






 本文介绍了一种基于约1亿参数的ViT的改进版本,针对遥感任务设计,采用旋转可变尺寸窗口注意力以降低计算和内存负担。实验显示,新模型在DOTA-V1.0数据集上表现出色,且在分类和分割任务中具有竞争力,证明了其在RS领域的潜力和效率
本文介绍了一种基于约1亿参数的ViT的改进版本,针对遥感任务设计,采用旋转可变尺寸窗口注意力以降低计算和内存负担。实验显示,新模型在DOTA-V1.0数据集上表现出色,且在分类和分割任务中具有竞争力,证明了其在RS领域的潜力和效率
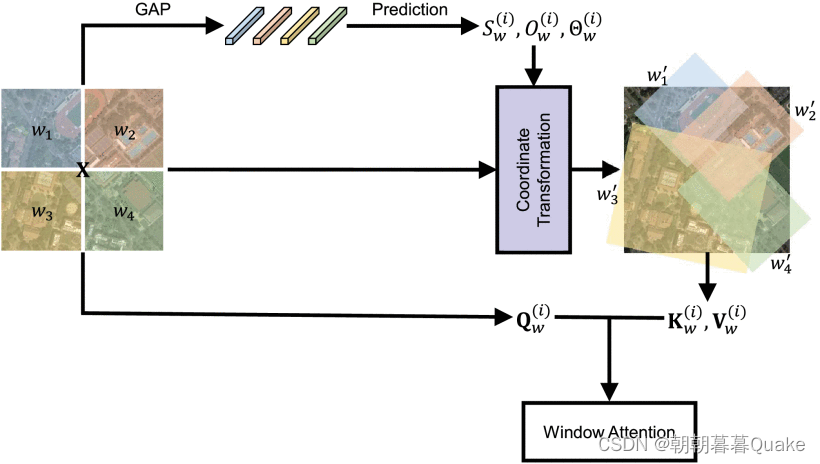
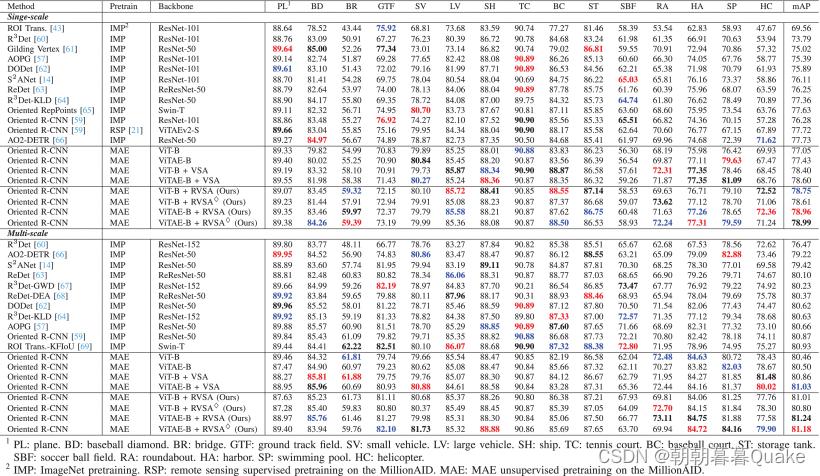
大规模视觉基础模型在自然图像的视觉任务中取得了显着进展,其中视觉变换器(ViT)由于其良好的可扩展性和表示能力而成为主要选择。 然而,遥感(RS)中的大规模模型尚未得到充分探索。 在本文中,我们采用具有约 1 亿个参数的普通 ViT,并首次尝试提出适合 RS 任务的大型视觉模型,并研究此类大型模型的性能。 为了处理RS图像中的大尺寸和任意方向的物体,我们提出了一种新的旋转可变尺寸窗口注意力来取代变压器中原来的完全注意力,这可以显着减少计算成本和内存占用,同时通过提取学习更好的对象表示 来自生成的不同窗口的丰富上下文。 检测任务的实验表明我们的模型优于所有最先进的模型,在 DOTA-V1.0 数据集上实现了 81.24% 的平均精度(mAP)。 与现有的先进方法相比,我们的模型在下游分类和分割任务上的结果也显示出具有竞争力的性能。 进一步的实验表明了我们的模型在计算复杂性和数据传输效率方面的优势。















 425
425











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









