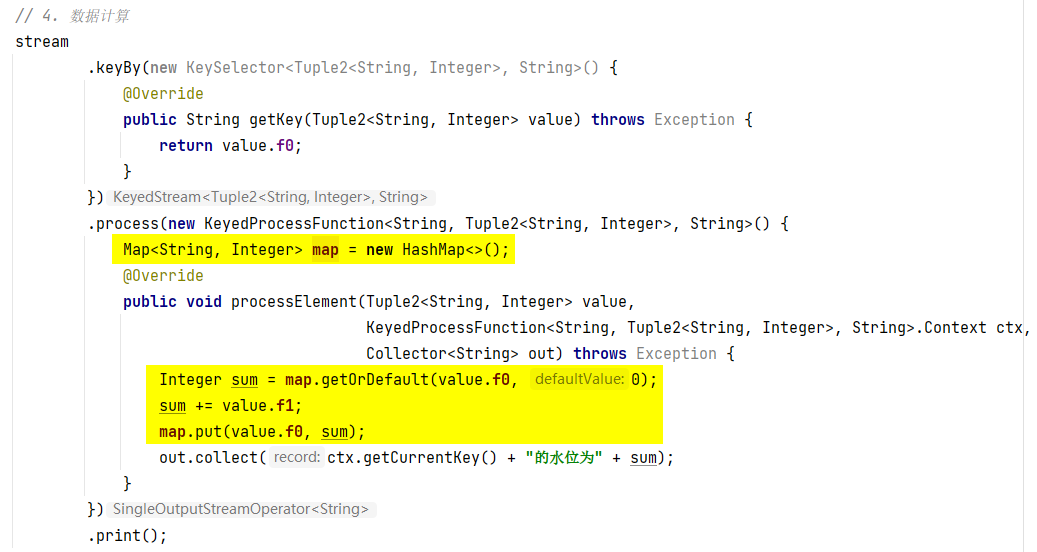
- 问题
- 比如:ProcessFunction接口的实现类对象
- 案例:多个用户多次点击页面,求总用户数,本质上就是一个去重问题。

结果为:public class MyTest { public static void main(String[] args) throws Exception { // 1. 获取 有界流 的 执行环境 StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment(); // 2. 设置并行度 env.setParallelism(2); // 3. 获取源数据 DataStreamSource<String> stream = env.readTextFile("input/uv.txt"); // 4. 数据计算 stream .map(line -> line.split(",")[0]) .process(new ProcessFunction<String, String>() { Set set = new HashSet(); @Override public void processElement(String value, ProcessFunction<String, String>.Context ctx, Collector<String> out) throws Exception { if (set.add(value)) { out.collect("总人数为:" + set.size()); } } }) .setParallelism(1) .print() .setParallelism(1); // 5. 执行(流数据处理必须有这一步) env.execute(); } }

7. 富函数类
-
除了process()算子外,每个算子传入的参数对象都有其对应的富函数类对象。比如:
stream.map(new MapFunction<Event, String>() { @Override public String map(Event e) throws Exception { 。。。 } }); // 传入对应的富函数类对象 stream.map(new RichMapFunction<Event, String>() { @Override public String map(Event e) throws Exception { 。。。 } }); -
因为
process()算子传入的八大参数对象都继承了AbstractRichFunction,所以没有RichProcessFunction

-
应用场景:
- 场景1:如果某算子要使用外部资源,则使用该算子时传入富函数类对象,提高资源利用率。
【一个常见的应用场景就是,如果我们希望连接到一个外部数据库进行读写操作,那么将连接操作放在 map()中每个元素都会进行一次连接一次数据库操作。改进方案为:该算子在每一个分区中开始时建立连接,结束时释放连接】

- 场景2:获取上下文
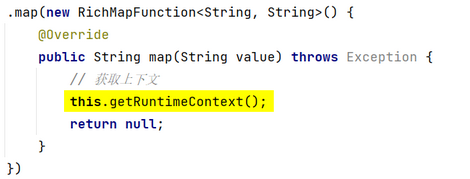
- 场景1:如果某算子要使用外部资源,则使用该算子时传入富函数类对象,提高资源利用率。

















 1156
1156











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











