







通讯作者:Carsten Rother
第一作者:Eric Brachmann
研究机构:德累斯顿工业大学,微软
代码地址:DSAC
自己的想法:
随机森林的思想在很多需要解决歧义性和多解的问题中出现,如果一个预测器没法分辨出相似的两种情况,那就训练多个预测器。
解决了RANSAC方法不可微因而无法应用到深度学习中的问题。
首先介绍下RANSAC:
该算法用于将模型拟合到一组存在噪声的数据上的任务,已经有多种RANSAC的变种被提出,这里只介绍基础版本。
- 通过对数据的最小子集进行采样来生成一组模型假设
- 基于某种相似性的量度对模型假设进行打分
- 选择分数最高的模型假设
- 使用其他数据点来优化完善所选择的模型假设
算法不可微,因此RANSAC不能参与到深度学习模型的训练过程中去。
现有的基于RANSAC的相机位姿预测方法都没有能够端到端训练的。
本文提出了两种克服RANSAC不可微的方法,其中效果较好的一种叫做DSAC。为了证明DSAC的有效性,作者将其应用到相机定位问题中,显著提升了视觉定位的精度(高出SOTA 7.3%)。
具体的,作者基于场景坐标回归森林(SCoRF)的方法 ,使用深度神经网络和DSAC对其改造,论证了DSAC的效果。
标注说明:
I 、 i I、\ i I、 i 分别表示输入图像和像素的index,
y ( I , i ) 、 y i y(I,i)、\ y_i y(I,i)、 yi均表示像素 i i i的三维坐标的预测值,
Y ( I ) 、 Y Y(I)、\ Y Y(I)、 Y均表示对图像$I $的所有像素的三维坐标的预测值。
h ~ \tilde{h} h~ 表示模型参数
模型概述:
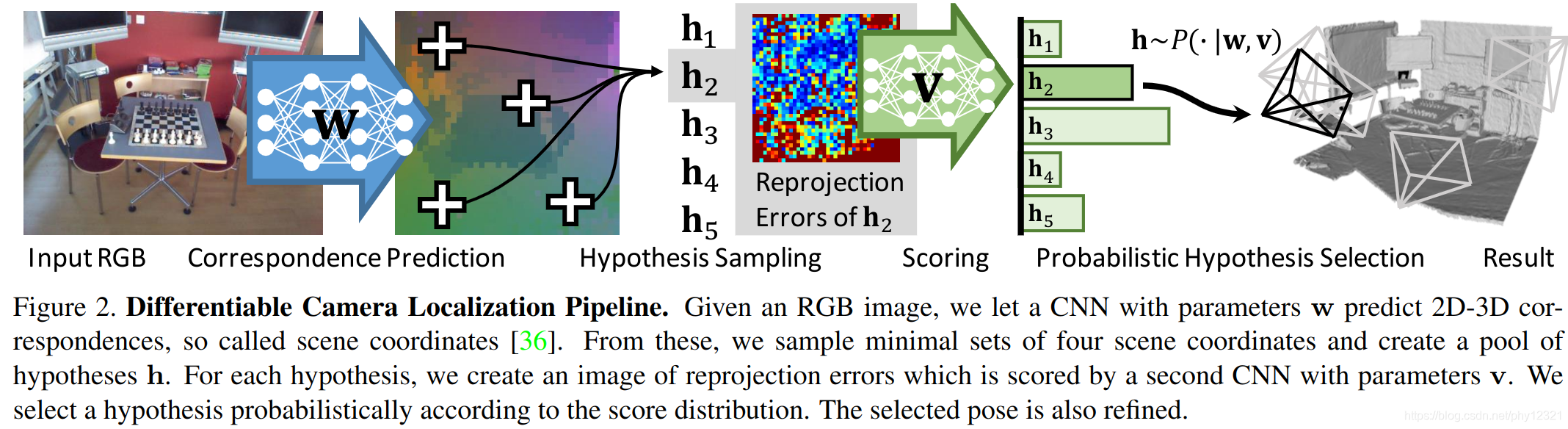
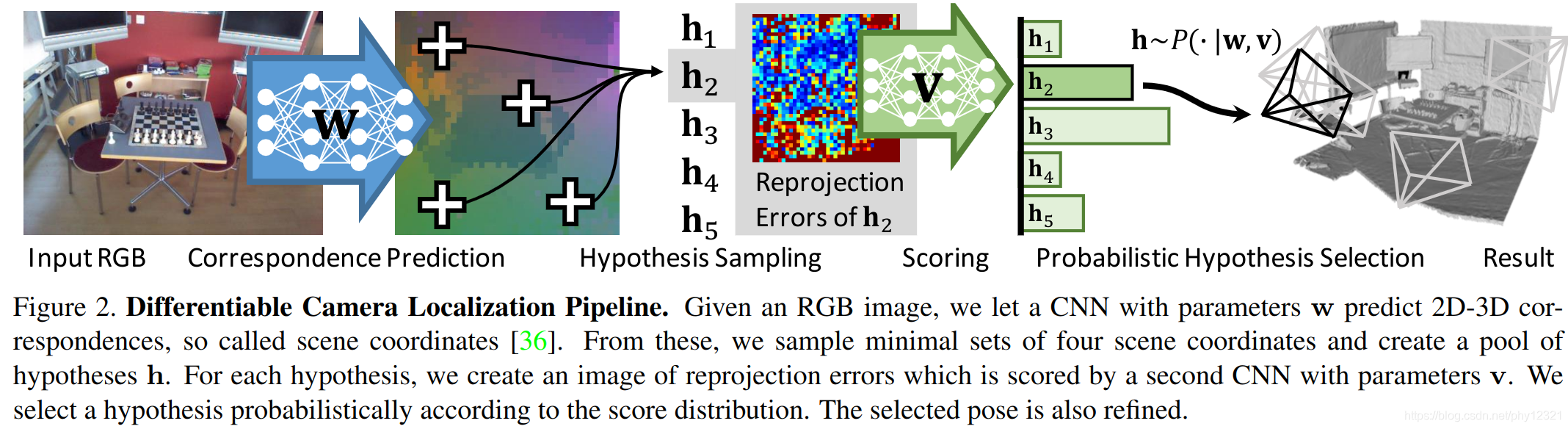
如上图,
- 首先使用W网络对输入图像进行预测,得到每一个像素点的三维坐标预测值(correspondences)。
- 每个最小坐标子集 Y J Y_J YJ包含4个correspondences(通过随机采样获得),通过PNP算法每个最小坐标子集可以得到一个模型假设。通过这种方法得到一个假设集 { h i } \{h_i\} {hi}
- 使用基于重投影误差的标量函数S对每个假设模型打分。
- 选择得分最高的一个假设模型 h A M h_{AM} hAM,使用剩余的correspondences对该最佳假说模型进行优化。
重 投 影 误 差 : e i = ‖ p i − C h J y i ‖ p i 为 像 素 i 的 坐 标 , C 是 相 机 的 投 影 矩 阵 当 重 投 影 误 差 小 于 设 定 的 阈 值 时 该 点 即 被 视 为 i n l i e r , 否 则 视 为 o u t l i e r 标 量 函 数 s ( h J , Y ) 统 计 了 假 说 h J 的 i n l i e r 数 目 作 为 打 分 数 值 重投影误差:\quad e_i=‖pi−Ch_Jy_i‖\quad pi为像素i的坐标,C是相机的投影矩阵\\当重投影误差小于设定的阈值时该点即被视为inlier,否则视为outlier\\标量函数 s(h_J,Y) 统计了假说h_J的inlier数目作为打分数值\\ 重投影误差:ei=‖pi−ChJyi‖pi为像素i的坐标,C是相机的投影矩阵当重投影误差小于设定的阈值时该点即被视为inlier,否则视为outlier标量函数s(hJ,Y)统计了假说hJ的inlier数目作为打分数值
本文方法基于前人的几篇论文:
- 论文《Scene coordinate regression forests for cam-era relocalization in rgb-d images》提出了回归森林方法,用于获得三维坐标预测 y ( I , i ) y(I,i) y(I,i)
- 论文《Learning analysis by synthesis for 6d pose estimation in rgb-d images》提出了标量函数 s ( h J , Y ) s(h_J,Y) s(hJ,Y)
但是都是分开训练的,本文的工作就是将两部分结合在一起成为一个可端到端训练的模型。
下图说明了基础的RANSAC(不可微)、基于softmax的RANSAC(可微)、DSAC三种方法的异同:
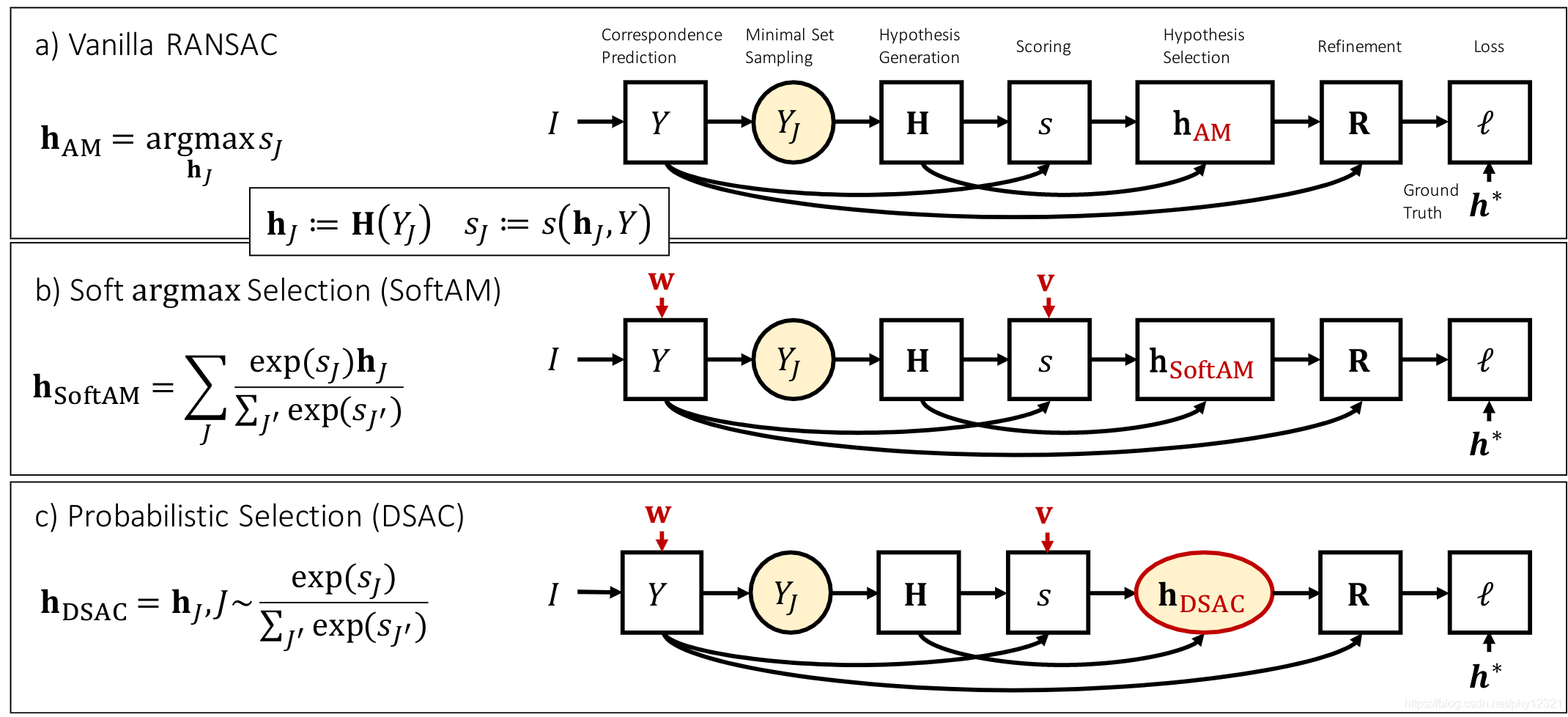
Soft argmax Selection (SoftAM):
实际上,该方法使用所有假说模型的加权和作为最终的最佳模型,避开了原始版本RANSAC需要求argmax的不可微操作:
h
S
o
f
t
A
M
w
,
v
=
∑
J
P
(
J
∣
v
,
w
)
h
J
w
w
,
v
分
别
表
示
三
维
坐
标
预
测
网
络
和
打
分
模
块
,
是
网
络
需
要
训
练
的
参
数
其
中
:
P
(
J
∣
v
,
w
)
=
e
x
p
(
s
(
h
J
w
,
Y
w
;
v
)
)
∑
J
′
e
x
p
(
s
(
h
J
′
w
Y
w
;
v
)
)
h^{w,v}_{SoftAM}=\sum_JP(J|v,w)h^w_J\\w,v分别表示三维坐标预测网络和打分模块,是网络需要训练的参数\\其中:P(J|v,w) =\frac{exp(s(h^w_J,Y^w;v))}{\sum_{J′}exp(s(h^w_{J'}Y^w;v))}
hSoftAMw,v=J∑P(J∣v,w)hJww,v分别表示三维坐标预测网络和打分模块,是网络需要训练的参数其中:P(J∣v,w)=∑J′exp(s(hJ′wYw;v))exp(s(hJw,Yw;v))
最后通过优化损失函数L得到最优参数
w
~
,
v
~
\tilde w,\tilde v
w~,v~:
w
~
,
v
~
=
a
r
g
m
i
n
w
,
v
∑
I
∈
L
L
(
R
(
h
A
M
w
,
v
,
Y
w
)
,
h
∗
)
其
中
h
∗
为
模
型
参
数
的
真
值
,
函
数
R
(
H
,
y
)
负
责
根
据
y
优
化
假
说
H
\tilde w,\tilde v= argmin_{w,v}\sum_{I\in L}L(R(h^{w,v}_{AM},Y^w),h^∗)\\其中h^*为模型参数的真值,函数R(H,y)负责根据y优化假说H
w~,v~=argminw,vI∈L∑L(R(hAMw,v,Yw),h∗)其中h∗为模型参数的真值,函数R(H,y)负责根据y优化假说H
Probabilistic Selection (DSAC):
使用概率选择的思想:
h
D
S
A
C
w
,
v
=
h
J
w
,
w
i
t
h
J
∼
P
(
J
∣
v
,
w
)
其
中
的
P
(
J
∣
v
,
w
)
与
之
前
提
到
的
相
同
h^{w,v}_{DSAC}=h^w_J,\ with \ J∼P(J|v,w)\\其中的P(J|v,w)与之前提到的相同
hDSACw,v=hJw, with J∼P(J∣v,w)其中的P(J∣v,w)与之前提到的相同
此时需要优化损失函数的期望值:
w
~
,
v
~
=
a
r
g
m
i
n
w
,
v
∑
I
∈
L
E
J
∼
P
(
J
∣
v
,
w
)
[
L
(
R
(
h
J
w
,
Y
w
)
)
]
\tilde w,\tilde v= argmin_{w,v}\sum_{I\in L}E_{J∼P(J|v,w)}[L(R(h^w_J,Y^w))]
w~,v~=argminw,vI∈L∑EJ∼P(J∣v,w)[L(R(hJw,Yw))]
计算梯度:
∂
∂
w
E
J
∼
P
(
J
∣
v
,
w
)
[
L
(
⋅
)
]
=
E
J
∼
P
(
J
∣
v
,
w
)
[
L
(
⋅
)
∂
∂
w
l
o
g
P
(
J
∣
v
,
w
)
+
∂
∂
w
L
(
⋅
)
]
\frac{∂}{∂w}E_{J∼P(J|v,w)}[L(·)] =E_{J∼P(J|v,w)}[L(·)\frac{∂}{∂w}logP(J|v,w) +\frac{∂}{∂w}L(·)]
∂w∂EJ∼P(J∣v,w)[L(⋅)]=EJ∼P(J∣v,w)[L(⋅)∂w∂logP(J∣v,w)+∂w∂L(⋅)]
Differentiable Camera Localization:
作者整体框架借鉴了论文《 Uncertainty-driven 6d pose estimation of ob-jects and scenes from a single rgb image》,不同之处在于:
- 将其中的随机森林换成了CNN用来预测三维坐标。
- 同样使用CNN来对假设模型打分
模型结构如图:


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









