






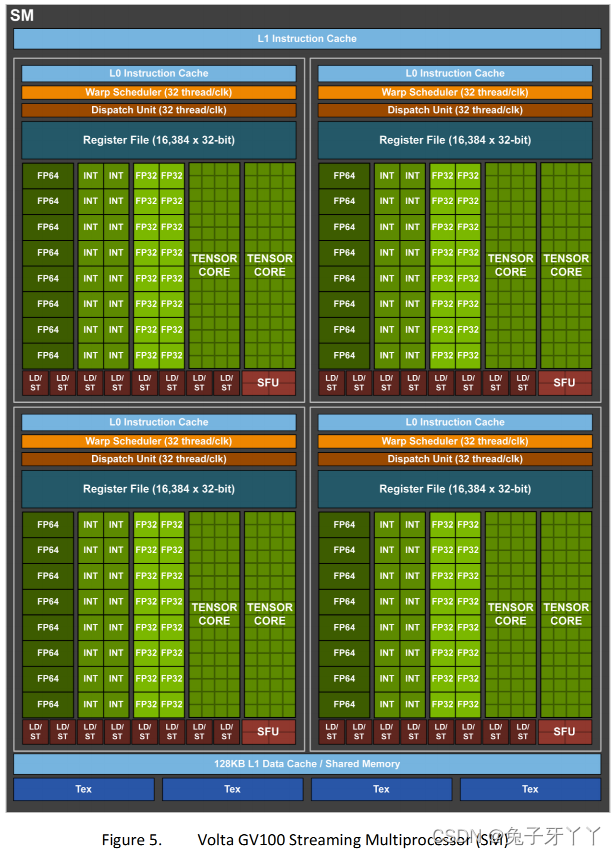
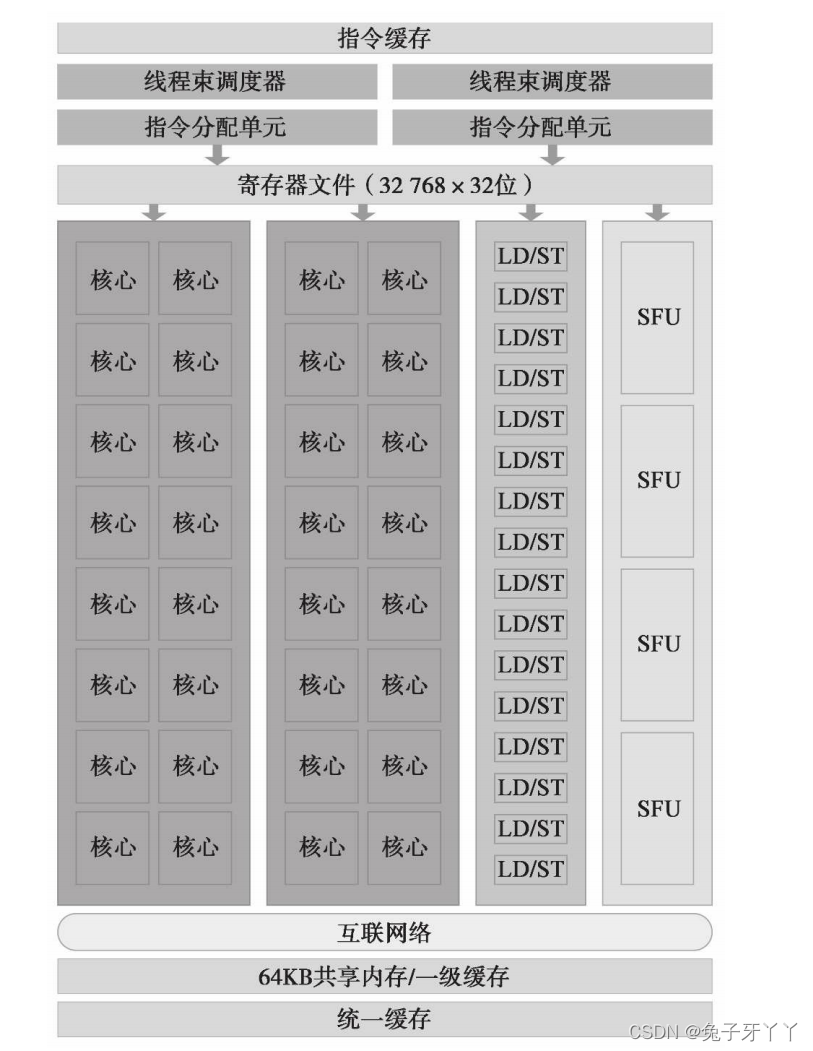
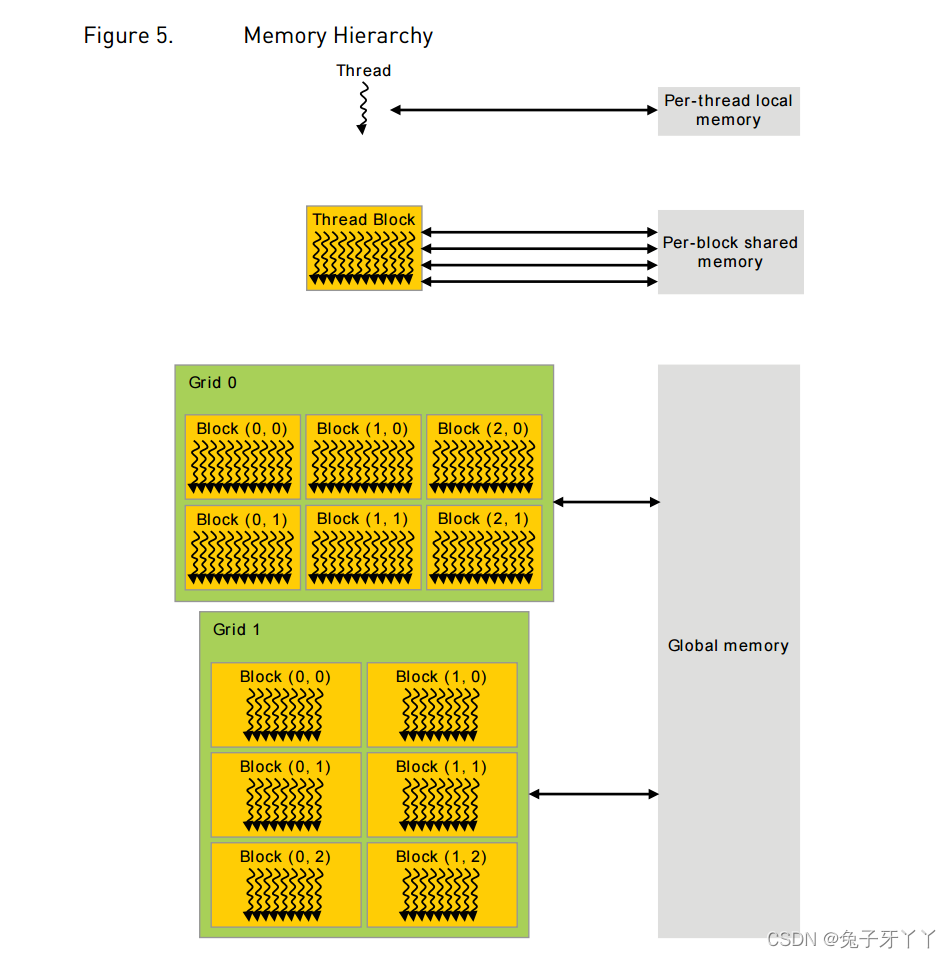
SM
在SM中,共享内存和寄存器是非常重要的资源。共享内存被分配在SM上的常驻线程
块中,寄存器在线程中被分配。线程块中的线程通过这些资源可以进行相互的合作和通
信。
WARP
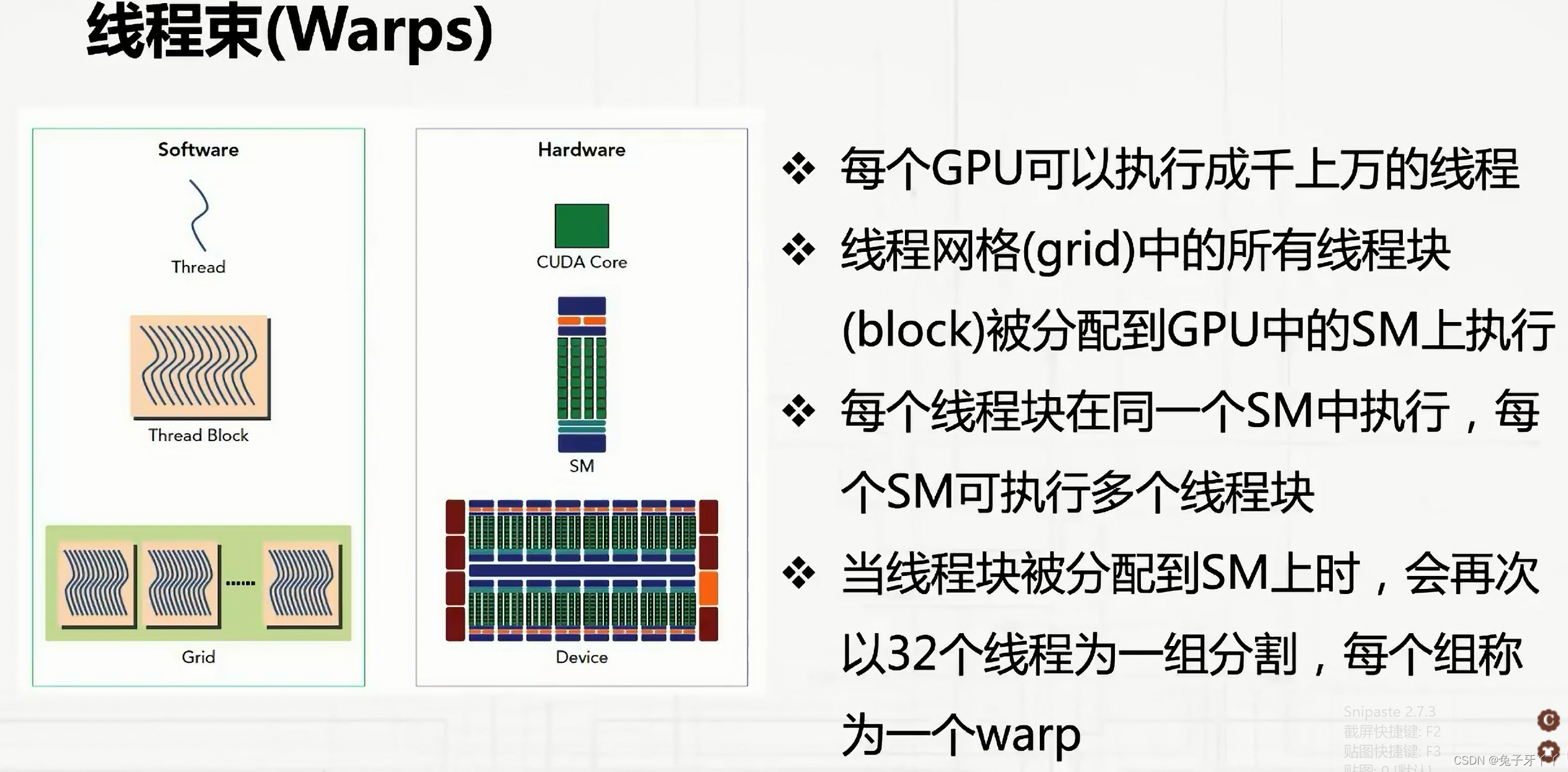
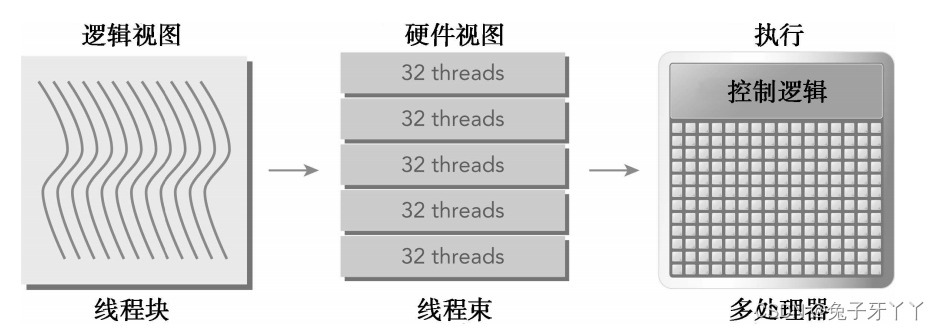
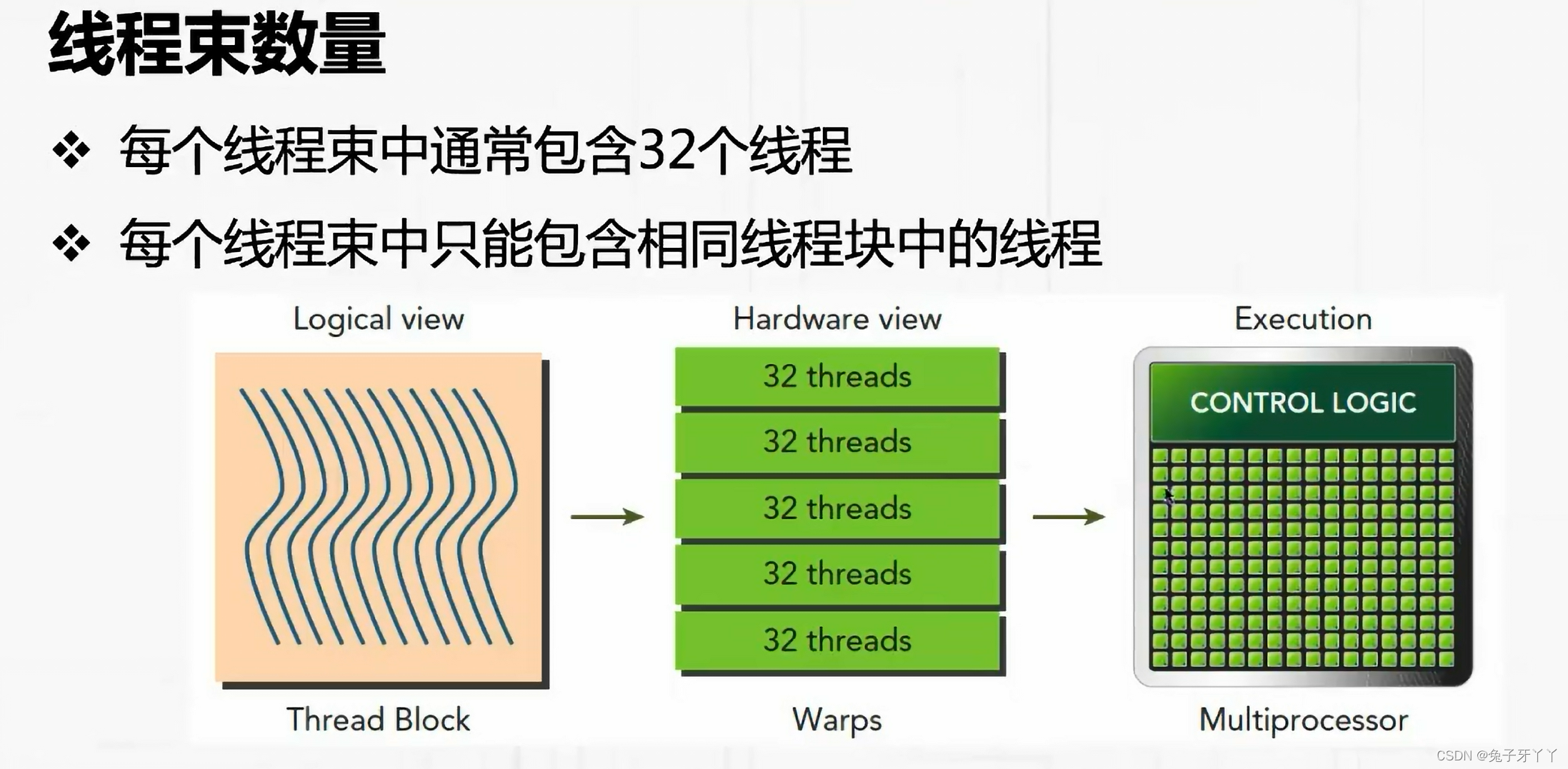
CUDA采用单指令多线程(SIMT)架构来管理和执行线程,每32个线程为一组,被称
为线程束(warp)。线程束中的所有线程同时执行相同的指令。每个线程都有自己的指
令地址计数器和寄存器状态,利用自身的数据执行当前的指令。每个SM都将分配给它的
线程块划分到包含32个线程的线程束中,然后在可用的硬件资源上调度执行。
一个线程块只能在一个SM上被调度。一旦线程块在一个SM上被调度,就会保存在该
SM上直到执行完成。在同一时间,一个SM可以容纳多个线程块
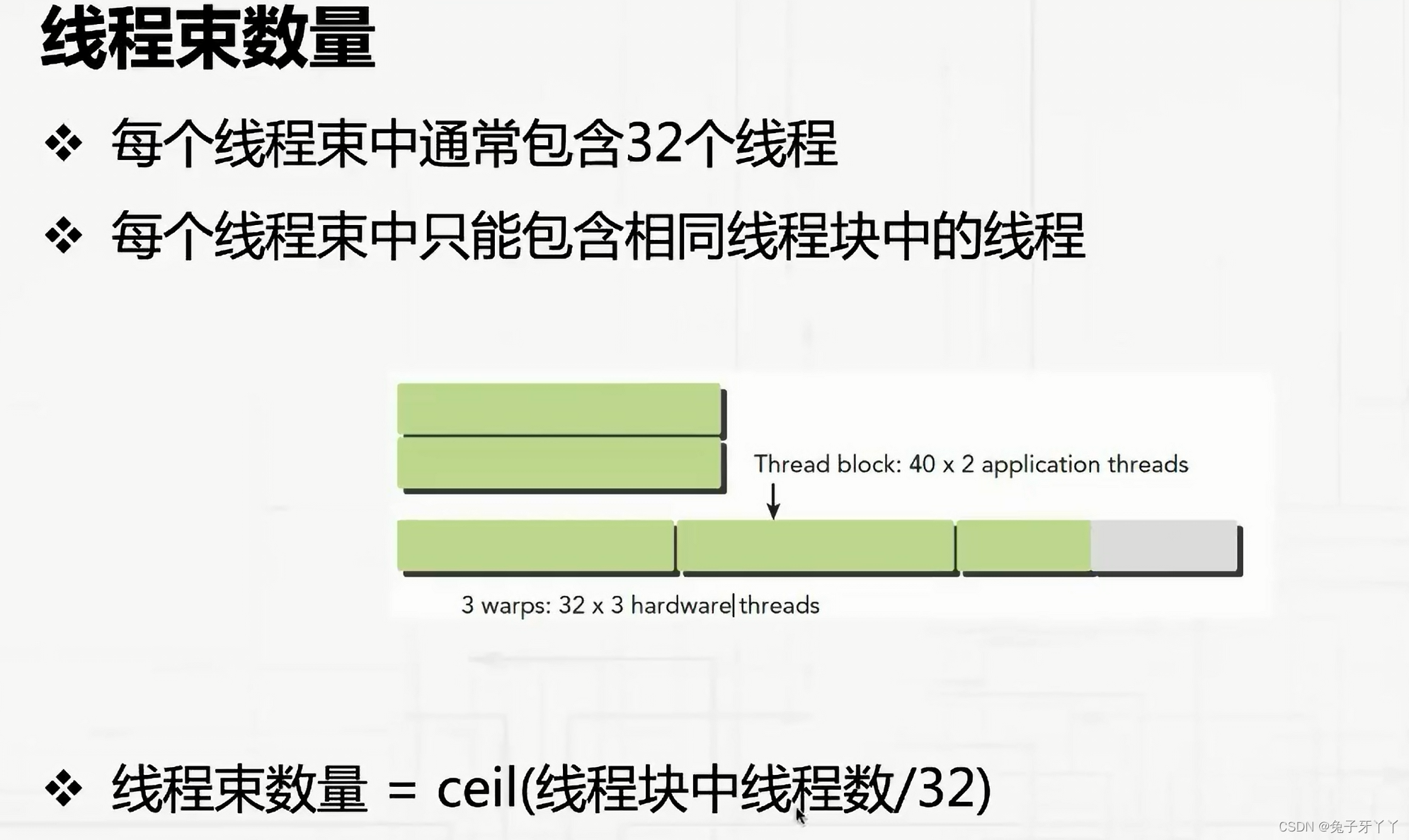
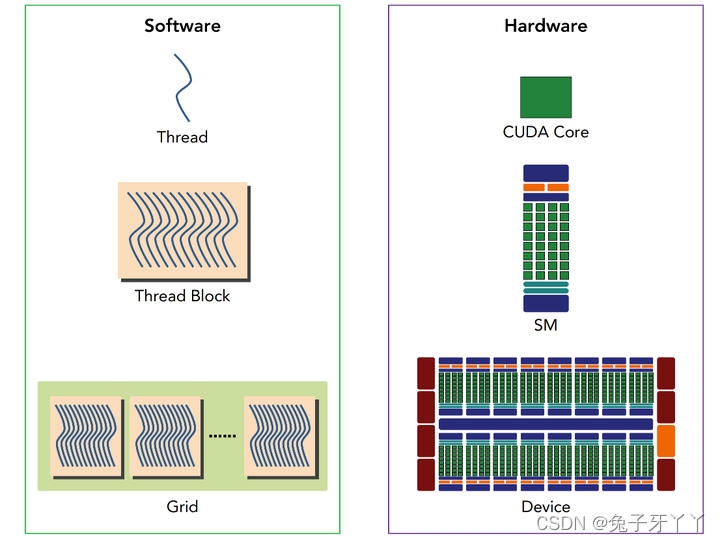
然而,从硬件的角度来看,所有的线程都被组织成了一维的,线程块可以被配置为一
维、二维或三维的。在一个块中,每个线程都有一个唯一的ID。对于一维的线程块,唯一
的线程ID被存储在CUDA的内置变量threadIdx.x中,并且,threadIdx.x中拥有连续值的线程
被分组到线程束中。例如,一个有128个线程的一维线程块被组织到4个线程束里,如下所
示:

内存管理
cudaMalloc
cudaMalloc(void** devPtr,size_t size):用于执行GPU内存分配,向设备分配一定字节的线性内存,并以devPtr的形式返回指向所分配内存的指针。
cudaMemcpy(void* dst,const void* src,size_t count,cudaMemcpyKind kind):负责主机和设备之间的数据传输,从src指向的源存储区复制一定数量的字节到dst指向的目标存储区,复制方向由kind指定。
kind种类:
cudaMemcpyHostToHost
cudaMemcpyHostToDevice
cudaMemcpyDeviceToHost:将存在GPU上的计算结果复制到主机的数组gpuRef中
cudaMemcpyDeviceToDevice
cudaMemcpy
cudaMemcpy()以同步方式执行,在cudaMemcpy函数返回以及传输操作完成之前主机应用程序是阻塞的。除了内核启动之外的CUDA调用都会返回一个错误的枚举类型cudaErroe_t。如果GPU内存分配成功,函数返回cudaSuccess,否则返回cudaErrorMemoryAllocation。
CUDA程序编写优化步骤
如何完成一个优秀的CUDA程序呢?这里有一份步骤给大家参考:
-
确定任务中的串行和并行的部分,选择合适的算法(首先将问题分解为几个步骤,确定哪些步骤可以用并行实现,并确定合适的算法);
-
按照算法确定数据和任务的划分方式,将每个需要实现的步骤映射为一个满足CUDA两层并行模型的内核函数,让每个SM上至少有6个活动warp和至少2个活动block;
-
编写一个能正确运行的程序作为优化的起点,要确保程序能稳定运行以及其正确性,在精度不足或者发生溢出时必须使用双精度浮点或者更长的整数类型;
-
优化显存访问,避免显存带宽成为瓶颈。在显存带宽得到完全优化前,其他优化不会产生明显效果。
-
优化指令流,在误差可接受的情况下,使用CUDA算术指令集中的快速指令;避免多余的同步;在只需要少量线程进行操作的情况下,使用类似
“if threaded<N”的方式,避免多个线程同时运行占用更长时间或者产生错误结果; -
资源均衡,调整每个线程处理的数据量,shared memory和register和使用量;通过调整block大小,修改算法和指令以及动态分配shared memory,都可以提高shared的使用效率;register的多少是由内核程序中使用寄存器最多的时刻的用量决定的,因此减小register的使用相对困难;节约register方法是使用shared memory存储变量;使用括号明确地表示每个变量的生存周期;使用占用寄存器较小的等效指令代替原有指令;
-
与主机通信优化,尽量减少CPU与GPU间的传输,使用cudaMallocHost分配主机端存储器,可以获得更大带宽;一次缓存较多的数据后再一次传输,可以获得较高的带宽;需要将结果显示到屏幕的时候,直接使用与图形学API互操作的功能;使用流和异步处理隐藏与主机的通信时间;使用zero-memory技术和Write-Combined memory提高可用带宽;
由此我们可以看到我们的优化之路还很漫长,这个优化步骤中的每一步都对应了大量可以去做的优化,上面这个只是个概述,不过我们可以看到有一句非常重要的话:
在显存带宽得到完全优化前,其他优化不会产生明显效果。
所以我们就先不要想其他的了,先完成最基本的优化,去尽可能的使用显卡的内存带宽~
线程束分化
控制流是高级编程语言的基本构造中的一种。GPU支持传统的、C风格的、显式的控
制流结构,例如,if…then…else、for和while。
CPU拥有复杂的硬件以执行分支预测,也就是在每个条件检查中预测应用程序的控制
流会使用哪个分支。如果预测正确,CPU中的分支只需付出很小的性能代价。如果预测不
正确,CPU可能会停止运行很多个周期,因为指令流水线被清空了。我们不必完全理解为
什么CPU擅长处理复杂的控制流。这个解释只是作为对比的背景。
GPU是相对简单的设备,它没有复杂的分支预测机制。一个线程束中的所有线程在同
一周期中必须执行相同的指令,如果一个线程执行一条指令,那么线程束中的所有线程都
必须执行该指令。如果在同一线程束中的线程使用不同的路径通过同一个应用程序,这可
能会产生问题。


因为同一线程束(warp)中的32个线程是严格并行执行相同指令的,那么如果cuda程序中出现分支,导致32个线程无法在同一时刻执行相同指令就会出现线程束分化的问题。比如在一个线程束中16个线程满足条件cond,而剩余16个线程的不满足,所以当前者在执行指令1时,后者则被禁用只能陪跑,反之亦然。所以,就降低了程序的并行性,在实际开发中应尽量避免
if (cond)
{
指令1
}
else
{
指令2
}

编译器对线程分支的优化能力有限,只有当分支下的代码量很少是优化才会起作用
注意线程束分化研究的是一个线程束中的线程,不同线程束中的分支互不影响。
减少线程束分化的方法:线程束内的线程是可以被我们控制的,那么我们就把都执行if的线程塞到一个线程束中,或者让一个线程束中的线程都执行if,另外线程都执行else的这种方式可以将效率提高很多。
/******* 假设只配置一个x=64的一维线程块,那么只有两个线程束 *****/
// 1. 这个kernel可以产生一个比较低效的分支
__global__ void mathKernel1(float *c)
{
int tid = blockIdx.x* blockDim.x + threadIdx.x;
float a = 0.0;
float b = 0.0;
if (tid % 2 == 0)
{
a = 100.0f;
}
else
{
b = 200.0f;
}
c[tid] = a + b;
}
// 2. 进行优化:
// 第一个线程束内的线程编号tid从0到31,tid/warpSize都等于0,那么就都执行if语句。
// 第二个线程束内的线程编号tid从32到63,tid/warpSize都等于1,执行else
// 线程束内没有分支,效率较高。
__global__ void mathKernel2(float *c)
{
int tid = blockIdx.x* blockDim.x + threadIdx.x;
float a = 0.0;
float b = 0.0;
if ((tid/warpSize) % 2 == 0)
{
a = 100.0f;
}
else
{
b = 200.0f;
}
c[tid] = a + b;
}
// 3. 分支预测技术
__global__ void mathKernel3(float *c)
{
int tid = blockIdx.x * blockDim.x + threadIdx.x;
float ia, ib;
ia = ib = 0.0f;
bool ipred = (tid % 2 == 0);
if (ipred)
{
ia = 100.0f;
}
if (!ipred)
{
ib = 200.0f;
}
c[tid] = ia + ib;
}
simpleDivergence.cu
#include "../common/common.h"
#include <cuda_runtime.h>
#include <stdio.h>
/*
* simpleDivergence demonstrates divergent code on the GPU and its impact on
* performance and CUDA metrics.
*/
__global__ void mathKernel1(float *c)
{
int tid = blockIdx.x * blockDim.x + threadIdx.x;
float ia, ib;
ia = ib = 0.0f;
if (tid % 2 == 0)
{
ia = 100.0f;
}
else
{
ib = 200.0f;
}
c[tid] = ia + ib;
}
__global__ void mathKernel2(float *c)
{
int tid = blockIdx.x * blockDim.x + threadIdx.x;
float ia, ib;
ia = ib = 0.0f;
if ((tid / warpSize) % 2 == 0)
{
ia = 100.0f;
}
else
{
ib = 200.0f;
}
c[tid] = ia + ib;
}
__global__ void mathKernel3(float *c)
{
int tid = blockIdx.x * blockDim.x + threadIdx.x;
float ia, ib;
ia = ib = 0.0f;
bool ipred = (tid % 2 == 0);
if (ipred)
{
ia = 100.0f;
}
if (!ipred)
{
ib = 200.0f;
}
c[tid] = ia + ib;
}
__global__ void mathKernel4(float *c)
{
int tid = blockIdx.x * blockDim.x + threadIdx.x;
float ia, ib;
ia = ib = 0.0f;
int itid = tid >> 5;
if (itid & 0x01 == 0)
{
ia = 100.0f;
}
else
{
ib = 200.0f;
}
c[tid] = ia + ib;
}
__global__ void warmingup(float *c)
{
int tid = blockIdx.x * blockDim.x + threadIdx.x;
float ia, ib;
ia = ib = 0.0f;
if ((tid / warpSize) % 2 == 0)
{
ia = 100.0f;
}
else
{
ib = 200.0f;
}
c[tid] = ia + ib;
}
int main(int argc, char **argv)
{
// set up device
int dev = 0;
cudaDeviceProp deviceProp;
CHECK(cudaGetDeviceProperties(&deviceProp, dev));
printf("%s using Device %d: %s\n", argv[0], dev, deviceProp.name);
// set up data size
int size = 64;
int blocksize = 64;
if(argc > 1) blocksize = atoi(argv[1]);
if(argc > 2) size = atoi(argv[2]);
printf("Data size %d ", size);
// set up execution configuration
dim3 block (blocksize, 1);
dim3 grid ((size + block.x - 1) / block.x, 1);
printf("Execution Configure (block %d grid %d)\n", block.x, grid.x);
// allocate gpu memory
float *d_C;
size_t nBytes = size * sizeof(float);
CHECK(cudaMalloc((float**)&d_C, nBytes));
// run a warmup kernel to remove overhead
size_t iStart, iElaps;
CHECK(cudaDeviceSynchronize());
iStart = seconds();
warmingup<<<grid, block>>>(d_C);
CHECK(cudaDeviceSynchronize());
iElaps = seconds() - iStart;
printf("warmup <<< %4d %4d >>> elapsed %d sec \n", grid.x, block.x,
iElaps );
CHECK(cudaGetLastError());
// run kernel 1
iStart = seconds();
mathKernel1<<<grid, block>>>(d_C);
CHECK(cudaDeviceSynchronize());
iElaps = seconds() - iStart;
printf("mathKernel1 <<< %4d %4d >>> elapsed %d sec \n", grid.x, block.x,
iElaps );
CHECK(cudaGetLastError());
// run kernel 2
iStart = seconds();
mathKernel2<<<grid, block>>>(d_C);
CHECK(cudaDeviceSynchronize());
iElaps = seconds() - iStart;
printf("mathKernel2 <<< %4d %4d >>> elapsed %d sec \n", grid.x, block.x,
iElaps );
CHECK(cudaGetLastError());
// run kernel 3
iStart = seconds();
mathKernel3<<<grid, block>>>(d_C);
CHECK(cudaDeviceSynchronize());
iElaps = seconds() - iStart;
printf("mathKernel3 <<< %4d %4d >>> elapsed %d sec \n", grid.x, block.x,
iElaps);
CHECK(cudaGetLastError());
// run kernel 4
iStart = seconds();
mathKernel4<<<grid, block>>>(d_C);
CHECK(cudaDeviceSynchronize());
iElaps = seconds() - iStart;
printf("mathKernel4 <<< %4d %4d >>> elapsed %d sec \n", grid.x, block.x,
iElaps);
CHECK(cudaGetLastError());
// free gpu memory and reset divece
CHECK(cudaFree(d_C));
CHECK(cudaDeviceReset());
return EXIT_SUCCESS;
}
nvprof
nvprof --query-metrics
nvprof --metrics branchefficiency ./sumArray
nvcc -g -G -O2 -arch=sm_70 -o
-g:去除对主机端代码的优化
-G:去除对GPU端代码的优化

线程束分支会降低GPU实际的计算能力
线程束分支对程序性能影响通过分支效率(branch efficiency)衡量

sumMatrix.cu
#include "../common/common.h"
#include <cuda_runtime.h>
#include <stdio.h>
/*
* This example implements matrix element-wise addition on the host and GPU.
* sumMatrixOnHost iterates over the rows and columns of each matrix, adding
* elements from A and B together and storing the results in C. The current
* offset in each matrix is stored using pointer arithmetic. sumMatrixOnGPU2D
* implements the same logic, but using CUDA threads to process each matrix.
*/
void initialData(float *ip, const int size)
{
int i;
for(i = 0; i < size; i++)
{
ip[i] = (float)( rand() & 0xFF ) / 10.0f;
}
}
void sumMatrixOnHost(float *A, float *B, float *C, const int nx, const int ny)
{
float *ia = A;
float *ib = B;
float *ic = C;
for (int iy = 0; iy < ny; iy++)
{
for (int ix = 0; ix < nx; ix++)
{
ic[ix] = ia[ix] + ib[ix];
}
ia += nx;
ib += nx;
ic += nx;
}
return;
}
void checkResult(float *hostRef, float *gpuRef, const int N)
{
double epsilon = 1.0E-8;
for (int i = 0; i < N; i++)
{
if (abs(hostRef[i] - gpuRef[i]) > epsilon)
{
printf("host %f gpu %f ", hostRef[i], gpuRef[i]);
printf("Arrays do not match.\n\n");
break;
}
}
}
// grid 2D block 2D
__global__ void sumMatrixOnGPU2D(float *A, float *B, float *C, int NX, int NY)
{
unsigned int ix = blockIdx.x * blockDim.x + threadIdx.x;
unsigned int iy = blockIdx.y * blockDim.y + threadIdx.y;
unsigned int idx = iy * NX + ix;
if (ix < NX && iy < NY)
{
C[idx] = A[idx] + B[idx];
}
}
int main(int argc, char **argv)
{
// set up device
int dev = 0;
cudaDeviceProp deviceProp;
CHECK(cudaGetDeviceProperties(&deviceProp, dev));
CHECK(cudaSetDevice(dev));
// set up data size of matrix
int nx = 1 << 14;
int ny = 1 << 14;
int nxy = nx * ny;
int nBytes = nxy * sizeof(float);
// malloc host memory
float *h_A, *h_B, *hostRef, *gpuRef;
h_A = (float *)malloc(nBytes);
h_B = (float *)malloc(nBytes);
hostRef = (float *)malloc(nBytes);
gpuRef = (float *)malloc(nBytes);
// initialize data at host side
size_t iStart = seconds();
initialData(h_A, nxy);
initialData(h_B, nxy);
size_t iElaps = seconds() - iStart;
memset(hostRef, 0, nBytes);
memset(gpuRef, 0, nBytes);
// add matrix at host side for result checks
iStart = seconds();
sumMatrixOnHost (h_A, h_B, hostRef, nx, ny);
iElaps = seconds() - iStart;
// malloc device global memory
float *d_MatA, *d_MatB, *d_MatC;
CHECK(cudaMalloc((void **)&d_MatA, nBytes));
CHECK(cudaMalloc((void **)&d_MatB, nBytes));
CHECK(cudaMalloc((void **)&d_MatC, nBytes));
// transfer data from host to device
CHECK(cudaMemcpy(d_MatA, h_A, nBytes, cudaMemcpyHostToDevice));
CHECK(cudaMemcpy(d_MatB, h_B, nBytes, cudaMemcpyHostToDevice));
// invoke kernel at host side
int dimx = 32;
int dimy = 32;
if(argc > 2)
{
dimx = atoi(argv[1]);
dimy = atoi(argv[2]);
}
dim3 block(dimx, dimy);
dim3 grid((nx + block.x - 1) / block.x, (ny + block.y - 1) / block.y);
// execute the kernel
CHECK(cudaDeviceSynchronize());
iStart = seconds();
sumMatrixOnGPU2D<<<grid, block>>>(d_MatA, d_MatB, d_MatC, nx, ny);
CHECK(cudaDeviceSynchronize());
iElaps = seconds() - iStart;
printf("sumMatrixOnGPU2D <<<(%d,%d), (%d,%d)>>> elapsed %d ms\n", grid.x,
grid.y,
block.x, block.y, iElaps);
CHECK(cudaGetLastError());
// copy kernel result back to host side
CHECK(cudaMemcpy(gpuRef, d_MatC, nBytes, cudaMemcpyDeviceToHost));
// check device results
checkResult(hostRef, gpuRef, nxy);
// free device global memory
CHECK(cudaFree(d_MatA));
CHECK(cudaFree(d_MatB));
CHECK(cudaFree(d_MatC));
// free host memory
free(h_A);
free(h_B);
free(hostRef);
free(gpuRef);
// reset device
CHECK(cudaDeviceReset());
return EXIT_SUCCESS;
}
![]()















 8万+
8万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









