







0、前言
这里提到的 Java 对象不仅仅包含引用类型(Object),还包含基本数据类型(boolean、int、long、float、double)。文中大部分图片来源于 B站 黑马程序员。
1、在栈上的数据存储
1.1、局部变量
局部变量包含以下情况:
- 方法中定义的变量
- 方法的形参
注:在非 static 修饰的成员方法中,第一个形参是
this,代表当前类的实例对象
1.2、槽位(slot)
各种类型变量在堆空间和栈空间中的内存分配,常说的 int 占用 4B 是针对堆中变量,而在栈中是按照槽位(slot)进行分配的。
| 数据类型 | 字节数(堆空间) | 槽位数(栈空间) |
|---|---|---|
boolean | 1B | 1 |
char | 2B | 1 |
byte | 1B | 1 |
short | 2B | 1 |
int | 4B | 1 |
long | 8B | 2 |
float | 4B | 1 |
double | 8B | 2 |
Object | 见对象在堆上的数据存储中的相关讨论 | 1 |
总结:
1 slot = 机器字长(32 位机中 32 bit,64 位机中 64 bit)long、double占用 2 个 slot- 其它类型占用 1 个 slot
1.3、堆数据和栈数据的赋值过程
一般情况而言,同类型变量在堆中的长度更短,在栈中的长度更长。总的转换思路为:
堆 -> 栈:按符号位进行填充,负数在前面填充1,正数在前面填充0,能够保证在补码意义上值保持不变栈 -> 堆:截断 (boolean 类型比较特殊,只取最后 1bit,而不是 1B)
下面分别是 -5 和 5 的补码表示
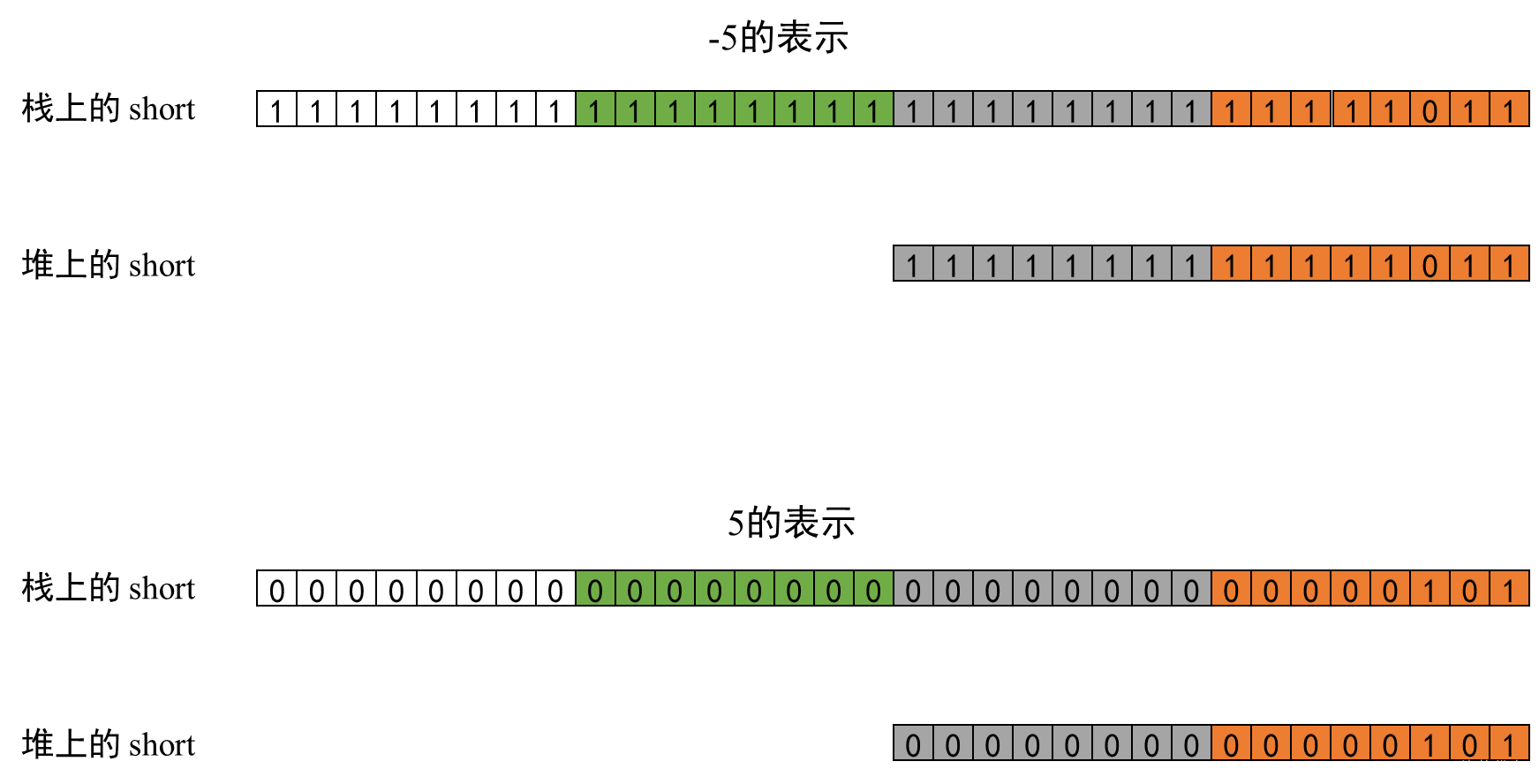
复习点:给定一个负数,写出其补码
- 先写出其倒数(正数)的补码(即原码)
- 从右到左找到第一个1,左取反,右不变
1.4、测试案例
Java 代码
public class ObjectStackLayout {
static class MyObject {
String aString;
Integer aInteger;
int anInt;
boolean aBoolean;
double aDouble;
}
public static void main(String[] args) {
boolean b = true;
char ch = 'a';
short sh = 10;
int x = 1;
float f = 1.0f;
double d = 2.2;
String s = "hello world";
MyObject myObject = new MyObject();
}
static short num = -5;
private void calculate(int x) {
// 堆数据 -> 栈数据
short y = num;
// 栈数据 -> 堆数据
num = y;
}
}
main 方法的字节码
// boolean b = true
// 从istore_1指令可以看出,将b作为int类型处理(istore含义是int store)
0 iconst_1
1 istore_1
// char ch = 'a'
2 bipush 97
4 istore_2
// short sh = 10
5 bipush 10
7 istore_3
// int x = 1
8 iconst_1
9 istore 4
// float = 1.0f
// 使用fstore,说明float类型数据和int类型数据在栈上的存储不同
11 fconst_1
12 fstore 5
14 ldc2_w #2 <2.2>
17 dstore 6
19 ldc #4 <hello world>
21 astore 8
23 new #5 <org/example/layout/stack/ObjectStackLayout$MyObject>
26 dup
27 invokespecial #6 <org/example/layout/stack/ObjectStackLayout$MyObject.<init> : ()V>
30 astore 9
32 return
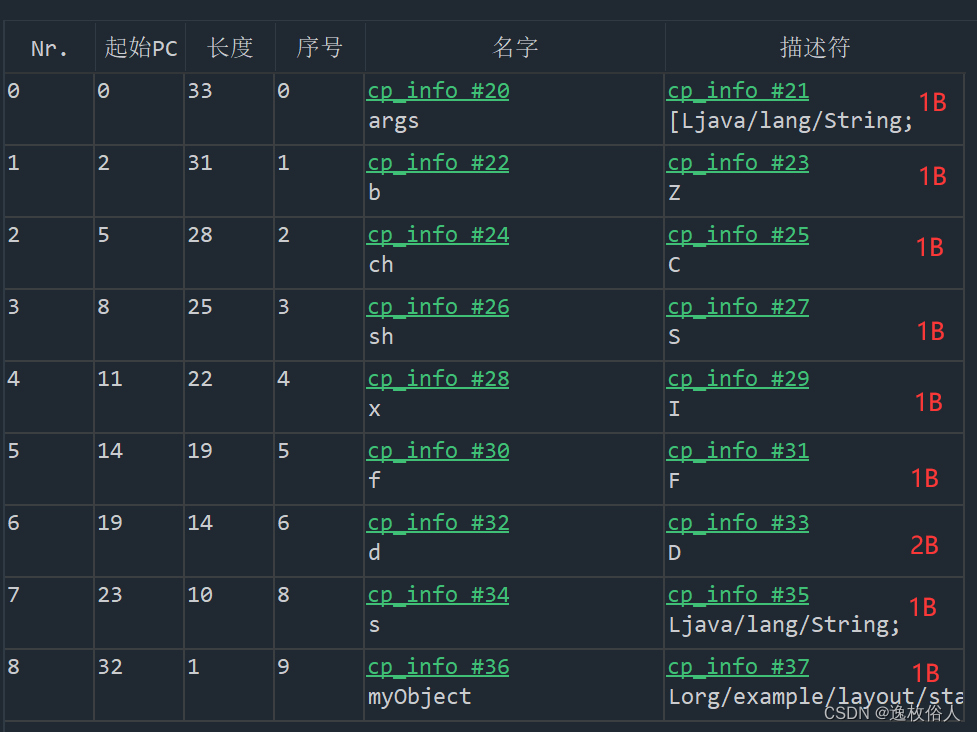
main 方法的局部变量表
槽总数 = 1 + 1 + 1 + 1 + 1 + 1 + 2 + 1 + 1 = 10

总结:
- 形参也是局部变量,测试 calculate 方法可以看到为局部变量
this分配槽位 - 浮点数和整数之间使用不同的字节码指令
2、在堆上的数据存储
2.1、Java 对象的堆内存布局
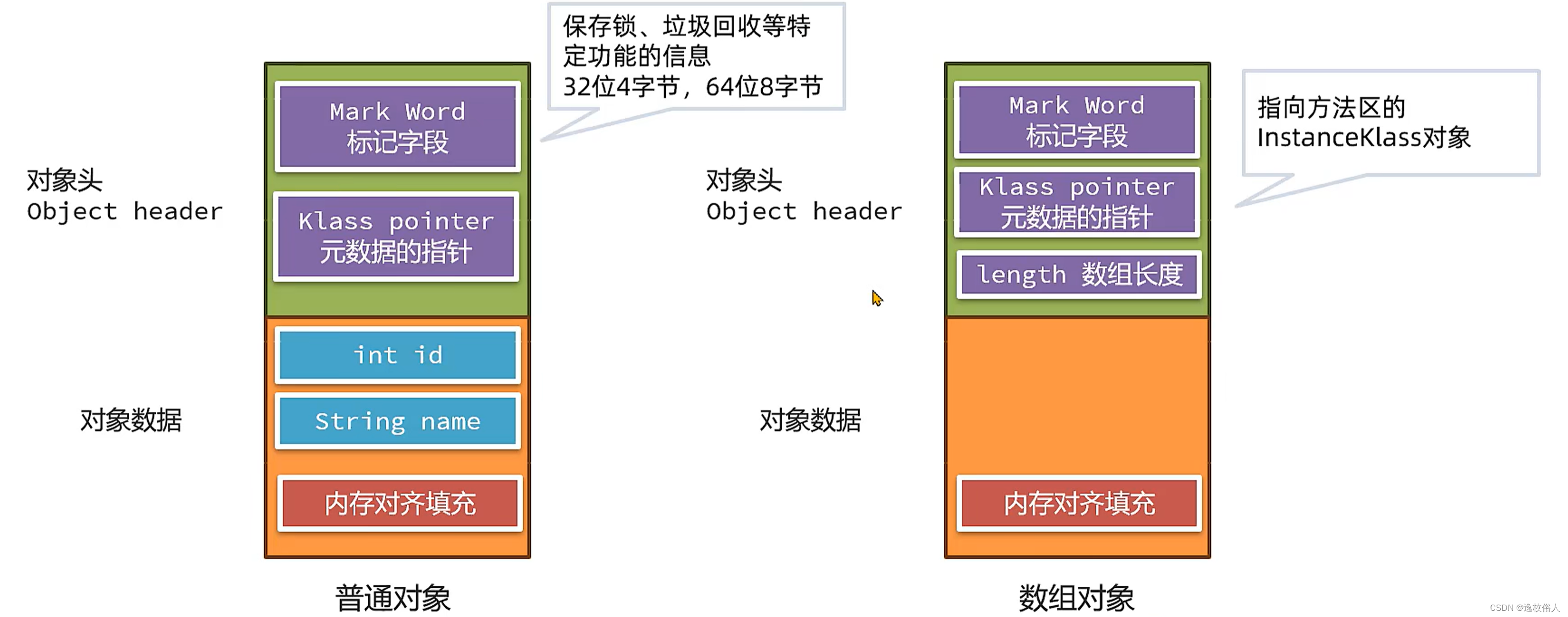
标记字段(Mark Word)
标记字段取决于机器字长、是否开启指针压缩这两个因素,下图是 **64 位机开启指针压缩(默认情况)**的情况

上面共有 5 种状态,原本应该使用 3 bit 来表示锁的状态位,这会导致处于轻量级锁状态和重量级锁状态的对象少了 1 bit 的指针,这样锁数量的上限就变为原来的 1/2。因此,将正常状态和偏向锁的最后 2bit 相同,使用额外的 1bit 来区分正常状态和偏向锁状态。
| 锁状态 | 二进制值(两个 bit 位) |
|---|---|
| 轻量级锁 | 00 |
| 无锁、偏向锁 | 01 |
| 重量级锁 | 10 |
| GC 标记阶段 | 11 |
可能需要注意的点:其中有 1bit 提供给 CMS 垃圾收集器进行使用,后面在 GC 相关文章中再考虑之间的关联
在 64 位机关闭指针压缩的情况下,只是简单地将 cms使用位 弃用。

在 32 位机的情况下,不存在 cms使用位,同时将高位 32 bit舍弃即可。

元数据指针(Klass pointer)
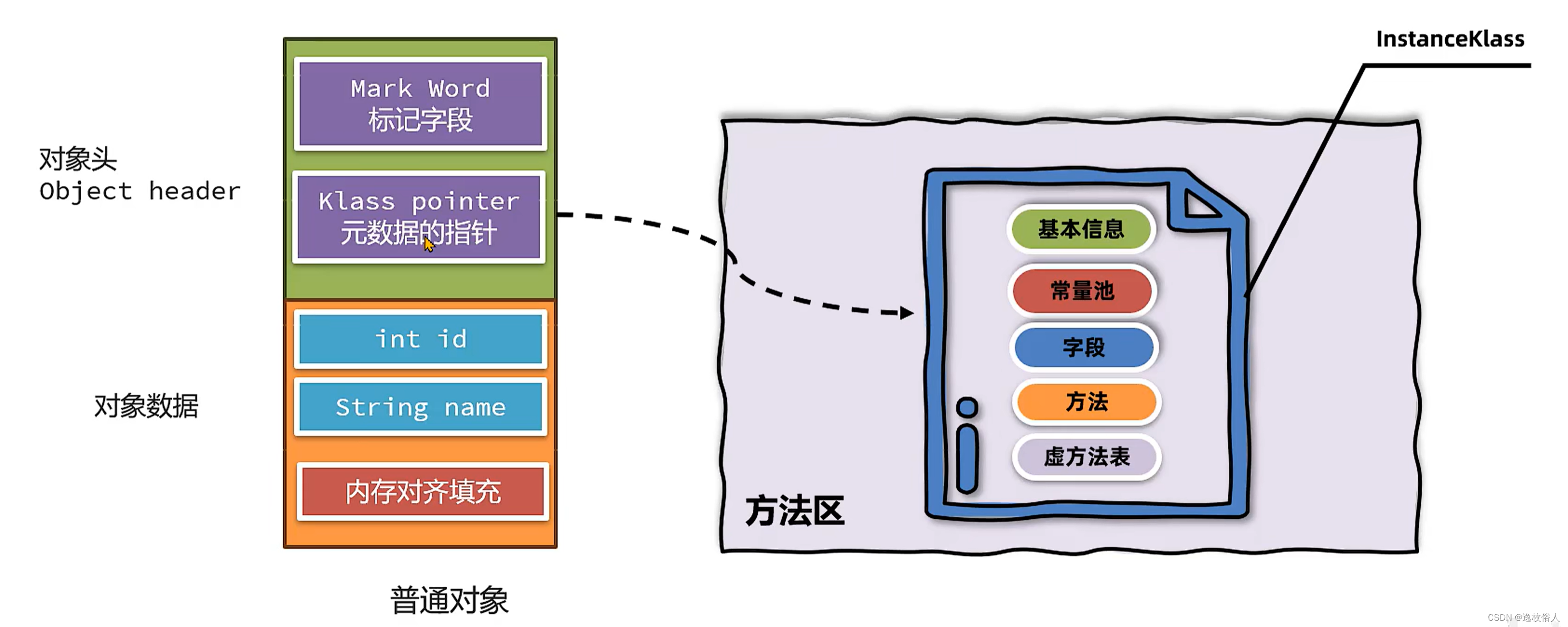
| 组成部分 | 偏移量 |
|---|---|
| 基本信息 | |
| 常量池 | |
| 字段 | |
| 方法 | |
| 虚方法表 | 0x1B8 |
后面在针对 invokevirtual 指令的分析中需要使用到虚方法表的偏移量
hsdb 工具进行验证:
2.2、布局规则
规则优先级从高到低依次为:
- 内存对齐
- 父类优先
- 基本类型优先
- 字段对齐
- 字段重排列
- 类型更长的变量排在前面,类型更短的变量排在后面(由规则(4)+规则(5)得到的一种现象)
2.3.1、内存对齐
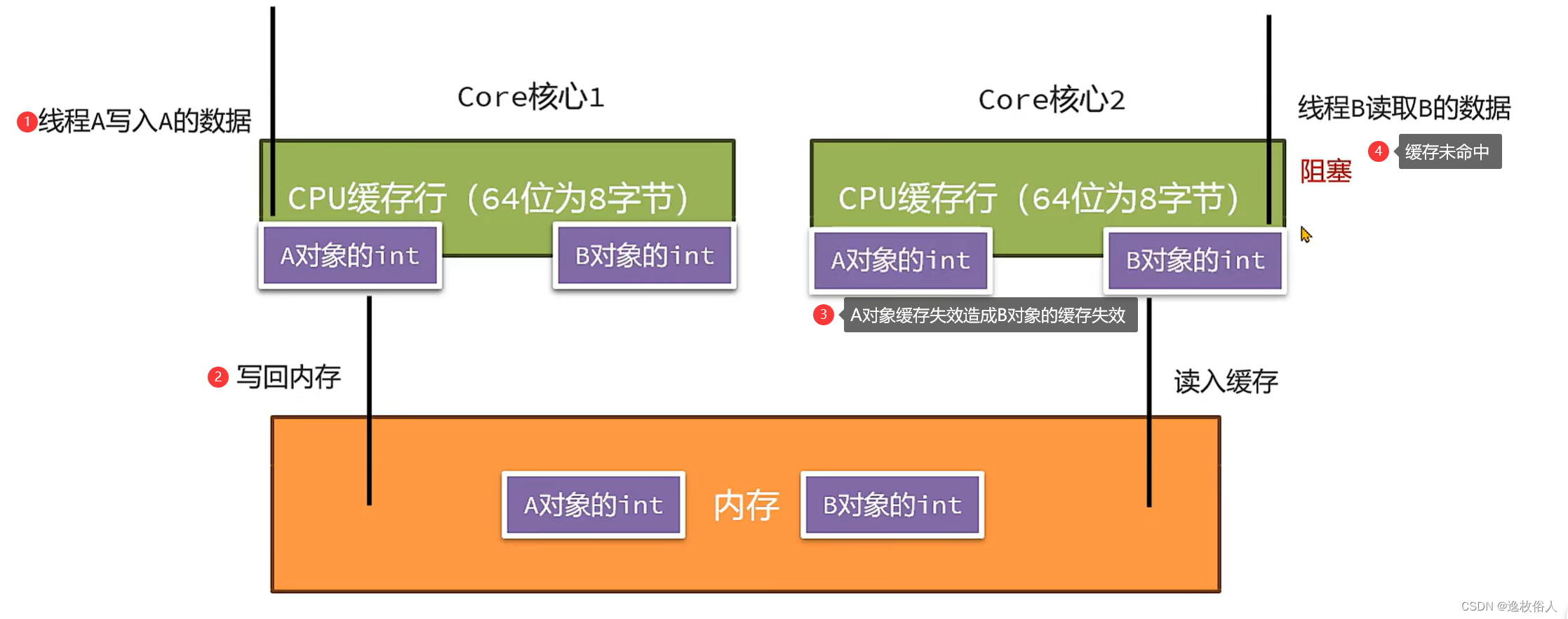
在没有开启指针压缩的情况下,同样会进行内存对齐。
内存对齐的目的是 64 位机上的 CPU 缓存行大小是 8B,保证对象对齐 8B,可以保证并发情况下,两个对象的修改不会因为缓存行而相互影响。
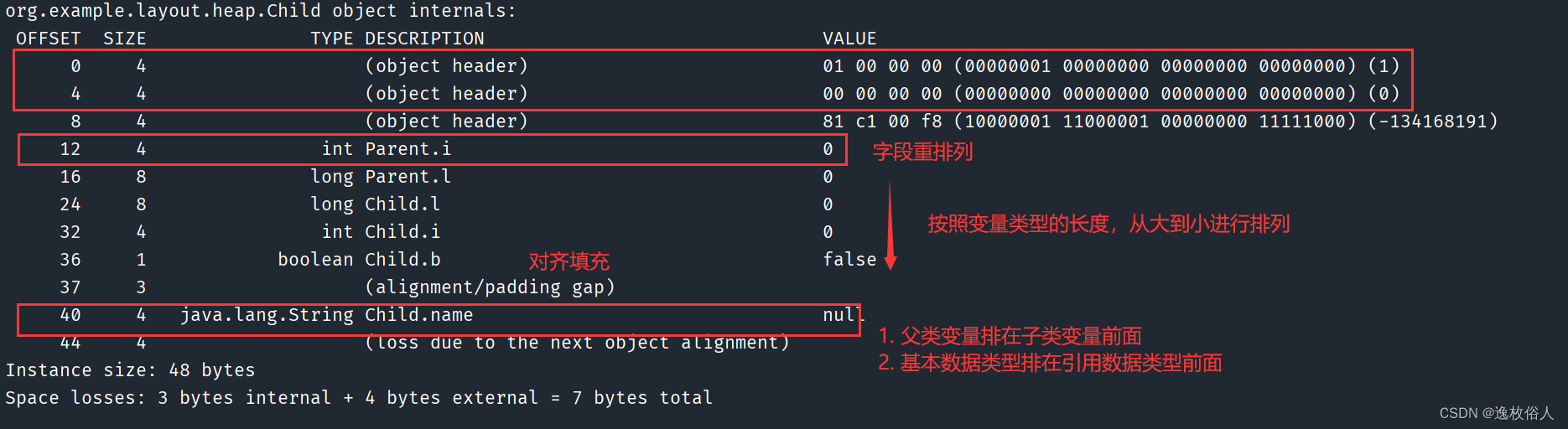
2.3.2、父类优先
父类字段在子类字段之前
2.3.3、基本类型优先
2.3.4、字段对齐
字段对齐的目的是为了避免一个字段被拆分到两个 CPU 缓存行中而造成的性能下降。
具体方法:若变量类型的长度为 n,则该变量的起始偏移必须是 k × \times × n,单位为 Byte
2.3.5、字段重排列
字段对齐重排列是为了尽可能减少字段对齐带来的内存浪费,是字段对齐的优化措施。
2.3、测试案例
<dependency>
<groupId>org.openjdk.jol</groupId>
<artifactId>jol-core</artifactId>
<version>0.7</version>
</dependency>
class Parent {
long l;
int i;
}
class Child extends Parent {
String name;
boolean b;
int i;
long l;
}
public class ObjectHeapLayout {
public static void main(String[] args) {
// 测试父类中的实例变量一定在子类之前分配,并且引用类型一定在每个类的最后分配
System.out.println(ClassLayout.parseInstance(new Child()).toPrintable());
// 测试字符串的实际占用空间
System.out.println(ClassLayout.parseInstance("123").toPrintable());
// 测试数组(nums也是一个引用指针)
int[] nums = new int[]{1, 2, 3};
System.out.println(ClassLayout.parseInstance(nums).toPrintable());
System.out.println(ClassLayout.parseInstance(new Object()).toPrintable());
// System.out.println(ClassLayout.parseInstance(null).toPrintable());//抛出异常
}
}
3、方法调用的原理
| 与方法调用相关的字节码指令 | 使用场景 | 绑定类型 |
|---|---|---|
invokestatic | 调用 static 修饰的方法(静态方法) | 静态绑定 |
invokespecial | 调用 private 成员方法和构造器 通过 super 调用的成员方法和构造器 | 静态绑定 |
invokevirtual | 调用 非private 成员方法 | 动态绑定 |
invokeinterface | 调用接口中的方法 | 动态绑定 |
invokedynamic | 主要应用于 lambda 表达式 |
3.1、静态绑定
方法的基本信息会保存在运行时常量池中,其类型为 CONSTANT_Methodref_info。而在字节码指令中,会通过类似 #4 来引用运行时常量池中的内容,其中 #4 称为符号引用。
静态绑定:在方法第一次调用时,这些符号引用会被替换为直接引用(即方法的内存地址),这种方式称为静态绑定。
不能够重写的方法:
- static 修饰的方法(
invokestatic) - private 修饰的方法和构造器方法(
invokespecial) - final 修饰的方法
个人理解(胡言乱语中)
- 静态绑定、动态绑定的考虑出发点是方法是否能够重写
- public final 修饰的方法也可以使用静态绑定实现,但实际上是
invokevirtual(动态绑定),猜测是出于实现的简洁性考虑。public final 修饰的方法和 public、protected 等修饰的方法在虚方法表中一视同仁,无需区分。子类无法重写 public final 修饰的方法,因此相当于 public final 方法对应的那一项在子类的虚方法表中也相同- 可以认为方法能否被重写由
final关键字负责,而是否是静态绑定由private、static关键字负责。之所以 private、static 不能够被重写,只是因为它们的特性决定了它们具有 final 的作用。甚至可以在编译器中实现这样的逻辑,为 private、static 默认添加上 final。(由比特位标识)
3.2、动态绑定(多态、方法重写的实现原理)
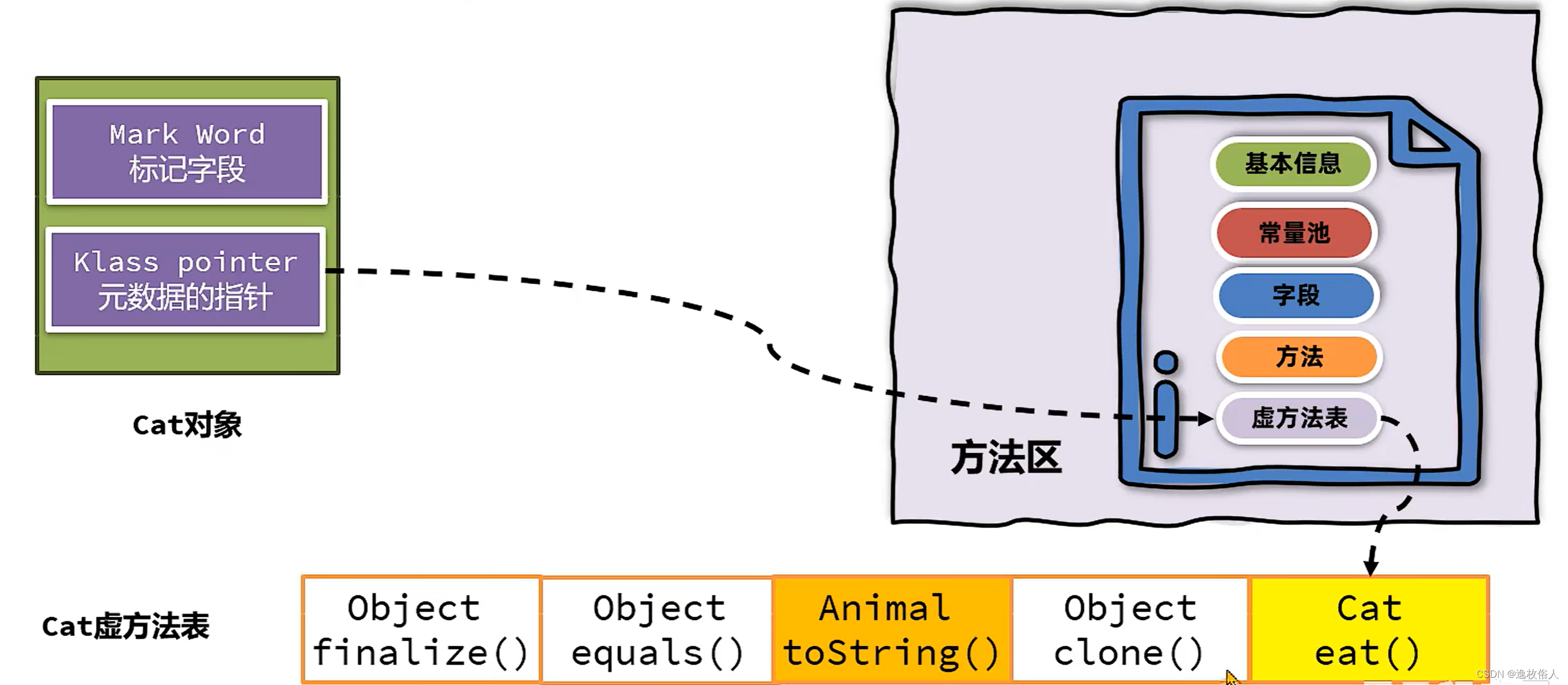
3.2.1、虚方法表(vtable、itable)
虚方法表在方法区中,本质上是一个数组,表中实际保存的是直接引用,即方法的内存地址。
对于两个同名的重载方法,在字节码层面实际上有着完全不同的方法签名(形参),所以不需要额外区分。
子类会继承父类的虚方法表,如果子类中重写了某个方法,就会覆盖相应的项,例如下图中 Animal 类重写了 Object 类的 toString 方法,Cat 类重写了 Animal 类的 eat 方法。

3.2.2、invokevirtual 指令的执行流程
(TODO:这里最好再添加上一部分多态的代码和此时的操作数栈)
- 调用
cat.eat()时,此时 Cat 的实例对象在 new 的时候已经被压入操作数栈。这里对应着两条字节码指令:dup、invokevirtual #n - 在执行
invokevirtual指令时,会从操作数栈中取出实例对象的内存地址,再通过其对象头中的 Klass pointer(元数据指针)找到其在方法区中的 InstanceKlass 对象,从固定偏移量(0x1B8)中找到虚方法表 - 虚方法表中的每个元素都是一个地址,在关闭指针压缩的情况下,每个地址占用 8B
校验虚方法表中的内容: 因为得到方法的直接引用(地址)后,即使查看该地址的内容,不能够直接看出该方法的方法名是什么,方法来源于哪个父类等信息,因此需要从父类 Object 逐层向下搜索,比较类中各个方法的地址和通过虚方法表中得到的地址。
3.2.3、使用 HSDB 对上面问题进行分析的流程
TODO
















 1万+
1万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









