







Semi-Supervised Semantic Segmentation Based on Pseudo-Labels: A Survey
摘要:
语义分割是计算机视觉领域的一个重要而热门的研究领域,其重点是根据图像中像素的语义对其进行分类。然而,有监督的深度学习需要大量数据来训练模型,而逐个像素标记图像的过程耗时费力。本综述旨在首次全面、有序地概述半监督语义分割领域中伪标签方法的最新研究成果,我们从不同角度对其进行了分类,并介绍了针对特定应用领域的具体方法。此外,我们还探讨了伪标签技术在医疗和遥感图像分割中的应用。最后,我们还针对现有挑战提出了一些可行的未来研究方向。
Introduction:
语义分割是计算机视觉领域对图像中每个像素进行分类的一个重要且广受关注的研究领域,在医疗图像分割[Li 等人,2023a]和遥感图像分割[Wang 等人,2022a]等特定领域有着广泛的应用。过去几年中,许多研究在提高语义分割任务的有效性方面取得了重大进展。然而,有监督的深度学习需要大量数据来训练模型,而且逐像素标注图像的过程耗时耗力。有研究指出,仅对城市景观数据集中的一张精细标注图像进行标注就需要数小时[Cordts 等人,2016]。由于训练标签的成本,完全监督模型的性能可能无法得到显著提高。近来,通过大量相关研究,半监督学习已被应用于语义分割。
伪标签法是半监督学习领域的一种著名技术,最早出现在[Lee 等人,2013]中,并在最近的计算机视觉研究中得到普及,包括领域适应[Li 等人,2023b]、语义分割[Wu 等人,2023]等,因其简单易行和令人印象深刻的性能而受到青睐。
该过程如图 1 所示。在语义分割中,伪标签方法被认为是比一致正则化更可靠的选择,因为一致正则化可能会受到不同程度的数据增强的影响。伪标注技术以其稳定性、可解释性和易于实施而著称,使其成为一个具有越来越大潜力的研究领域。
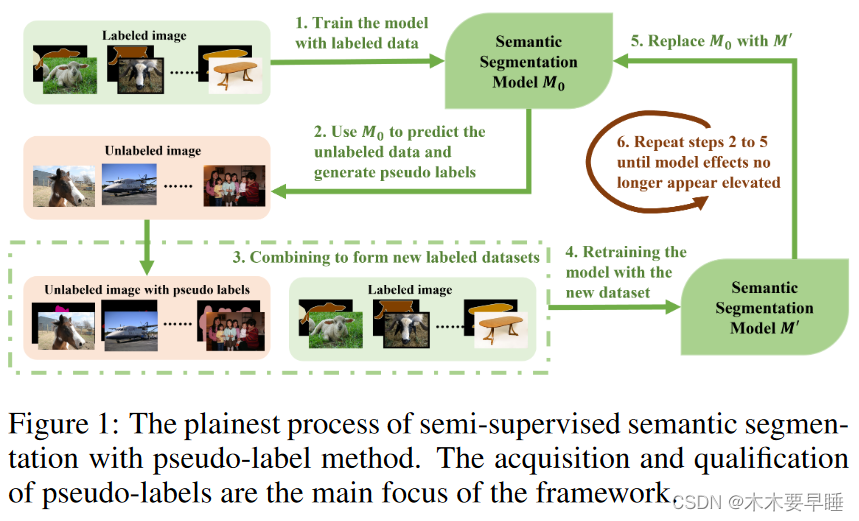
关于伪标签法在半监督领域的应用,已经开展了大量研究。然而,目前的一项调查[Pel ́ aez-Vegas et al., 2023]仅仅对半监督语义分割技术进行了系统分类,缺乏对伪标签方法的详细总结和分析。这一不足促使我们展开调查。
我们调查的主要目的是对最近的研究进行全面而有条理的总结,根据不同的视角对研究进行分类,并针对特定的应用领域介绍具体的方法。我们的主要贡献如下1.在本文中,我们全面回顾了用于半监督语义分割的伪标签方法的最新进展。2.2. 具体来说,我们研究了伪标签方法的三个关键方面,包括模型结构设计、伪标签细化和优化技术。3.3. 此外,我们还讨论了该领域需要关注的现有挑战,并提出了未来研究的潜在方向。
前期准备和问题提出:
Problem Definition:
在半监督语义分割的背景下,目标是通过同时考虑有标签和无标签数据集来最小化损失。标注数据集表示为 Dl = {(xl, yl)}p ,由带有相应标签的 p 个样本组成。未标记数据集表示为 Du = {xu}q,由 q 幅图像组成,其中 q 比 p 大很多:Ll 表示标记数据集上的损失,Lu 表示未标记数据集上的损失。
![]()
其中,λ 代表一个平衡权衡的超参数。这个超参数既可以事先分配一个固定值,也可以在训练过程中进行自适应调整。有监督损失 Ll 通常是指预测输出与相应 yl 之间计算的交叉熵损失,而无监督损失 Lu 可以有多种形式,取决于所使用的具体方法。
最简单的伪标签方法是首先,我们使用交叉熵损失 Ll 在标注数据集 Dl 上训练初始模型 M0。这个训练过程会生成一个伪标签数据集 ̃ Du = {(xu, M0(xu))}q ,其中 M0(xu) 代表 xu 的伪标签。接下来,我们将标签数据集 Dl 与伪标签数据集 ̃ Du 结合起来,形成一个综合数据集 D = (Dl ∪ ̃ Du)。最后,我们使用完整的数据集 D 训练一个新的模型 M。上述简单明了的过程可以反复进行,以不断提高生成的伪标签的质量。
由于意外的分布差距和预训练模型的不理想表现,伪标签的生成、选择和改进会对这一过程产生重大影响。
Datasets:
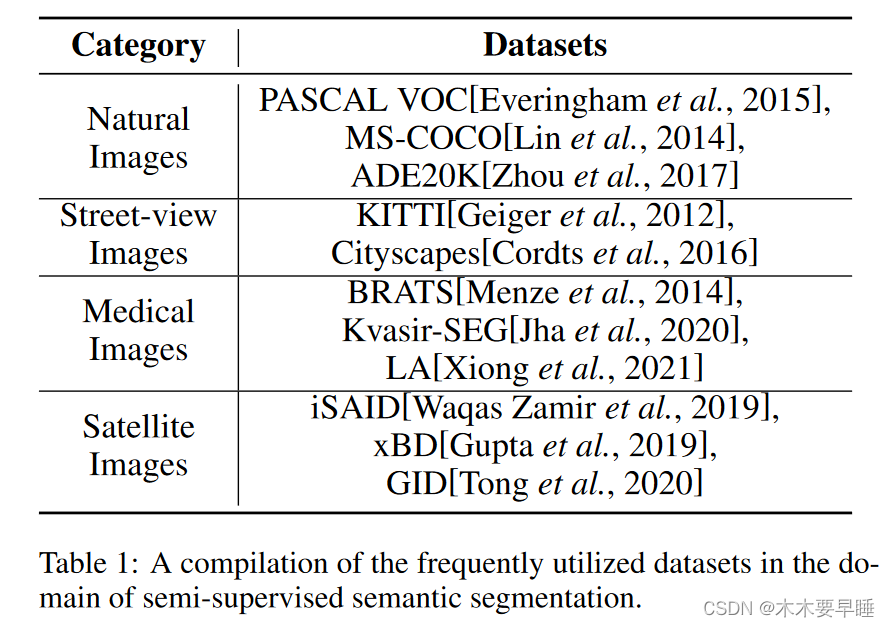
表 1 概述了几种常用的数据集,这些数据集在各种场景中都有应用。通常情况下,这些完全注释的图像会被部分选中用于半监督学习,比例为 5%、10% 等。
Performance Metrics:
像素准确度:计算的是正确分类的像素占像素总数的比例。虽然这一指标简单直观,但当分类不平衡时,它可能无法准确反映模型的性能。
平均精度:考虑了每个类别的像素精度,并计算出平均值,以解决类别不平衡的问题。
平均 IoU :计算所有类别的预测值与地面实况之间的平均交叉值(mIoU)
加权 IoU :是对 mIoU 指标的一种修改,用于需要更加重视某些类别的情况。
Categorization:
借鉴以往研究中对伪标签法网络结构的分类[Pel ́ aez-Vegas et al., 2023],以及研究人员对平均教师结构提出的创新性细化[Tarvainen and Valpola, 2017],我们的研究将主要集中在三个方面:基于模型的视角、伪标签细化和优化措施。图 2 全面展示了各类伪标签技术。
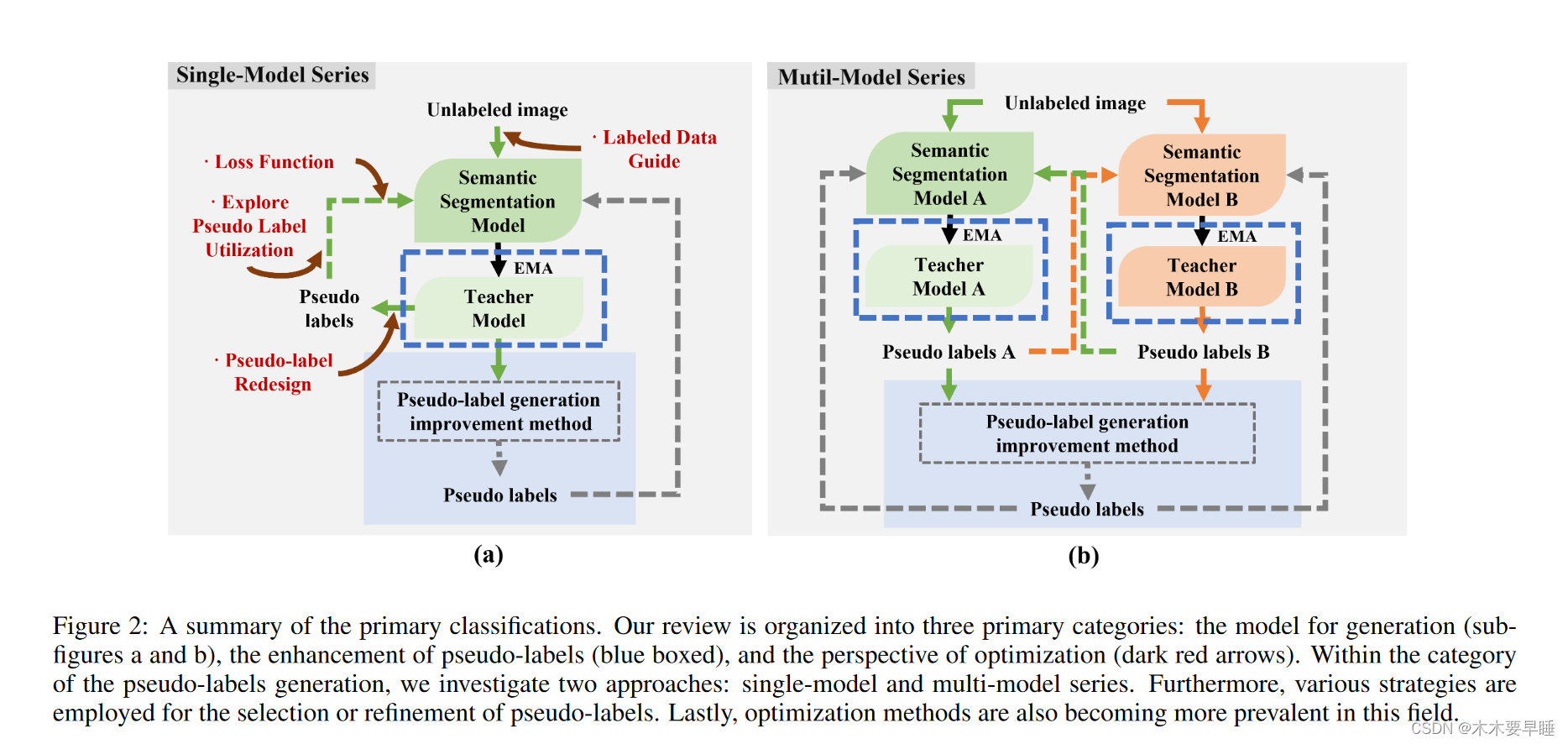
模型视角。从本质上讲,生成伪标签的各种方法可分为两类:单模型系列和互模型系列。图 2 (a) 展示了基于单一模型的方法,即使用单一模型生成的伪标签进行有监督的后续训练。例如,在 MeanTeacher 方法中,使用教师模型生成的伪标签对单一模型进行训练,其中包含一致性正则化。另一方面,基于多模型相互训练的方法旨在通过联合训练多个模型来提高模型性能。图 2 (b) 描述了这种方法,其中初始化了两个不同的网络,一个模型通过在未标记数据上提供伪标签来监督另一个模型的训练。两个模型的交叉监督有助于定位和最小化伪标签中的误差。
完善伪标签。我们将讨论对传统架构的改进,重点是完善伪标签以生成特定标签。此外,我们还将根据伪标签是否发生变化,将这些提炼伪标签的方法分为两类:标签更新和仅过滤。图 2(a)和(b)的蓝色区域描述了伪标签精炼的简化架构。
优化。最后,我们还研究了一些新出现的优化技术,图 2 (a) 中用暗红色表示了这些技术。下文将进一步阐述这些方法。
用于半监督语义分割的伪标签:
Model perspective:
架构在深度学习中的重要性怎么强调都不为过,因为它确立了这些模型所采用的神经网络的框架和布局。架构在决定网络如何处理和分析输入特征方面起着至关重要的作用,从而影响模型学习和生成精确预测的能力。选择合适的架构是构建成功深度学习模型的一个重要方面。在本小节中,我们将研究与单模型族和协作互模族相关的论文。
基于单一模型的方法 单一模型自我训练方法的最初提议是由 Yarowsky 提出的[Yarowsky, 1995]。后来,[Lee and others, 2013]建议使用伪标签将自我训练与神经网络结合起来。由于最初的单一模型自我训练方法简单明了,随后的研究主要集中在增强这种网络结构的不同方面。
自我训练迭代。GIST和RIST[Teh等人,2022],可解释为一种贪婪算法策略(GIST)和一种基于跟随迭代自我训练策略(RIST),在地面实况和伪标签之间交替使用。另一种从自我训练迭代角度提出的方法是 ST++ [Yang 等人,2022 年],其关键步骤是在迭代过程中进行选择性再训练。由于分割性能与监督训练阶段生成的伪标签的进化稳定性呈正相关,因此可以在训练过程中通过进化选择更可靠的未标记图像。稳定性指标基于每个早期伪掩码与最终掩码之间的平均 IOU.
然后获得所有未标记图像的稳定性分数,并对整个未标记集进行相应的排序,选择分数最高的 R 幅图像进行第一阶段的再训练。ST++ 根据可靠性的渐近变化预测鲁棒性,因此无需手动选择逐像素过滤的置信度阈值。
自交叉监督。[Zhang等人,2022年]提出了一种用于半监督语义分割的方法,称为不确定性引导的自交叉监督(USCS)。这种方法利用多输入多输出(MIMO)分割模型的结果来执行自交叉监督,从而显著降低了参数和计算成本。
辅助任务框架。由于伪标签方法的另一个关键是建立辅助任务框架监督,因此有人从这个角度提出了一些方法。早些时候,[Li and Zheng, 2021]引入了残差网络来扩展自训练结构。标记数据被输入辅助残差网络,以预测原始分割结果的残差。而后来提出的 ELN [Kwon and Kwak, 2022] 则主要用于辅助定位错误、具体的 ELN 结构包括主分割网络(编码器和解码器)和辅助解码器(D1、D2、...、DK)。主分割网络通过标准交叉熵损失进行训练,而辅助解码器则通过受限交叉熵损失进行训练:
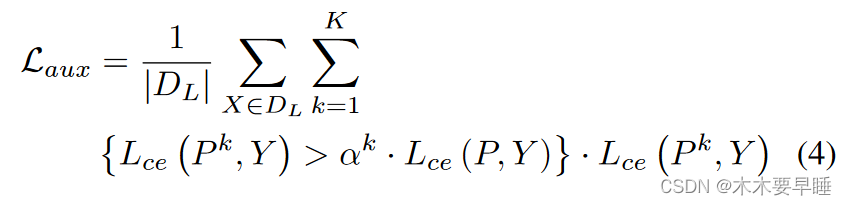
因此,辅助解码器的性能会比主解码器差很多,因为它包含各种错误,然后将这些错误作为 ELN 的输入,训练 ELN 定位标签错误,类似于手动创建一些错误数据进行训练。EPS++[Lee等人,2023]通过显著性检测模型生成的显著性地图提供丰富的边界信息,并将其与图像级标签信息结合起来进行联合训练,帮助模型从像素级反馈中得到训练。因此,辅助解码器的性能会比主解码器差很多,因为它包含各种错误,然后将这些错误作为 ELN 的输入,训练 ELN 定位标签错误,类似于手动创建一些错误数据进行训练。EPS++[Lee等人,2023]通过显著性检测模型生成的显著性地图提供丰富的边界信息,并将其与图像级标签信息结合起来进行联合训练,帮助模型从像素级反馈中得到训练。
Mutil-model-based Methods:
有几种半监督学习方法依赖于伪监督,特别是生成伪标签的自我训练方法。然而,在自我训练中,单个模型生成的伪标签往往不可靠。这是因为通常只使用单个模型的预测置信度来过滤低置信度的伪标签,这可能会留下高置信度的错误,并浪费许多低置信度的正确标签。双模型相互训练法针对单模型自我训练法存在的固有问题,即单一模型无法检测和纠正自身错误,可能导致偏差积累,最终影响训练和分割效果,提出了两个或多个模型根据差异相互训练、定位错误并相互纠正的相互训练法[Zhang 等,2018]、
交叉伪监督。经典的交叉训练视角是双模型交叉监督,如 CPS [Chen 等人,2021] 方法为两个网络使用不同的初始化方法,其中一个网络输出的伪标签监督另一个分割网络。随后提出的 n-CPS [Filipiak 等人,2021] 是将 CPS 扩展到 n 个子网络的结果,实验证明网络整合能显著提高性能。在交叉监督的基础上,[Fan 等,2022] 引入了不确定性引导监督,并提出了 UCC(不确定性引导交叉头协同训练),通过共享编码器进一步提高了泛化能力。[Wang 等人,2023 年]设计了一种基于冲突的交叉尝试一致性(CCVC),强制两个子网从不相干的视图中学习知识。他们提出了一种新的跨视图一致性策略,鼓励结构相似但不共享参数的两个子网从同一输入图像中学习不同的特征。为此,他们引入了特征差异损失。对于无标签数据,他们让两个子网使用彼此的伪标签进行模型学习。
动态互训。除了同步训练的交叉监督,其他研究者还提出了基于双网络结构的动态互训,即两个网络异步训练。DMT [Feng 等人,2022] 指出,单一模型很难克服自身的错误。因此,他们使用两个具有不同初始化的模型,其中一个模型为另一个模型生成离线伪标签。要有效地训练机器学习模型,识别标签错误非常重要。为此,他们比较了两个不同模型的预测结果,并量化了它们之间的差异,以便在训练过程中动态调整权重损失,提高模型的准确性。动态损失权重 ωu 的定义如下:
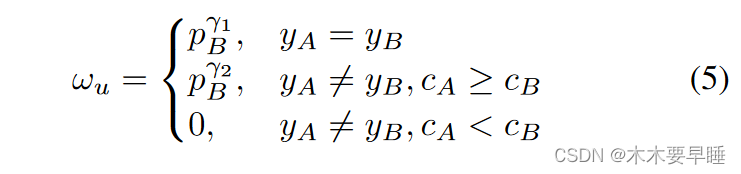
关于伪标签技术中的噪声问题,DMT 方法建议给样本分配不同的权重,而不是丢弃它们。这种方法旨在保留低置信度数据,但可能无法有效解决伪标签方法中的高噪声率问题。此外,神经网络中的 "灾难性遗忘问题 "也无法完全解决,因为这些网络的基本组件由固定的结构和参数组成。不过,可以通过各种缓解技术降低这一问题的严重性。DMT-PLE[Zhou等人,2022]方法扩展了之前DMT方法中的伪标签增强策略,主要用于上述目的。他们提到,在处理多个不同类型像素的输入时,模型要想保留所学知识具有挑战性。为了防止模型偏向于最后学习到的类别,他们使用了一种名为伪标签增强(PLE)的策略。这种技术利用模型在前一阶段生成的伪标签来完善当前模型生成的伪标签。
Pseudo-label Refinement Methods:
伪标签更新方法:
伪标签法有时会导致错误的预测或不准确的伪标签被纳入训练过程,从而积累误差,使学习到的伪标签无法有效指导后续学习,最终影响分割模型的训练结果。为了解决这个问题,一些研究提出了更新伪标签的方法来缓解噪声问题,并取得了良好的效果。
伪标签修正。最初,一些研究将这一任务表述为像素级标签噪声的学习问题。Yi 等人[2021]提出了一种基于图的标签噪声检测和校正框架,该框架利用类激活图(CAM)生成的像素级标签作为弱注释噪声标签,训练强注释分割模型从上述噪声标签中检测出干净标签,然后使用干净标签监督图注意力(GAT)网络校正噪声标签。然后再使用干净标签监督图注意力网络修正噪声标签。同样,为了解决噪声标签校正问题,[Wang 等人,2022b] 提出了一种与类别无关的关系网络,根据图像特征之间可靠的语义关联来校正标签。他们通过增强特征之间的关系来获得关系估计。为了有效地进行噪声标签校正,他们舍弃了相关性较弱的预测。
与上述方法的观点不同,一些改进方法是从训练阶段开始的。Ke 等人[2022]提出了一种三阶段自我训练(ThreeStageSelftraining)方法,他们试图通过三个阶段的自我训练来提取未标记数据的初始伪标签信息,同时以多任务的方式强制分割一致性,以生成更高质量的伪标签。除了上述传统的补救措施外,[Wu 等人,2023] 考虑到同类样本具有较高的像素级对应关系,提出了利用标记图像修正噪声伪标签的 CISC-R 方法。受 ST++ [Yang 等人,2022] 的启发,他们使用了一种基于 CISC 的图像选择方法,该方法考虑到了类间特征差异和训练初期纠正噪声伪标签的难度。首先,对于每个类别 k,使用初始模型从标签图像集中提取该类别的锚向量 ak l:
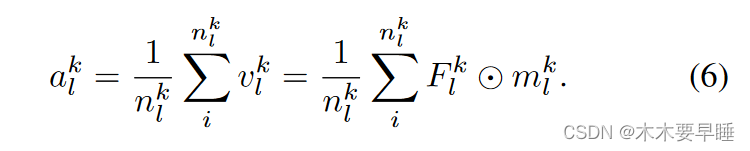
通过这种平均值生成方式,ak l 被生成来代表标签图像的分类锚点。具体来说,CISC 映射 m′ 是通过标签图像 x 的 ak l 与高级特征之间的余弦相似度生成的。
去偏差 训练中的偏差既来自于网络本身,也来自于对潜在错误伪标签的不当训练,这些错误会在迭代过程中不断累积。[He 等人,2021 年]提出了分布式对齐和随机抽样(DARS),这是一种简单有效的方法,可以重新分配有偏差的伪标签,使伪标签与地面真实情况保持一致,并改善噪声标签对训练的影响。将伪标签的分布与真实分布对齐可以改善半监督语义分割。随后,为了最小化偏差,Chen 等人[2022] 提出了去偏自我训练(DST)方法。该方法的关键在于两个参数无关的分类器头将伪标签的生成和使用过程解耦,只使用干净的标签进行训练,从而提高了伪标签的质量。
Pseudo-label Filtering-only Methonds:
此外,还有一些研究者提出通过过滤噪声伪标签来增强分割效果,但这类方法并不对噪声标签进行更新。
置信度过滤。Zhou 等人[2021] 提出的 C3SemiSeg 提出了一种动态置信度区域选择策略,重点选择高置信度区域进行损失计算。此外,还集成了跨集对比学习来改进特征表示。然而,针对现有的基于高置信度的伪标签方法会丢失大部分信息的问题,Ju 等人[2023] 提出了一种用于半监督语义分割的类自适应半监督框架(CAFS),它允许在标签数据集上构建验证集,以利用每个类的校准性能。这包括一个核心操作:自适应逐类置信阈值(ACT),它不再强调使用校准分数来自适应调整可靠性置信阈值。最近,TorchSemiSeg2[Chen 等人,2023] 引入了局部伪标签过滤模块,利用判别器网络评估区域级伪标签的可靠性。他们还提出了一种动态区域损失校正方法,利用网络多样性进一步评估伪标签的可靠性,并评估网络的收敛方向。
置信度细化。由于上文提到的大部分前人工作都是基于置信度阈值来评估伪标签数据,因此训练初期存在的置信度模糊问题可能会在很大程度上限制后续的更新。最近,Kong 等人提出了 PGCL [2023],旨在解决网络修剪中的模糊置信度分数问题,其方法是采用粗略策略,从易到难逐步教授网络。
辅助网络过滤。此外,一些方法还利用辅助结构进行过滤操作。例如,GTA-Seg[Jin 等人,2022] 选择了一种称为 "温柔教学助手"(gentle Teaching Assistant)的辅助结构。GTA 直接从教师网络生成的伪标签中学习,只有经过过滤的有利信息才会传递给学生网络,以协助监督学生网络的训练。
Optimization Methods:
损失函数。Wang 等人[2022c]建议通过感知交叉熵(CCE)和渐进交叉训练(PCT)提高伪标签的质量。CCE 比传统的交叉熵更能简化伪标签的生成。PCT 逐步引入高质量预测,作为网络训练的额外监督。PS-MT[Liu等人,2022]使用更严格的置信度加权交叉熵(Conf-CE)来解决交叉熵损失训练容易造成预测误差过拟合的问题。
标签数据的利用。值得注意的是,[Tu 等人,2022] 认为分别处理有标签数据和无标签数据通常会导致丢弃大量从有标签示例中学到的先验知识。因此,他们提出了一种名为 GuidedMix-Net 的方法,通过使用标签信息来指导未标签示例的学习,从而学习到更高质量的伪标签。同样,我们前面提到的 CISCR[Wu等人,2023]也是通过估计未标记图像与查询标记图像之间的像素相似度并生成CISC图,从而对伪标签进行像素级校正。
伪标签利用。Zou 等人[2020] 重点研究了伪标签的结构化和定性设计方法,并提出了单阶段一致性训练框架 PseudoSeg,该框架从两个分支生成伪标签:分割模型的输出和类激活图(CAM)的输出。他们提出了一种伪标签再设计策略,通过校准融合策略将两个来源的伪标签结合起来,即给定一批解码器输出 ˆ p = fθ(ω(x)) 和基于弱增强数据 w(x) 计算的 SGC 映射,生成伪标签 ̃ y
医学图像分割
医学图像分割涉及识别 CT 或核磁共振成像等图像中与器官或病变相对应的像素,由于缺乏足够的标签,这是医学图像分析中一项非常困难的任务。许多研究都提出了使用伪标签的方法,并在应用于特定医学数据集时取得了可喜的成果。在最近的工作中,[Huo 等人,2021] 引入了一种名为异步师生优化(ATSO)的新方法来挑战传统的学习策略。他们建议将未标记的训练数据分为两个子集,而不是交替训练两个模型。这种方法尤其适用于三维医学图像,其中每个三维人体被分为代表冠状切面、矢状切面和轴向切面的二维切片。然后使用二维网络进行分割,并将得到的输出叠加形成三维人体。半监督医学影像分割的一个常见问题是标记数据与非标记数据的分布差异。之前的研究主要是孤立地或不一致地处理已标记数据和未标记数据,这可能会导致忽略从已标记数据中获得的知识。在他们的研究中,[Bai 等人,2023] 提出了一种直接的方法来缓解这一问题,即使用一种称为 BCP 的平均-教师模型,双向纳入已标记和未标记数据。
挑战与未来展望:
经过深入研究,伪标签技术显然已涉足图像分割的各种技术领域,并取得了显著成果。不过,本节将集中讨论半监督语义分割中伪标签方法遇到的困难,并强调潜在的研究方向。
利用基础模型提高质量。基础模型改变了人工智能,为著名的聊天机器人和生成式人工智能提供了动力。最近,一种基于交互提示的前沿模型--Segment Anything Model(SAM)[Kirillov 等人,2023] 被集成到语义分割任务中。预计未来将利用 SAM 的提示功能进一步提高伪标签的效率和效果。
利用附加信息。目前,低质量伪标签的使用仅限于单一类型的监督信号,忽略了其他像素中存在的有价值信息。因此,我们有机会将其他形式的监督信号整合到模型中,增强其有效利用粗标和细标数据的能力。我们预计,未来的研究将通过采用更全面的监督方法来提高分割性能。
参与主动选择并完善流程。伪标签技术难以有效解决噪声数据问题。主动学习等策略不是在整个数据集上训练模型,而是选择信息量最大的数据点子集来查询附加标签。这种方法效率更高、成本效益更高,因为它允许模型从信息量最大的示例中学习,而不需要对整个数据集进行标注。如果能加入主动选择和细化策略,未来的前景将十分广阔。
探索复杂的分割场景。将伪标签模型的应用扩展到更广泛的真实世界中是至关重要的。虽然理论研究取得了显著进展,但目前伪标签方法的应用仅限于特定数据集,如 PASCAL VOC 2012 [2015],其中仅包含 20 个常见类别。为了推动这一领域的发展,研究更能代表现实生活场景的数据集至关重要。例如,ADE20K [Zhou 等人,2017] 包含 150 多个类别的对象信息,可以作为未来探索的更具代表性的数据集。



















 1300
1300

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











