







PoseNet: A Convolutional Network for Real-Time 6-DOF Camera Relocalization
结构:使用模型为GoogleNet的一个稍作修改的版本,23层(经计算有可训练参数的层),修改如下
- 用仿射回归(affine regressors)替换3个softmax分类器:移除softmax分类器,对每个最终全连接层修改以输出表示3维位置和4维方向的7维姿势向量
- 在特征尺寸为2048的最终回归器之前插入另一个完全连接的层。这是为了形成一个定位特征向量,然后可以进行泛化研究。
- 将四元数方向向量归一化为单位长度
贡献:
- 深度CNN在6自由度相机姿态定位的端到端首个应用
- 通过分类器训练网络做迁移学习,避免训练大量训练数据
- 训练可以生成姿态不变的输出,保留了足够的姿态信息
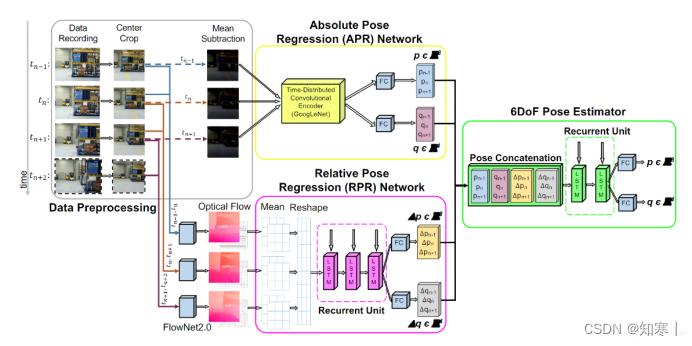
VIPR:VIsual-Odometry-aided Pose Regression for 6DoF Camera Location
在PoseNet上进行改进
- 将Posenet改进为使用三张连续图象为输入,输入对应的三个绝对位姿,作为对真实位姿的逼近
- 在此基础上使用相对位姿信息辅助预测,得到三个相对位姿
- 将三个绝对位姿和三个相对位姿连接:然后输入到一个级联LSTM中,最后得到一个精确的绝对位姿预测
模块:
- 将三个绝对位姿和三个相对位姿连接:然后输入到一个级联LSTM中,最后得到一个精确的绝对位姿预测
- APR:绝对位姿估计模块,以三张序列图像为输入,posenet-based
- RPR:相对位姿估计模块,以FlowNet2.0提取的光流信息为输入,LSTM -based
- PE:位姿估计模块,以APR、RPR的输出为输入,LSTM-based
Back to the Feature: Learning Robust Camera Localization from Pixels to Pose
PixLoc能够做到场景无关的端到端学习位姿,且能够较好地做到跨场景(室外到室内)的相机定位,着重于表征学习,不是让网络学习基本的几何关系亦或编码的3D图,而是让网络能够较好地理解几何原则以及鲁棒地应对外观以及结构变化
图像表征:对于输入的查询图像以及参考图像,利用CNN提取多尺度的特征,可以在第l∈{L,...,1}尺度上得到Dl维的特征,其中l越小尺度越小。
流程:利用已知的3D模型将query图与reference图像直接对齐对位姿进行结算,其中对齐过程中用了一种面向深度特征的非线性优化。
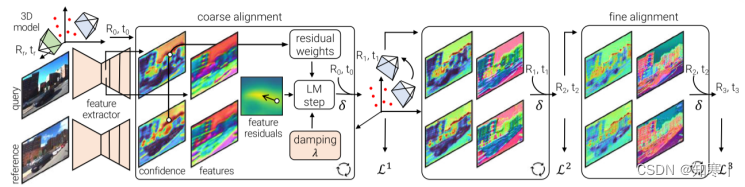
输入:稀疏3D模型(如SfM稀疏模型),粗略的初始位姿(R0,t0)(可以通过图像召回获取)
输出:查询图像对应的相机位姿
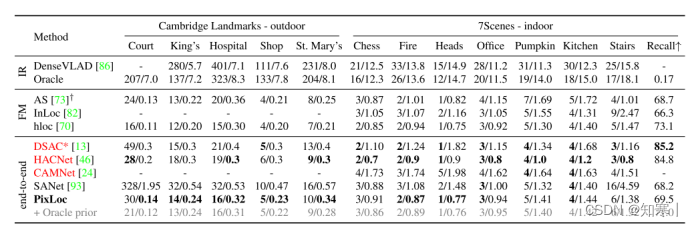
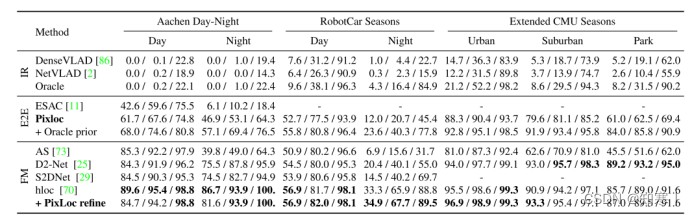
贡献:提供了一种场景无关的端到端视觉定位算法,一次模型训练,可用于多个场景的相机定位,精度较高,与目前最优的端到端的相机定位算法精度相当甚至更好
可以对相机位姿进行后处理以精化定位位
> 以上为本人初学阅读后的粗浅总结,若有错误可留言订正,希望能对初学者起到一定帮助















 1064
1064











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









