







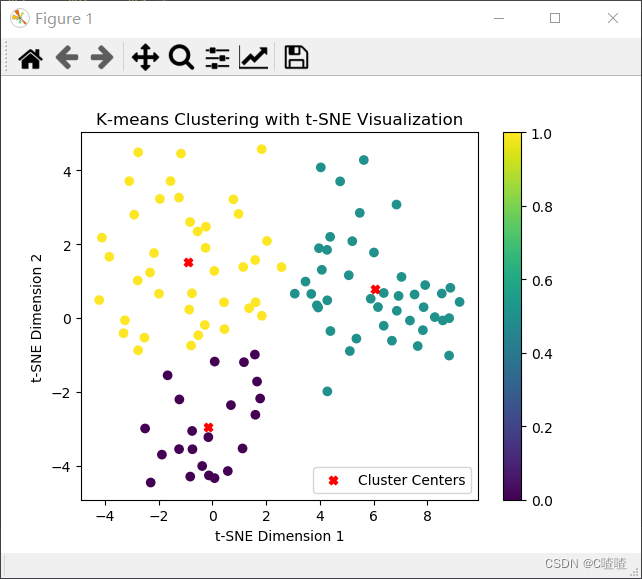
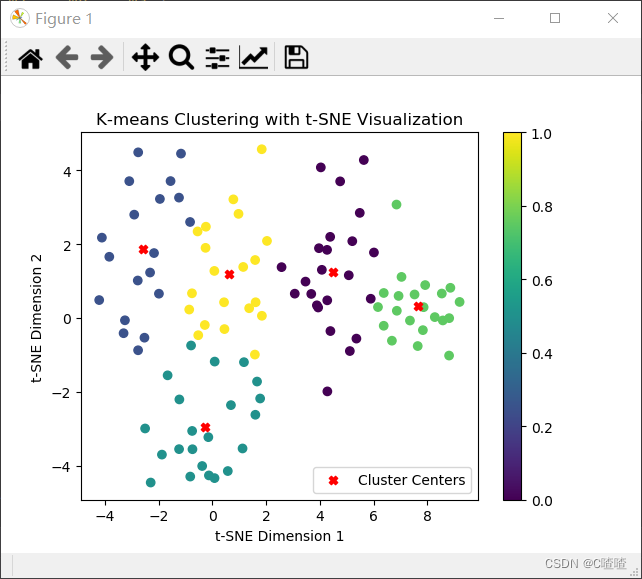
 文章展示了如何运用t-distributedStochasticNeighborEmbedding(t-SNE)方法将高维特征数据降维到二维空间,接着利用K-means算法进行聚类。之后,通过散点图将聚类结果进行可视化,用不同颜色区分不同簇,并标出聚类中心。
文章展示了如何运用t-distributedStochasticNeighborEmbedding(t-SNE)方法将高维特征数据降维到二维空间,接着利用K-means算法进行聚类。之后,通过散点图将聚类结果进行可视化,用不同颜色区分不同簇,并标出聚类中心。
首先使用t-SNE对特征数据进行非线性降维,将其转换为二维空间。
然后,使用K-means算法对降维后的数据进行聚类,并获取每个样本的聚类标签和聚类中心。
最后,使用散点图将聚类结果可视化展示出来。
文末显示画图结果。
代码如下:
import pandas as pd
import numpy as np
import matplotlib.pyplot as plt
from sklearn.manifold import TSNE
from sklearn.cluster import KMeans
# 读取数据
data = pd.read_csv('m9.csv')
# 选择要聚类的特征
features = ['特征1', '特征2', '特征3', '特征4']
X = data[features]
# 使用t-SNE进行非线性降维
tsne = TSNE(n_components=2, random_state=42)
X_tsne = tsne.fit_transform(X)
# 使用K-means进行聚类
kmeans = KMeans(n_clusters=3) # 设置聚类数量
kmeans.fit(X_tsne)
# 获取每个样本的聚类标签
labels = kmeans.labels_
# 获取聚类中心
centers = kmeans.cluster_centers_
# 绘制聚类结果
plt.scatter(X_tsne[:, 0], X_tsne[:, 1], c=labels, cmap='viridis')
plt.scatter(centers[:, 0], centers[:, 1], c='red', marker='X', label='Cluster Centers')
plt.xlabel('t-SNE Dimension 1')
plt.ylabel('t-SNE Dimension 2')
plt.title('K-means Clustering with t-SNE Visualization')
plt.legend()
plt.colorbar()
plt.show()


















 2544
2544

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











