







论文学习01:Learn to Dance with AIST++: Music Conditioned 3D Dance Generation
论文主要工作
该论文的主要贡献有两点:一是提出了一个基于Transformer的交叉模式的架构模型;二是建立了一个新的3D舞蹈数据集AIST++。
技术亮点
- 使用3个Transformer同时对于音频和3Dmotion进行transform并计算二者相关程度。
- 将平时多用于NLP的Attention Mechanism用于音频到舞蹈动作的语义转换,并使用future_N监督方式,使得动作更加连贯。
- 建立了一个新的数据集。
核心任务:Task
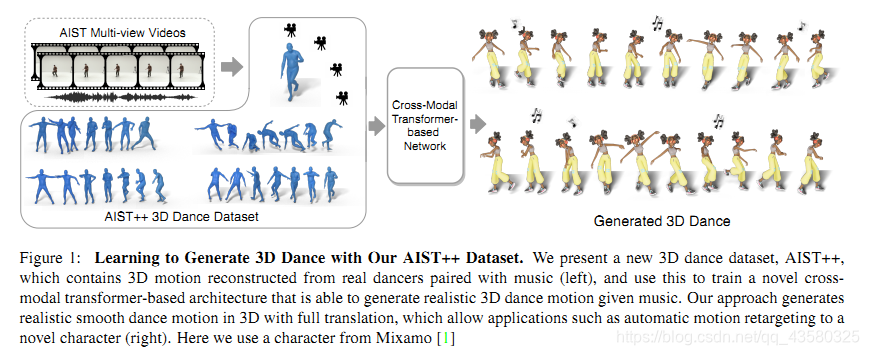
输入:AIST++ 3D 舞蹈数据集(用于训练)
网络:Cross-Modal Transformer-based Network
输出:不同人物形象随着不同音乐跳舞的3D舞蹈动作序列
效果:给出一段音乐和一个短的seed motion,通过网络可以产生较长时间的3D舞蹈动作
AIST++数据集
AIST++是一个大规模的3D人体舞蹈动作数据集,包括很多种类的3D动作以及与其配对的音乐。AIST++数据集建立在未标注的多视角舞蹈数据集AIST Dance Database的基础上,作为动作生成和预测两个任务的benchmark,其也可以潜在作为2D/3D人体姿势预测的数据集。
AIST++是目前最大的人体舞蹈数据集,共有1.1M帧3D有音乐的舞蹈动作,包括基础和高级舞蹈艺术的1408个序列,涵盖了30个人物和10个流派,视频时长约为5小时。
补充:其他舞蹈数据集
- AMASS:17.8 mins
- Dance with Melody:94 mins
- GrooveNet:23 mins
- DanceNet:1h
核心网络:Transformer-based learning framework
本文的核心网络是基于Transformer的交互模式的架构,按照功能分为两个部分:
- Deep cross-modal transformer:学习音乐和舞蹈动作之间的相关性。
- Full-attention with future-N supervision mechanism:产生长时间的流畅动作。
Deep cross-modal transformer部分
按照不同的Transformer,我们可以把网络看作以下结构:
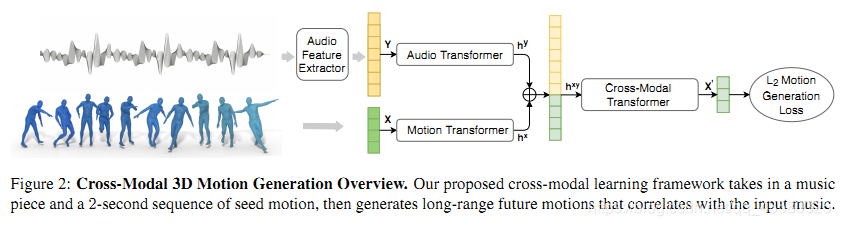
如图有三个Transformer:
- Audio Transformer
- Motion Transformer
- Cross-Modal Transformer
Full-attention with future-N supervision mechanism部分
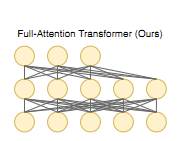
本文的所有Transformer都采用了这种Attention结构,具体的context vector C的计算如下。
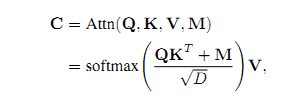
此处网络结构以及参数含义可以参考此处的
Self Attention部分,本文中没有具体阐明。
Evaluation Metrics
- Motion Quality:衡量动作质量。
- Motion Diversity:衡量模型学到的一系列动作之间的多样性。
- Motion-Music Correlation Metric:衡量模型学习到的音乐和动作的相关性。
相关工作:Baseline Method
3D Human Motion Synthesis
- kernel-based 概率分布模拟:只能提取动作细节。
- Motion Graph:姿势作为图节点、姿势之间的转换作为边,缺点是不能参数化。
- RNN:动作会僵住(freeze),并且不自然。
- Phase-functional neural networks:认为网络的weight是周期的,适用范围小。
Cross-Modal Sequence-to-Sequence Generation
交互感知多用于自然语言处理,端对端的处理不同种类的sequence,本文则是将audio到3D motion, 在该处理的过程中我们最初使用的是CNN、RNN,最近则开始使用attention mechanism。具体介绍可以戳一戳左侧链接。
Audio To Human Motion Generation
2D pose
- optimization based
- learning based
3D pose
- motion graph
- LSTMs, GANs
- RNNs or convolutional sequence-to-sequence models
- Li et al :网络架构相似、但只实现audio到motion的产生,会产生不真实的动作。

















 1097
1097

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









