







DSAC – Differentiable RANSAC for Camera Localization && CVPR 2017
RANSAC(随机抽样一致性)是一种用于估计模型参数的迭代算法,其能够处理存在异常值(outliers)的数据,并被广泛用于计算机视觉、图像处理、几何计算等领域。
现有问题 & 本文贡献
问题:现有的基于RANSAC的相机位姿预测方法都没有能够端到端训练的。
贡献:
-
本文提出了两种不同的使RANSAC可微的替代方法,其中效果较好的一种叫做DSAC(Differentiable Sample Consensus)。
-
我们将两种选项放入一个新的端到端可训练的相机定位流水线中。它包含两个分别由我们的新 RANSAC 连接的 CNN。
-
我们通过实验证明,概率选择选项更优秀,即对过拟合的敏感性更低,适用于我们的应用。我们推测,概率选择的优点在于允许进行硬决策,同时保持对可能决策的广泛分布。
-
我们的相机定位结果超过了现有技术水平 3.3%。
论文方法
作者基于场景坐标回归森林(SCoRF)的方法 ,使用深度神经网络和DSAC对其改造,论证了DSAC的效果
"Scene coordinate regression forests for cam-era relocalization in rgb-d images"提出了回归森林方法,用于获得三维坐标预测

-
首先使用W网络对输入图像进行预测,得到每一个像素点的三维坐标预测值(correspondences)。
-
每个最小坐标子集包含4个correspondences(通过随机采样获得),通过PNP算法每个最小坐标子集可以得到一个模型假设。通过这种方法得到一个假设集。
-
使用基于重投影误差的标量函数S对每个假设模型打分
-
选择得分最高的一个假设模型h,使用剩余的correspondences对该最佳假设模型进行优化。
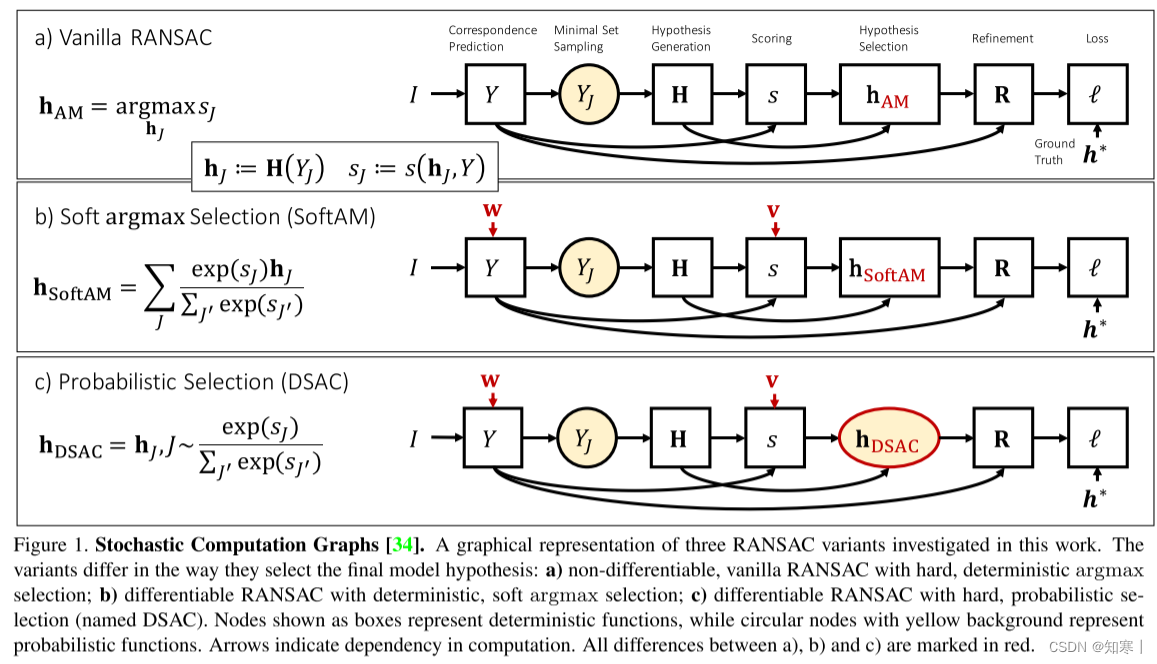
下图说明了基础的RANSAC(不可微)、基于softmax的RANSAC(可微)、DSAC三种方法的异同:
Learning Less is More – 6D Camera Localization via 3D Surface Regression 2018 CVPR
针对领域:自动驾驶、增强现实等
本文基于DSAC模型,提出了DSAC++ 。证明了相比于学习相机定位pipeline的所有组件,只学习其中的一种会更加高效。DSAC++就是这样一个将可学习的组件结合到定位pipeline中,组成的端到端学习系统。
DSAC存在的问题:
-
对位姿假说进行评分的CNN模块很容易过拟合。例如,CNN可能会专注于图像中出现误差的位置,而不是去学习评估误差的质量。然而出现误差的位置不能在不同场景之间是不同的,因而不能够被泛化
-
初始化pipeline需要RGB-D训练数据,或者是3D模型。这些数据较难获取。
-
DSAC中姿态细化通过有限查分得到,不稳定的数值会导致非常大的梯度方差
针对以上问题,DSAC++ 使用了soft inliner count 取代原来的评分CNN,对位姿假设进行评分,防止了过拟合问题。
实验证明,DSAC++在不依赖3D模型的情况下依然可以精确估计相机位姿。
*论文方法:*
DSAC使用CNN进行场景坐标回归,DSAC++使用全卷积网络(FCN),使得能在更短的时间内回归更多的场景坐标。
*三步训练*:
-
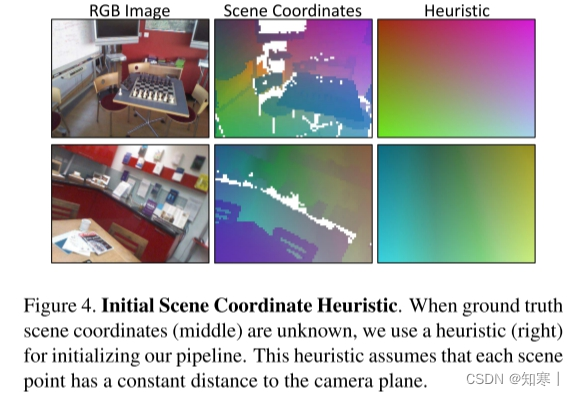
初始化模型参数w:有3D模型时,使用渲染的场景真值进行初始化,否则近似的真值进行启发式的初始化
-
优化重投影误差(相当于加入了几何约束)
-
进行端到端训练
端到端训练要求模型的所有组件都是可导的,包括位姿细化。
DSAC的位姿细化使用有限差分实现,速度慢计算量大,由于数值不稳定性,,梯度值往往很大。
DSAC++将位姿细化分为两个步骤:根据重投影误差定义inlier像素集合,然后在inlier集上根据重投影误差进行细化。
DSAC中,为了控制计算量设置了迭代次数上限和inliers数量的最大值。相比于DSAC,DSAC++的迭代数值和inliers数目是不受限的,直到优化收敛为止
Visual Camera Re-Localization from RGB and RGB-D Images Using DSAC 2021 TPAMI
针对领域:自动驾驶、增强现实
场景坐标回归 场景相关
摘要
我们描述了一个基于学习的系统,它从一个单一的输入图像相对于一个已知的环境估计相机的位置和方向。
输入图像可以是RGB-D或RGB,可以使用环境的3D模型进行训练,但不是必需的。在最小的情况下,我们的系统在训练时只需要RGB图像和地面真实位姿,在测试时只需要一个单一的RGB图像。
该框架由深度神经网络和完全可微位姿优化组成。神经网络预测所谓的场景坐标,即输入图像与环境的3D场景空间之间的密集对应。位姿优化利用可微RANSAC (DSAC)实现位姿参数的鲁棒拟合,以方便端到端训练。该系统是DSAC++的扩展,被称为DSAC*,在各种公开数据集上取得了基于RGB的再定位的最高精度,在基于RGB - D的再定位中取得了具有竞争力的精度。
引言
在这项工作中,我们描述了一个通用的、基于学习的视觉相机重定位框架。在最小情况下,它只需要一个环境的RGB图像和真实姿态的数据库进行训练,并在测试时基于单个RGB图像进行高精度的重新定位。在这样的场景中,系统在训练过程中自动发现环境的三维几何结构。如果存在场景的三维模型,无论是SfM重建还是三维扫描,我们都可以利用它来帮助训练过程。如果RGB - D传感器可用,该框架利用训练或测试时的深度信息。

我们基于肖顿等提出的场景坐标回归方法进行基于RGB - D的相机重定位。文献中的随机森林是一个可学习的函数,它将输入图像的每个像素回归到环境参考帧中相应的三维坐标。这在图像和三维场景之间诱导出一个稠密的对应场,作为基于RANSAC的位姿优化的基础。
在我们的工作中,我们将文献的随机森林替换为全卷积神经网络,并推导出位姿优化所有步骤的可微近似。最重要的是,我们推导了RANSAC鲁棒估计器的一个可微近似,称为可微样本一致性( DSAC ) 。此外,我们描述了一个有效的计算透视n点问题梯度的可微近似。这些因素使得我们的框架具有端到端的可训练性,确保神经网络预测场景坐标,从而得到高精度的相机位姿。
对DSAC*的描述:
扩展DSAC++,使其可以选择性地使用RGB-D输入。当使用RGB-D时,DSAC*可以在标准室内重新定位数据集上实现与最先进的精度相媲美的精度。
我们提出了一个简化的训练过程,它统一了DSAC++中使用的两个独立的初始化步骤。因此,在相同的硬件上,DSAC*的训练时间从6天减少到2.5天。
改进后的初始化也导致了更好的准确性。特别是在没有3D模型的训练中,室内再定位的结果从53.1% (DSAC++)提高到80.7% (DSAC*)。
引入了一种改进的网络结构进行场景坐标回归。与DSAC++的网络相比,基于ResNet[18]的架构减少了75%的内存占用。在相同的硬件上,新网络的前向传递需要50毫秒而不是150毫秒。结合更好的位姿优化参数,我们将总推理时间从DSAC++的200ms减少到DSAC*的75ms。
在新的消融研究中,我们研究了训练数据增强的影响,网络感受野的影响,以及端到端训练的影响。我们还分析了DSAC *的场景压缩特性。此外,我们提供了我们的姿态估计和网络编码的三维几何的广泛的可视化。
我们将DSAC++的实现从LUA/Torch迁移到PyTorch[19],并将其公开:https://github.com/vislearn/dsacstar
框架
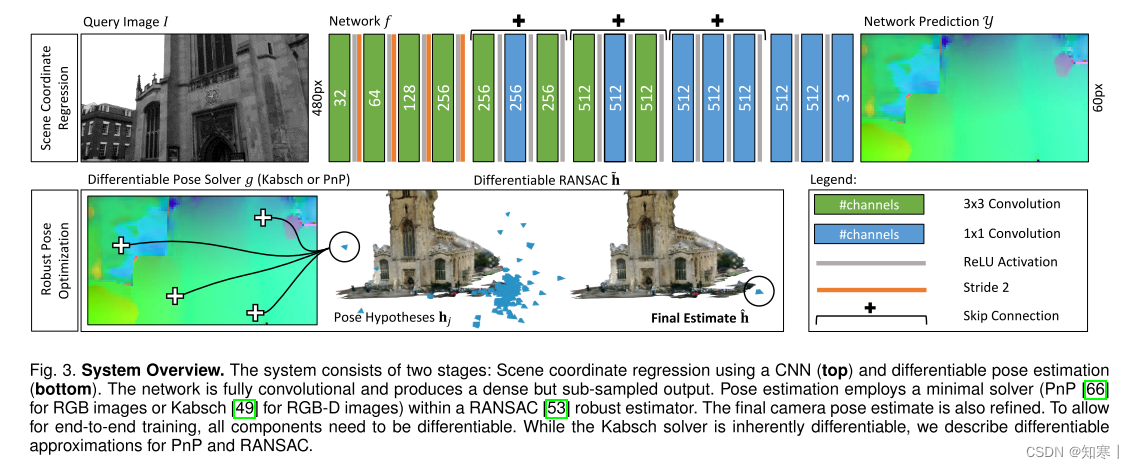
输入:给定一幅图像I,它可以是RGB或RGB- D
输出:相机的姿态参数
使用CNN的场景坐标回归(上)和可微姿态估计(下)。我们使用具有tiaoyue跳跃连接和可学习参数w的全卷积神经网络来实现场景坐标回归f(·)。该网络以单通道灰度图像作为输入,并生成密集的场景坐标预测,采样因子为8。采样是通过使用步长为2的卷积实现的,它增加了与每个像素输出相关的接受域,同时增强了效率。每个输出场景坐标的总接收域为81px。在各种数据集的实验中,我们发现提供完整的RGB图像作为输入没有任何优势,相反,转换为灰度稍微增加了对非线性光照效果的鲁棒性。
初始化网络的不同策略,这取决于那些信息可以用于训练:RGB-D、RGB + 3D Model、RGB

















 578
578

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









