









Translation Consistent Semi-Supervised Segmentation for 3D Medical Images
三维医学影像分割方法已经取得了成功,但它们对大量体素级标注数据的依赖性是一个缺点,由于获取此类标注的成本较高,因此需要加以解决。半监督学习(SSL)通过使用大量未标注数据集和少量标注数据集来训练模型,从而解决了这一问题。最成功的半监督学习(SSL)方法基于一致性学习,可最大限度地减小从未标明数据的扰动视图中获得的模型响应之间的距离。这些扰动通常会使视图之间的空间输入上下文保持相当一致,这可能会导致模型从空间输入上下文而非前景物体中学习分割模式。在本文中,引入了翻译一致性协同训练(TraCoCo),这是一种一致性学习 SSL 方法,它通过改变输入数据视图的空间输入上下文来扰动视图,从而让模型从前景物体中学习分割模式。还提出了一种新的可信区域交叉熵(CRC)损失,它能提高训练收敛性,并保持对协同训练伪标签错误的鲁棒性。方法在左心房(LA)、胰腺 CT(Pancreas)和脑肿瘤分割(BraTS19)等多个三维数据基准中取得了最先进(SOTA)的结果。方法还在二维切片基准(即自动心脏诊断挑战赛(ACDC))上取得了最佳结果,进一步证明了其有效性。
INTRODUCTION
在具有挑战性的三维医学半监督分割任务中,被分割对象很可能被以相对稳定的拓扑结构分布的 "背景 "器官所包围。例如,"左心房 "总是被 "肺静脉 "和 "二尖瓣 "包围。这些 "背景 "器官发出的强烈信号增加了 "记忆 "训练样本的风险,当输入的未标记数据在背景器官的组织结构上出现微小变化时,就会导致预测结果出现噪声。如图 1 所示,蓝色和绿色卷包含不同的背景器官,这可能导致重叠区域内的分割结果不一致,如 SASSNet (第 2 栏)和 UA-MT (第 3 栏)的分割结果所示。请注意,CAC(第 4 栏)仍然显示红色体积内的分割不一致,但与其他方法相比程度较轻。
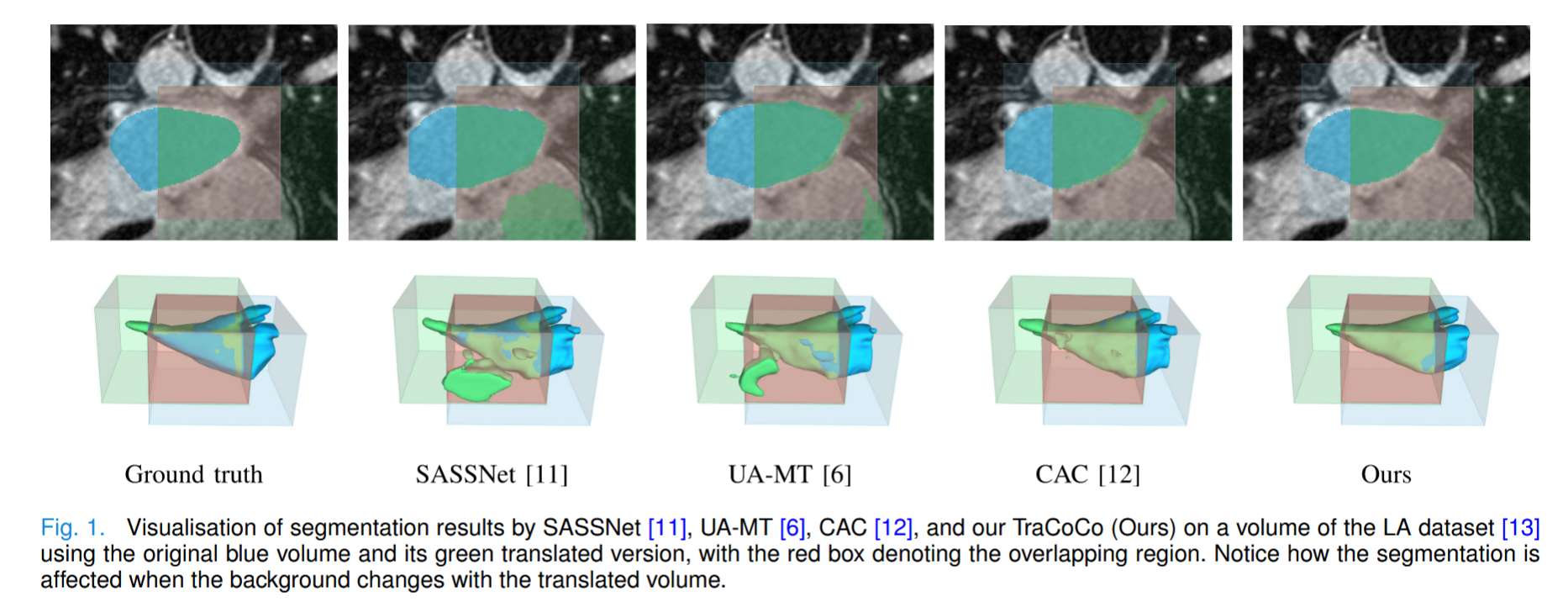
这种不一致的分割促使本文提出了翻译一致性协同训练(TraCoCo),它依赖于更有效的扰动,使方法不易受到背景模式 "记忆 "的影响。TraCoCo 采用翻译扰动来减轻 "记忆 "的影响,具体做法是强制要求交叉区域内的分割结果在包含不同背景的卷之间具有相似性。翻译扰动可以有效地限制重叠区域内的所有样本,从而实现比 CAC 更好的优化效果,而不是依赖对比学习(用于惩罚数量有限的正/负样本)和高计算成本的训练策略。这种扰动建立在协同训练网络扰动的基础上,它采用两个模型,用直接在体素空间运行的可信区域交叉熵(CRC)损失进行训练,减轻了在 CAC 中观察到的确认偏差。与图 1 所示的其他 SOTA 方法相比,所提方法得出的结果质量更高。此外,当注释训练集较小时,CutMix 对二维数据的泛化有显著改善,因此本文采用 3D-CutMix 来进一步提高整体性能。总之,本文贡献是:
-一种基于翻译一致性的新型联合训练策略,旨在通过减轻周围 "背景器官 "造成的过拟合影响来促进跨模型预测的一致性。
-一种新的基于熵的 CRC 损失,只采用最可靠的正负伪标签来共同训练两个模型,目的是提高训练的收敛性,并保持对伪标签错误的鲁棒性。
METHOD
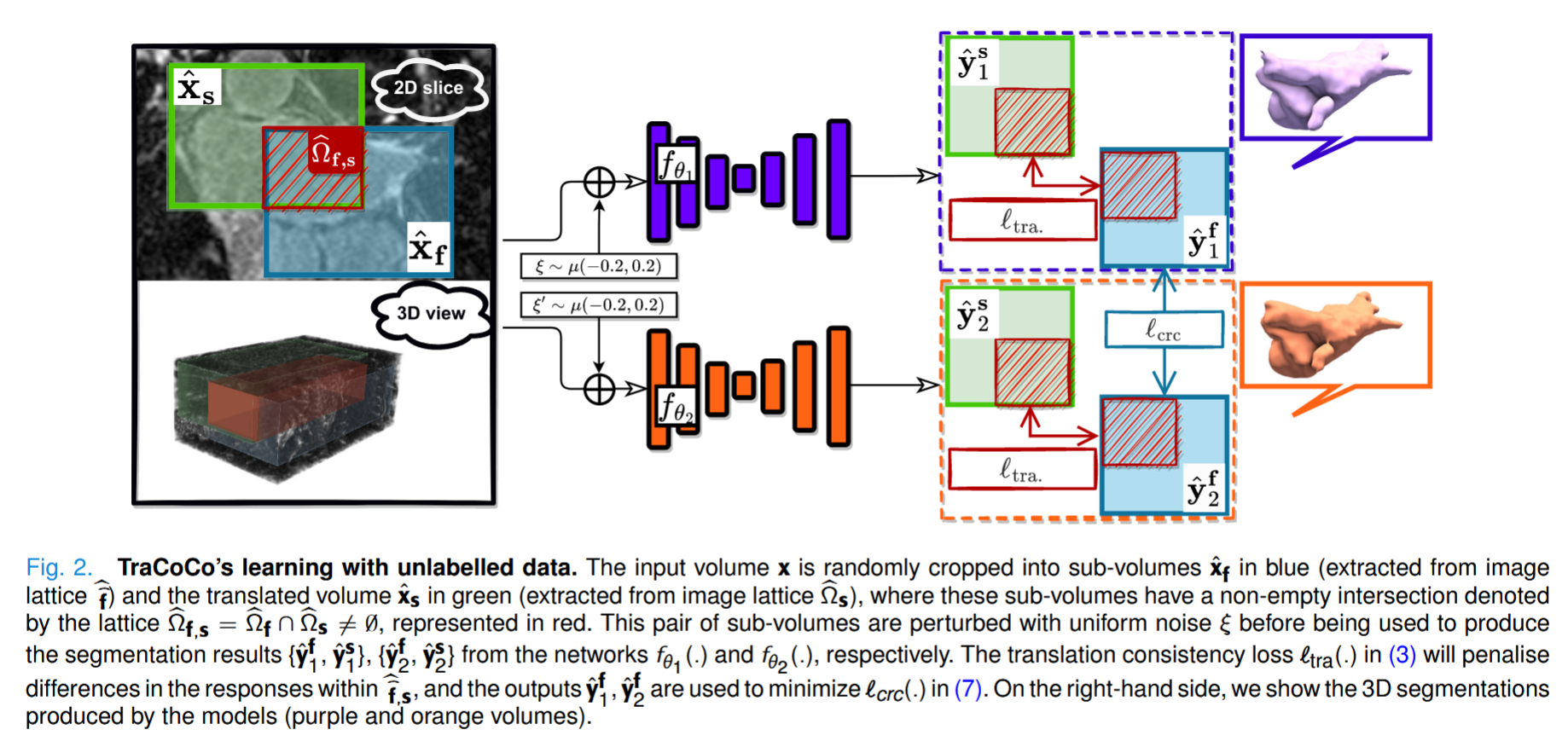
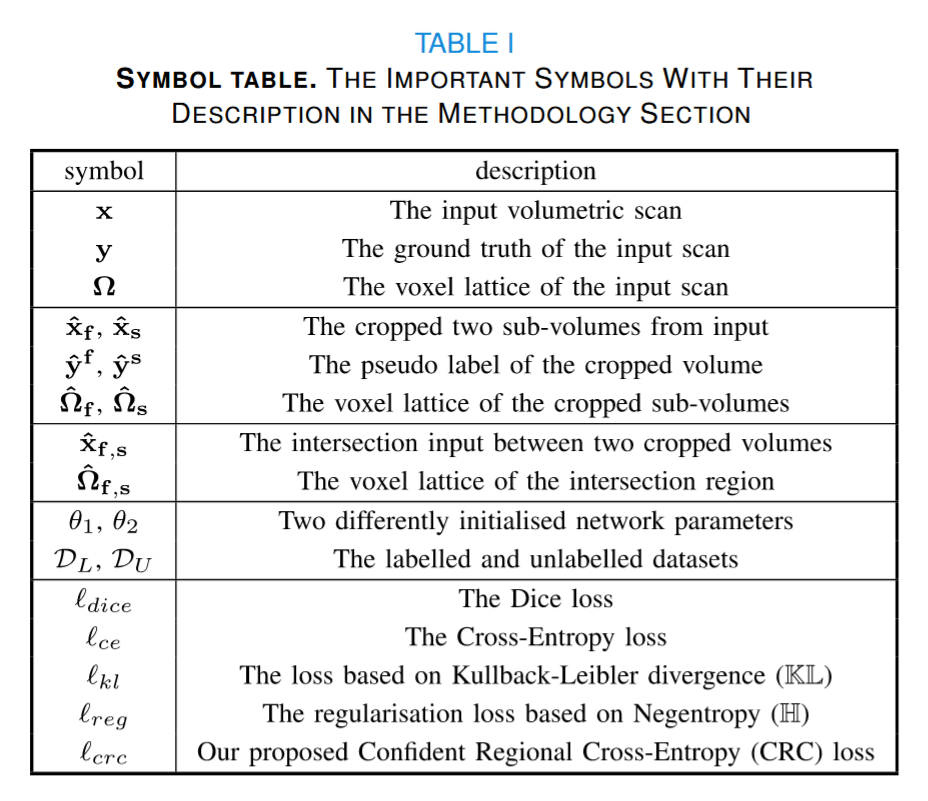
对于三维半监督语义分割,有一个小标签集 DL = {(x, y)i }|DL | i=1 |其中 x ∈ X ⊂ RH×W×C 表示输入体积,大小为 H × W,切片数为 C;y ∈ Y ⊂ {0, 1}H×W ×C×S 表示具有 S 个类别的分割基本事实,当 S = 1 时则表示二元分割。还有一个未标记的大集合 DU = {xi }。 |DU | i=1 ,其中 |DL | ≪ |DU|。如图 2 所示,所提方法是一个联合训练框架,包含两个不同的初始化网络。两个分割模型都使用输入子卷 ̂X ⊂ R ̂H× ̂W × ̂C ,其中 ̂H < H , ̂W < W , ̂C < C。这些子卷积是使用大小为 ̂H × ̂W × ̂C 且以卷积指数 f∈ N3 为中心的子网格 ̂ f ⊂ 从原始卷积网格中提取的。从体积 x 中提取的两个子体积分别为 xˆf = x(̂ f ) 和 xˆs = x(̂ s),它们的交集区域为 xˆf,s = x(̂ f ∩ ̂ s) = x(̂ f,s) 模型用 fθ :̂X → [0, 1] ̂H× ̂W × ̂C ,其中 θ1, θ2 ∈ 2 ⊂ RP 表示两个模型的 P 维参数。为了便于阅读,在表 I 中提供了符号说明。
Translation Consistent Co-Training (TraCoCo)
建议的翻译一致性联合训练(TraCoCo)优化基于以下损失函数最小化:
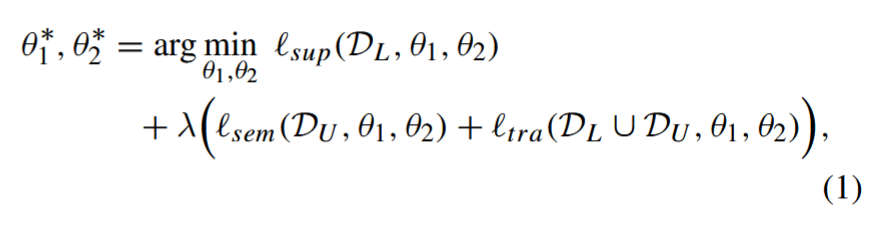
其中,监督学习损失的定义是:
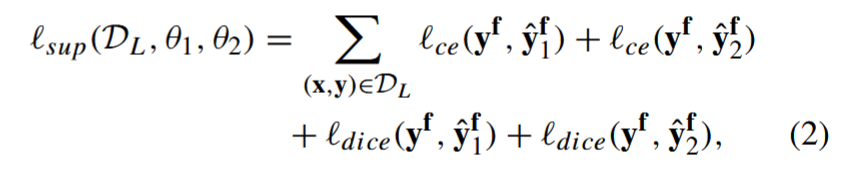
其中 lce(.) 表示体素方向的交叉熵损失,ldice(.) 表示体积方向的线性化 Dice 损失,yˆf 1= fθ1 (xˆf + ξ ) (yˆf 2 类似,ξ ∼ μ(-0. 2, 0.2) 表示在 [-0.2, 0.2] 范围内的均匀分布样本),yf = y(̂ f ) 表示子体积标签。2, 0.2) 表示在 [-0.2, 0.2] 范围内均匀分布的样本),yf = y(̂ f ) 表示子卷标签。同样在 (1) 中,lsem(.)(定义见下文 (6))表示使用两个模型的伪标签的半监督损失,ltra(.)(定义见下文 (3))表示翻译一致性损失,它强制两个随机裁剪的子区域的分割之间的跨模型一致性。
1) 翻译一致性损失:取训练体积 x ∈ DL ∪ DU,并提取以 f、s ∈ N3 为中心的两个子体积,其中 f ̸= s,用 xˆf 和 xˆs 表示,它们各自的网格有一个非空交集,即̂ f,s = ̂ f ∩ ̂ s ̸= ∅。根据 (1) 提出的翻译一致性损失定义为:
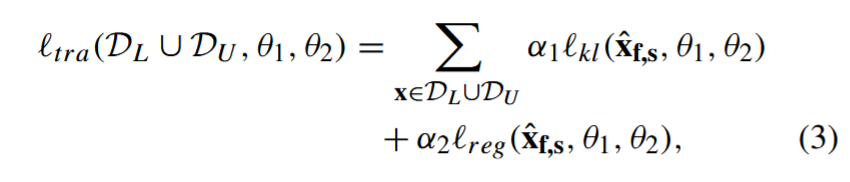
其中,以 f、s 表示的两个子体积的中心是从原始体积网格中均匀采样的,α1 和 α2 是平衡两个损失函数的超参数(实验中,α1 = 1.0,α2 = 0.1):
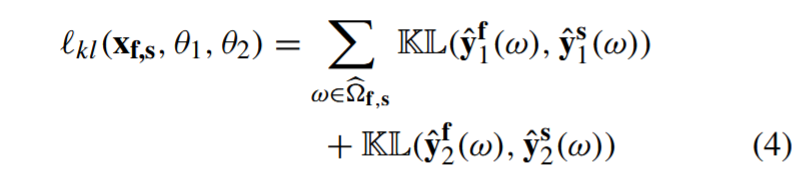
算̂ f,s 所代表的两个翻译输入子卷的交叉区域内两个模型的分割输出之间的(KL)分歧,yˆf 1、yˆs 1、yˆf 2 和 yˆs 2 定义于 (2)。在 (3) 中:
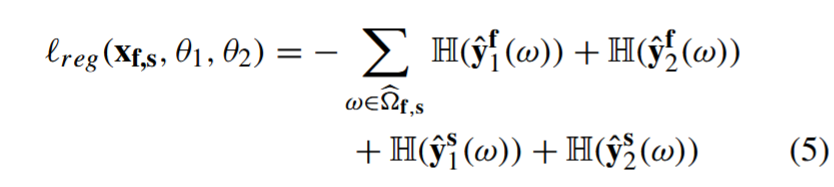
旨在平衡训练体素中的前景和背景类别、其中 H(.) 代表香农熵。
2) 自信区域交叉熵(CRC)损失:(1)中的半监督损失 lsem(.) 可以加强两个模型分割结果的一致性,如下所示:
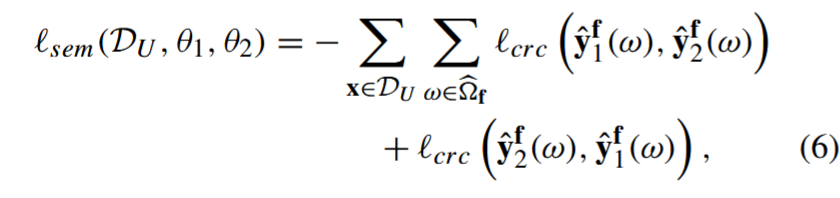
其中,yˆf 1(ω) ∈ [0, 1]2 表示根据模型 1 的 softmax 激活函数得到的体素 ω∈ ̂ f 中的背景(yˆf 1(ω)[0])和前景(yˆf 1(ω)[1])分割概率(模型 2 类似)、
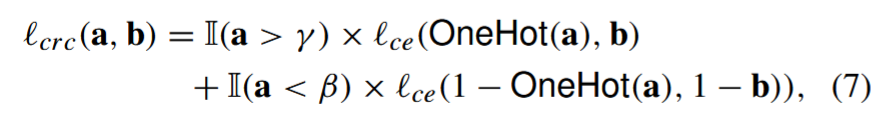

a, b 是体素 ω 分支的输出概率分布,γ , β 代表用于平衡前景和背景损失的超参数。请注意,提出的 lcrc(.) 取代了半监督学习方法中更常用的 MSE 损失,目标是保持 MSE 对伪标签错误的鲁棒性,并提高训练收敛性。特别是在(7)中,通过第一个模型选择有把握分类的前景体素和背景体素来训练第二个模型的正负交叉熵损失,反之亦然。
3D CutMix
为了提高训练的通用性,采用了 3D CutMix。具体方法是随机生成一个三维二进制掩码 m∈{0, 1} H ̃ ×W ̃ ×C ̃ ,其中包含一个在零背景中的一方框,方框的位置和大小是随机定义的,H ̃ 、W ̃ 和 C ̃ 代表掩码大小,H ̃ < H ,W ̃ < W ,C ̃ < C。因此,将二进制掩码应用于无标签数据和第二个模型的伪标签(即θ2):
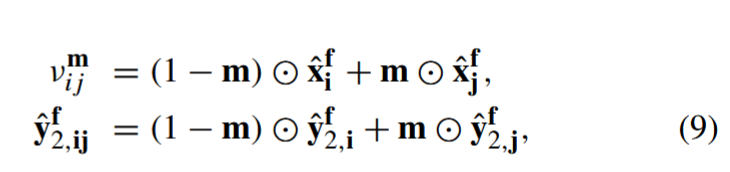
其中,i, j 表示来自同一迷你批次的不同案例,i ̸= j。 为了考虑 3D CutMix,重新定义了 (6) 中的半监督损失,即:
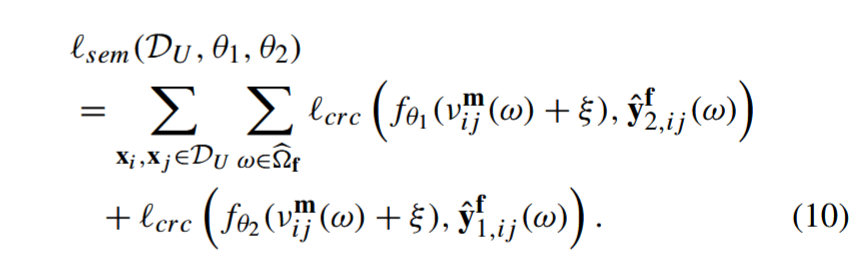




















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











